mirror of
https://github.com/saymrwulf/onnxruntime.git
synced 2026-06-29 03:30:52 +00:00
Add CPU allocation test for multiple GPU distributed run (#15829)
### Add CPU allocation test for non-CPU devices distributed run When CUDA EP is enabled in distributed training, CPU memory is still used for some node output. Early we have distributed run test coverage, but don't cover the case when some of the node are using CPU devices for storing tensor output. As a result, I recalled we hit regression twice in the passing months: - https://github.com/microsoft/onnxruntime/pull/14050 - https://github.com/microsoft/onnxruntime/pull/15823 So adding this test to avoid future regressions. The test graph looks like this: 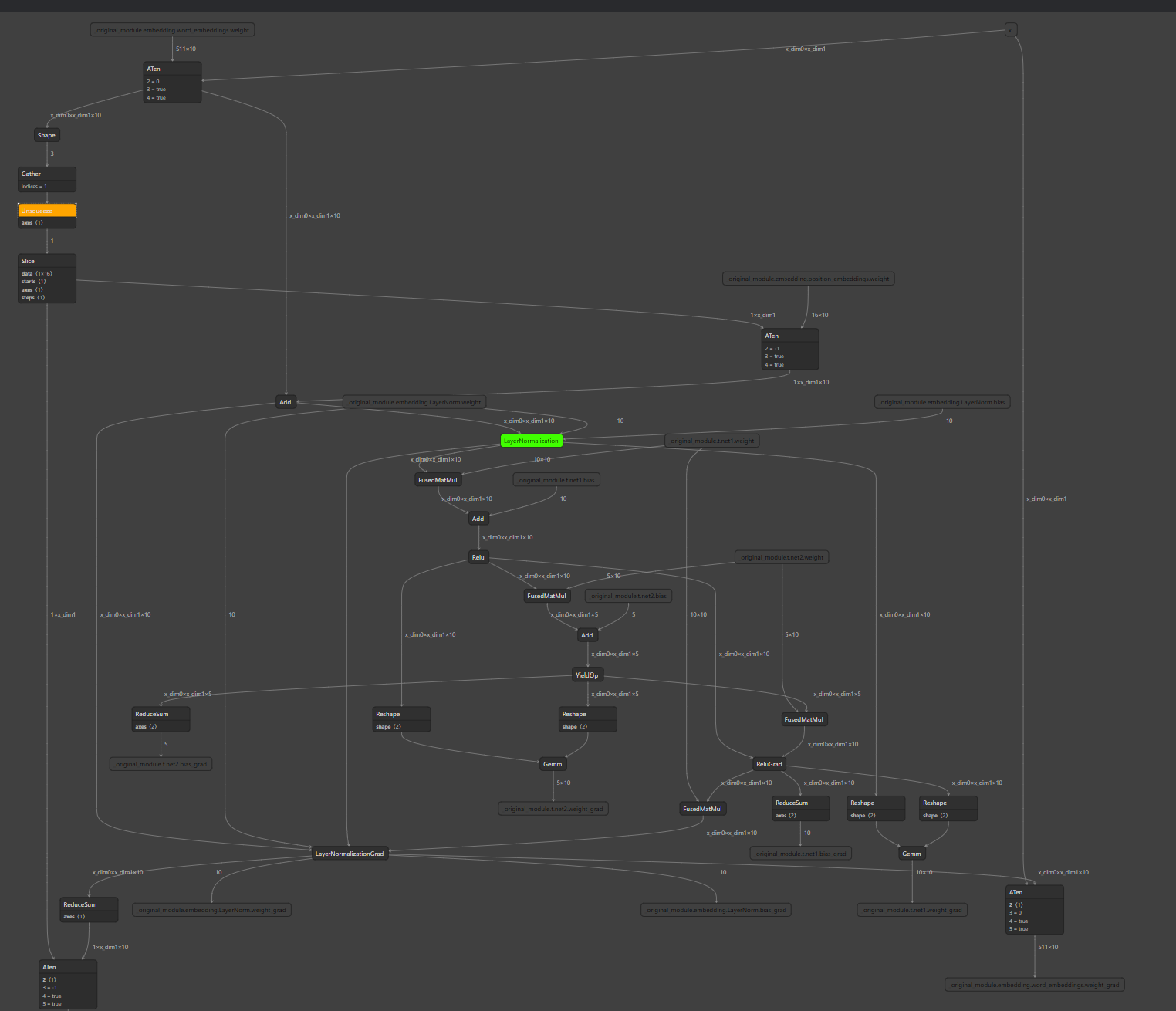 ### Motivation and Context <!-- - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. -->
{kind=link}
This commit is contained in:
parent
817d70a63b
commit
003c7d3e4d
1 changed files with 99 additions and 0 deletions
|
|
@ -146,6 +146,104 @@ def demo_checkpoint(rank, world_size, use_ort_module):
|
|||
cleanup()
|
||||
|
||||
|
||||
"""
|
||||
CustomEmbedding is adapted from
|
||||
https://github.com/huggingface/transformers/blob/312b104ff65514736c0475814fec19e47425b0b5/src/transformers/models/distilbert/modeling_distilbert.py#L91.
|
||||
"""
|
||||
|
||||
|
||||
class CustomEmbeddings(nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
vocab_size = 511
|
||||
dim = 10
|
||||
pad_token_id = 0
|
||||
max_position_embeddings = 16
|
||||
self.word_embeddings = nn.Embedding(vocab_size, dim, padding_idx=pad_token_id)
|
||||
self.position_embeddings = nn.Embedding(max_position_embeddings, dim)
|
||||
self.LayerNorm = nn.LayerNorm(dim, eps=1e-12)
|
||||
self.register_buffer("position_ids", torch.arange(max_position_embeddings).expand((1, -1)), persistent=False)
|
||||
|
||||
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
|
||||
input_embeds = self.word_embeddings(input_ids) # (bs, max_seq_length, dim)
|
||||
seq_length = input_embeds.size(1)
|
||||
position_ids = self.position_ids[:, :seq_length]
|
||||
position_embeddings = self.position_embeddings(position_ids) # (bs, max_seq_length, dim)
|
||||
|
||||
embeddings = input_embeds + position_embeddings # (bs, max_seq_length, dim)
|
||||
embeddings = self.LayerNorm(embeddings) # (bs, max_seq_length, dim)
|
||||
return embeddings
|
||||
|
||||
|
||||
"""
|
||||
This module calls `CustomEmbeddings`, which will generate a series of nodes (Shape->Gather->Unsqueeze...) whos
|
||||
allocate output tensors on CPU memory. Then this test can converge failures when CUDA EP enabled, CPU device
|
||||
allocation and usage are correct.
|
||||
"""
|
||||
|
||||
|
||||
class AnotherLayerOfToyModel(nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
self.embedding = CustomEmbeddings()
|
||||
self.t = ToyModel()
|
||||
|
||||
def forward(self, x):
|
||||
embed_val = self.embedding(x)
|
||||
return self.t(embed_val)
|
||||
|
||||
|
||||
"""
|
||||
`Mixed device allocation` here means ORT backend allocates output tensors on CPU for some nodes and
|
||||
on CUDA for other nodes. This test could help catch regression when ORT allocation planner logic got changed with bugs.
|
||||
"""
|
||||
|
||||
|
||||
def demo_mixed_device_allocation_training(rank, world_size, use_ort_module):
|
||||
torch.manual_seed(0)
|
||||
print(f"Running basic DDP example on rank {rank}.")
|
||||
setup(rank, world_size)
|
||||
device = "cuda:" + str(rank)
|
||||
|
||||
# create a model and move it to GPU with id rank
|
||||
model = AnotherLayerOfToyModel().to(device)
|
||||
if use_ort_module:
|
||||
model = ORTModule(model)
|
||||
print(f" Rank {rank} uses ORTModule.")
|
||||
else:
|
||||
print(f" Rank {rank} uses Pytorch's nn.Module.")
|
||||
|
||||
ddp_model = DDP(model, device_ids=[device])
|
||||
|
||||
loss_fn = nn.MSELoss()
|
||||
optimizer = optim.Adagrad(ddp_model.parameters(), lr=0.01)
|
||||
|
||||
batch = 2
|
||||
max_seq_length = 16
|
||||
x = torch.randint(1, 511, (batch, max_seq_length)).to(device)
|
||||
y = torch.randn(batch, max_seq_length, 5).to(device)
|
||||
|
||||
loss_history = []
|
||||
|
||||
for i in range(5):
|
||||
optimizer.zero_grad()
|
||||
p = ddp_model(x)
|
||||
loss = loss_fn(p, y)
|
||||
with torch.no_grad():
|
||||
print(f" Rank {rank} at iteration {i} has loss {loss}.")
|
||||
loss.backward()
|
||||
optimizer.step()
|
||||
with torch.no_grad():
|
||||
loss_history.append(torch.unsqueeze(loss, 0))
|
||||
|
||||
loss_history = torch.cat(loss_history).cpu()
|
||||
expected_loss_history = torch.FloatTensor([1.1589857340, 1.0975260735, 1.0628030300, 1.0386666059, 1.0196533203])
|
||||
|
||||
assert torch.allclose(expected_loss_history, loss_history)
|
||||
|
||||
cleanup()
|
||||
|
||||
|
||||
def run_demo(demo_fn, world_size, use_ort_module):
|
||||
mp.spawn(demo_fn, args=(world_size, use_ort_module), nprocs=world_size, join=True)
|
||||
|
||||
|
|
@ -160,3 +258,4 @@ if __name__ == "__main__":
|
|||
args = parse_args()
|
||||
run_demo(demo_basic, 4, args.use_ort_module)
|
||||
run_demo(demo_checkpoint, 4, args.use_ort_module)
|
||||
run_demo(demo_mixed_device_allocation_training, 4, args.use_ort_module)
|
||||
|
|
|
|||
Loading…
Reference in a new issue