Register CPU OptionalGetElement, OptionalHasElement on DirectML
Graphs with OptionalGetElement and OptionalHasElement should work in a
DML graph without extra memcpy operation on and off the GPU.
CopyCpuTensor is swapped with DataTransferManager.CopyTensor() to make
the CPU operator usable by other providers.
---------
Co-authored-by: Dwayne Robinson <dwayner@microsoft.com>
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Scope down a unit test case where the condition should only apply when:
1. Two streams, one GPU one CPU;
2. If node is on CPU;
3. There is a wait step before the If node.
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
Updates the default QNN SDK version to 2.10 for the QNN NuGet pipeline.
### Motivation and Context
Ensures that the daily QNN NuGet pipeline builds ORT using the latest
QNN SDK by default.
### Description
<!-- Describe your changes. -->
change the EP device to default OrtDevice() for memoryType equals
CPUInput for cuda, rocm, migraph
x and tensorRT EP
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
My previous PR (https://github.com/microsoft/onnxruntime/pull/15618)
caused random failures on cuda training test
GradientCheckerTest.TileGrad (see build
https://dev.azure.com/onnxruntime/onnxruntime/_build/results?buildId=986784&view=logs&j=5076e696-f193-5f12-2d8a-703dda41a79b&t=a3824a7c-2162-5e3d-3fdd-8cf808834fbb)
and rocm test:
root@a59558217e53:/workspace# pytest
orttraining/orttraining/test/python/orttraining_test_ortmodule_api.py::test_gradient_correctness_minmax
...
E RuntimeError: Error in backward pass execution: Non-zero status code
returned while running ATen node.
Name:'/_original_module/ATen_Grad/ATen_1' Status Message: Storage size
calculation overflowed with sizes=[72340172838076673, 72340172838076673,
128]
Potential reason is that if the memType of cuda/tensorRT/rocm/migraphx
EP is CPUInput, previously the corresponding device in the IAllocator's
memoryInfo is default OrtDevice(), while after my change, it becomes
OrtDevice(CPU, xx_PINNED, 0);
Changing it back fixed GradientCheckerTest.TileGrad in Win GPU training
build.
update ROCm/MIGraphX CI to ROC5.5.
TODO:
two PR to fix failure on
orttraining/orttraining/test/python/orttraining_test_ortmodule_api.py
-
test_gradient_correctness_minmax/test_gradient_correctness_argmax_unfold/test_gradient_correctness_argmax_diagonal
(https://github.com/microsoft/onnxruntime/pull/15903)
- test_ortmodule_attribute_name_collision_warning
(https://github.com/microsoft/onnxruntime/pull/15884)
### Description
Change BeamHypotheses to not use a stl::priority_queue and instead all
BeamHypotheses use a single buffer that they each get a small slice of.
As the beam count is really small (typically 4,8, max of 32) and the
array size fixed, the BeamHypotheses just does a sorted insert into an
array.
This also allows for the BeamHypotheses inside of the BeamSearchScorer
to be a single fixed allocation vs an onnxruntime::FastAllocVector.
### Motivation and Context
The goal is to simplify the memory usage and make the code more easily
ported to CUDA.
### Description
This PR partially reverts changes introduced in
https://github.com/microsoft/onnxruntime/pull/15643
We make two API return std::string always in UTF-8.
We also move the entry points from OrtApiBase to OrtApi to make them
versioned.
### Motivation and Context
`GetVersionString` always returns x.y.z numbers that are not subject to
internationalization.
`GetBuildInfoString` can hold international chars, but UTF-8 should be
fine to contain those.
We prefix them with u8"" in case the compiler default charset is not
UTF-8.
Furthermore, creating platform dependent APIs is discouraged.
`ORTCHAR_T` is platform dependent and was created for paths only.
On non-unix platforms would still produce `std::string` that can only
contain UTF-8
The API was introduced after the latest release, and can still be
adjusted.
Remove serialization for execution plans, will follow up with another PR
along with proper unit tests.
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
<!-- Describe your changes. -->
Use `__name__` detection in `optimize_pipeline.py`.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
It prevents unwanted execution of `main` when importing the file.
ConstantOfShape TypeTests were previously broken due to a bug where the
case for the uint64 test was being passed an int64_data_size. Changing
the data type to uint64_data_size fixes the bug.
TensorProto Int8 and Int16 tests are reenabled since they are now
passing.
### Description
Remove attention_mask from unnecessary code paths in the whisper export
process.
### Motivation and Context
Current export script frequently hits OOM error when export
whisper-large. Memory profiling shows that this is a result of
generating dummy inputs for the `encoder_attention_mask` input for a
model pass during exporting - in whisper-large, this dummy tensor can be
around 20GB in size.
`encoder_attention_mask` is ultimately a dummy input - it's just there
to satisfy certain BeamSearch requirements. Thus, we're currently
creating a 20GB tensor and passing it to the model, which then discards
the input anyways. By removing the code path to generate a dummy
encoder_mask tensor, we can reduce the memory requirements to export
whisper substantially, while keeping the BeamSearch checks satisfied.
---------
Co-authored-by: Peter McAughan <petermca@microsoft.com>
ImageScalar is an experimental operator added in ONNX 1.2.1 and removed
in ONNX 1.5 so it's no longer in use.
Changing the comment to won't fix.
---------
Co-authored-by: Dwayne Robinson <dwayner@microsoft.com>
### Description
<!-- Describe your changes. -->
Support cutlass fMHA in PackedAttention. Though we have fMHA trt kernel,
it doesn't support relative bias position. Cutlass fmha has support for
RBP and also support lower end GPUs(5.3, 6.x).
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
When building the FlatBuffers dependencies, gcc13 emits a
stringop-overflow warning. All warnings being turned into errors, that
fails the compilation of FlatBuffers, and as a consequence also fails
the build of onnxruntime.
This commit adds the application of a patch to FlatBuffers's
CMakeList.txt, to add -Wno-error=stringop-overflow to the
CMAKE_CXX_FLAGS.
### Description
The CI is extremely slow on downloading source code (~1MB/sec) so the
web CI went timeout. This is blocking the PR/checks.
Increase the timeout temporarily.
### Description
Simplify some sections of code by removing some extra gsl::span
conversions and passing parameter packs by an existing structure vs
directly.
### Motivation and Context
While stepping through the code, I noticed parts that could be
simplified. Simplifying then helped me understand it further.
By https://github.com/microsoft/onnxruntime/issues/14691, we found that
there is a mis-reuse of GPU memory between NonZero(GPU) and
Identity(GPU) which is a subgraph node in If(CPU).
The NonZero gives a GPU output consumed by Transpose(GPU), after which
that GPU output marks as free in BFCArena, and soon be reused by
Identity(GPU) in a subgraph of If(CPU).
However, NonZero(GPU) and Identity(GPU) run on separate cuda streams,
there is no synchronization because the Identity node is in a subgraph
of If(CPU). Meaning - Identity(GPU) can write to the memory when
Transpose(GPU) is reading from it.
---------
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Few minor refinements:
- Simplify ParameterOptimizerState a bit
- Use inlined containers
- Remove GetStateDict APIs]
- Re-enable cuda test for lr scheduler
Don't assume the AMX tile configuration will always remain unchanged It
is possible that other code will change the AMX tile configuration.
This change will read the current tile configuration
- if the tile is un-configured it will be configured
- if the tile is configured but does not match the expected
configuration it will be configured for the expected configuration
This resolves issues seen in unit tests when building OneDNN ep.
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Signed-off-by: George Nash <george.nash@intel.com>
### Description
this is for ort 1.15 release to work with onnx 1.14
It shall be merged after onnx 1.14 release and before ort 1.15 release.
### Motivation and Context
---------
Signed-off-by: Liqun Fu <liqfu@microsoft.com>
### Description
<!-- Describe your changes. -->
Add registration for DML RoiAlign-16 and tests for new
coordinate_transform_mode attribute. PR
[7354](https://github.com/microsoft/onnxruntime/pull/7354) is still open
to fix the CPU EP version, which is why there are skipped tests right
now. That will be completed separately so that, for now, we can
officially support opset16 with the next release.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Linnea May <linneamay@microsoft.com>
Co-authored-by: Dwayne Robinson <dwayner@microsoft.com>
### Description
Update script:
(1) change some float16 verbose logging to debug level.
(2) Let requirements-cuda.txt includes requirements.txt
(3) Use an environment variable ORT_DISABLE_TRT_FLASH_ATTENTION=1 to
avoid black image in 2.1 model. Update benchmark and doc.
(4) Update document to include command lines to build ORT rocm from
source.
(5) Update optimize_pipeline.py so that user can disable packed qkv/kv
from command line options.
(6) Update document to use torch < 2.0 for onnx export.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
- Update DML version to 1.11.0
- Disable Gemm+Softmax fusion
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
…n name to make it more intuitive.
### Description
Update Conv-Add-Relu Fusion Transformation to handle additional case
where NhwcFusedConv is present.
### Motivation and Context
Handle additional case where NhwcFusedConv is present.
### Description
allow pull debug artifacts from script
`npm run pull:wasm` - to pull release artifacts
`npm run pull:wasm:debug` - to pull debug artifacts
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
https://github.com/microsoft/onnxruntime/issues/15840
### Description
Fix bugs of Layernorm Fusion.
More checks on ReduceMean axes
separate out layernorm transform_test
### Motivation and Context
Our layernorm fusion pattern works only for axis=-1 currently.
- For training senario: The pattern produced error results directly as
they didn't handle "axes" and only assumed it's the default vaue.
- For Inference:
~~We lost some oppotunities to fuse layernrom. ~~
ReduceMean has default axes 0 which means reduce on all dimensions
**Description**:
This PR intends to enable WebNN EP in ONNX Runtime Web. It translates
the ONNX nodes by [WebNN
API](https://webmachinelearning.github.io/webnn/), which is implemented
in C++ and uses Emscripten [Embind
API](https://emscripten.org/docs/porting/connecting_cpp_and_javascript/embind.html#).
Temporarily using preferred layout **NHWC** for WebNN graph partitions
since the restriction in WebNN XNNPack backend implementation and the
ongoing
[discussion](https://github.com/webmachinelearning/webnn/issues/324) in
WebNN spec that whether WebNN should support both 'NHWC' and 'NCHW'
layouts. No WebNN native EP, only for Web.
**Motivation and Context**:
Allow ONNXRuntime Web developers to access WebNN API to benefit from
hardware acceleration.
**WebNN API Implementation Status in Chromium**:
- Tracked in Chromium issue:
[#1273291](https://bugs.chromium.org/p/chromium/issues/detail?id=1273291)
- **CPU device**: based on XNNPack backend, and had been available on
Chrome Canary M112 behind "#enable-experimental-web-platform-features"
flag for Windows and Linux platforms. Further implementation for more
ops is ongoing.
- **GPU device**: based on DML, implementation is ongoing.
**Open**:
- GitHub CI: WebNN currently is only available on Chrome Canary/Dev with
XNNPack backend for Linux and Windows. This is an open to reviewers to
help identify which GitHub CI should involved the WebNN EP and guide me
to enable it. Thanks!
### Description
Fp16 FusedConv and NhwcFusedConv. Fused Add operator should be performed
BEFORE the activation operator.
### Motivation and Context
Previous understanding of fused conv is incorrect.
### Add CPU allocation test for non-CPU devices distributed run
When CUDA EP is enabled in distributed training, CPU memory is still
used for some node output. Early we have distributed run test coverage,
but don't cover the case when some of the node are using CPU devices for
storing tensor output. As a result, I recalled we hit regression twice
in the passing months:
- https://github.com/microsoft/onnxruntime/pull/14050
- https://github.com/microsoft/onnxruntime/pull/15823
So adding this test to avoid future regressions.
The test graph looks like this:
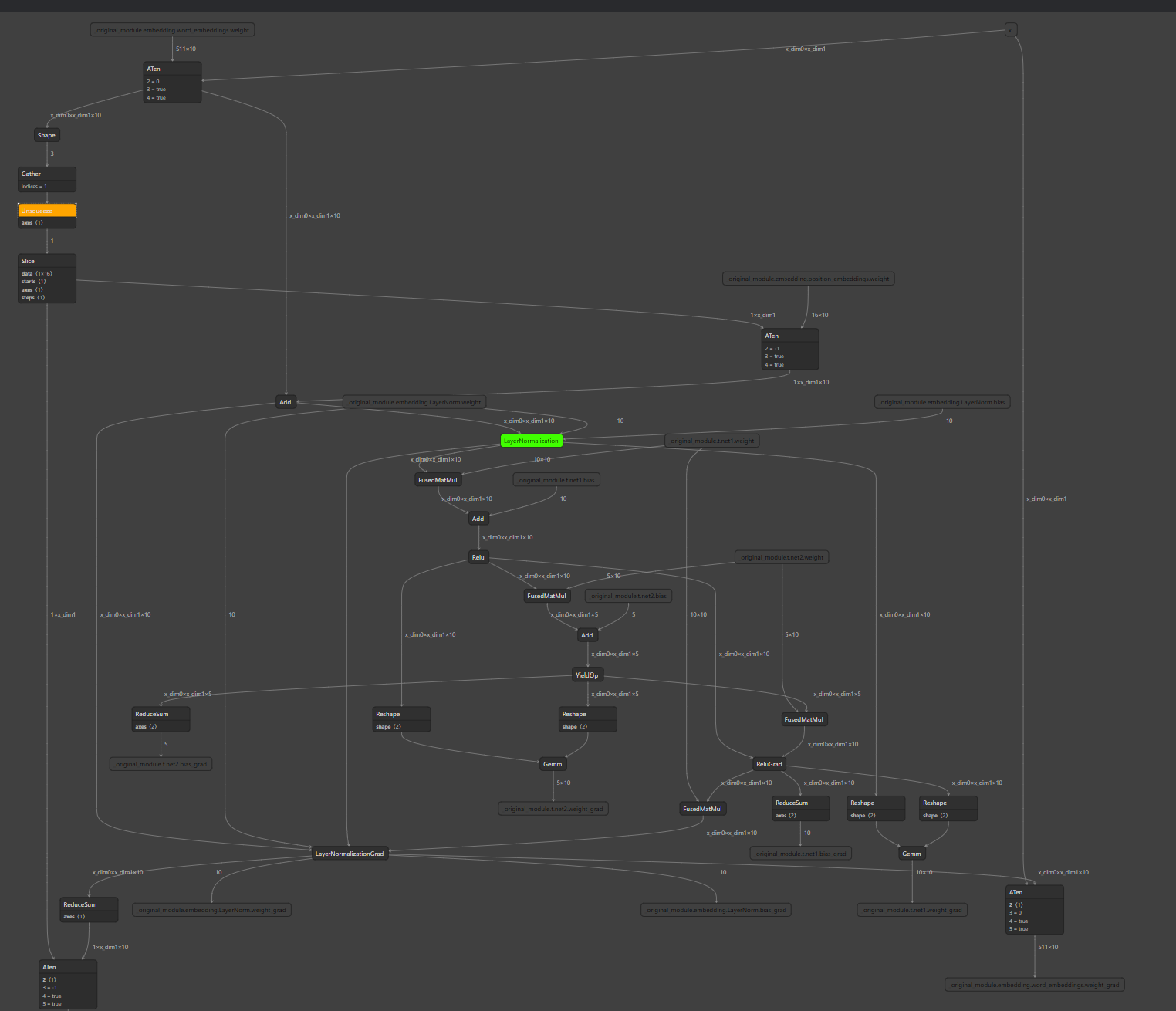
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Identified the cause for a `redefinition compilation error` happened in
a react native expo app with ort-extensions enabled when running the ios
side. Fix the include path now, so we can remove the temporary forward
declaration in OnnxruntimeModule.mm file.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Fix implementation detail.
---------
Co-authored-by: rachguo <rachguo@rachguos-Mini.attlocal.net>
### Description
When node output is optional, symbolic shape infer might add an empty
value_info item. Add some checking to avoid this.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
-
Stable diffusion optimized model reported invalid data type 0 during
inference.
### Description
Fix the bug in #15693
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
{kind=link}