Optimize top 1 computation in greedysearch.
For vocabulary size 50k on A100,
- batch size 1: from 220us to 10.4us.
- batch size 4, from 230us to 11.5us.
For generation of 50 tokens for example, it saves 50*0.2ms = 10ms.
### Description
To Implement Resize 18.
This PR depends on https://github.com/microsoft/onnxruntime/pull/13765.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Completing some missing parts of some test cases for python bindings
### Motivation and Context
Some test cases like test_training_module_checkpoint and test_optimizer
step were not completed before because we had no access to parameters to
check if the parameters are changing after the optimizer step or that
the checkpoint saved parameters remains the same.
now that we have access to the vector or parameters by exposing
get_contiguous_parameters() method.
we can complete the tests.
### Description
<!-- Describe your changes. -->
Bug fixed: Quantized models cannot be loaded into ort.InferenceSession
when DedicatedQDQPair is True in extra_options of QDQQuantizer.
Solutions: Add postfix to node names of dedicated QDQ pairs similar to
tensor names of them.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Loading quantized model fails when setting `DedicatedQDQPair` to `True`
in `extra_options` and raise an error as below:
```
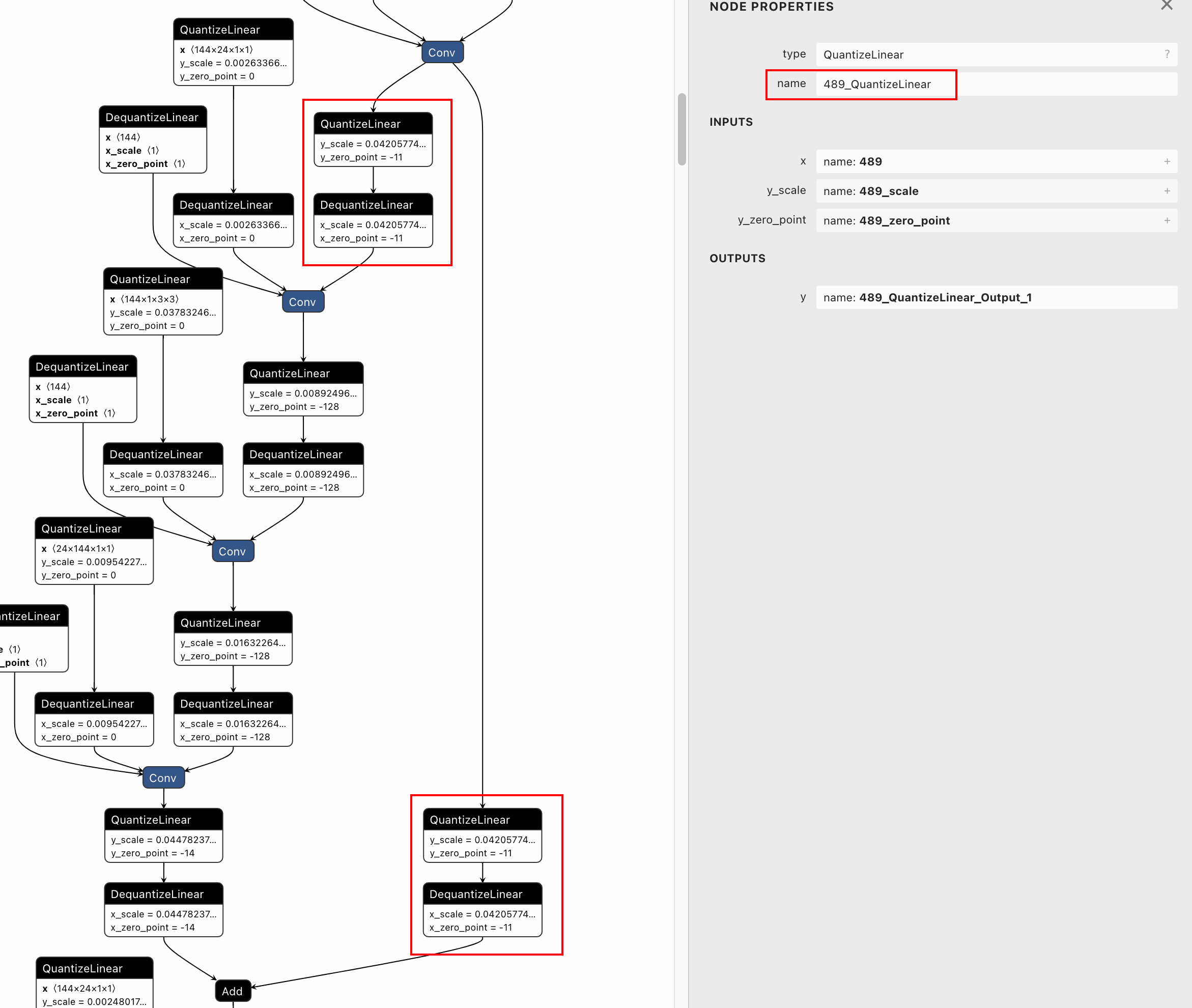
Fail: [ONNXRuntimeError] : 1 : FAIL : Load model from mobilenetv2-opset10-quantized-dedicated.onnx failed:This is an invalid model. Error: two nodes with same node name (489_QuantizeLinear).
```
After visualizing the quantized model using netron, we can find that
both the dedicated QDQ pairs for tensor 489 have the same node names of
"489_QuantizeLinear". So I found that in QDQQuantizer, there is no
unique postfix for the node names of dedicated QDQ pairs.
<img width="1171" alt="image"
src="https://user-images.githubusercontent.com/12782861/212010296-f8cc05ce-c20e-4189-a692-aaf4bbac3a29.png">
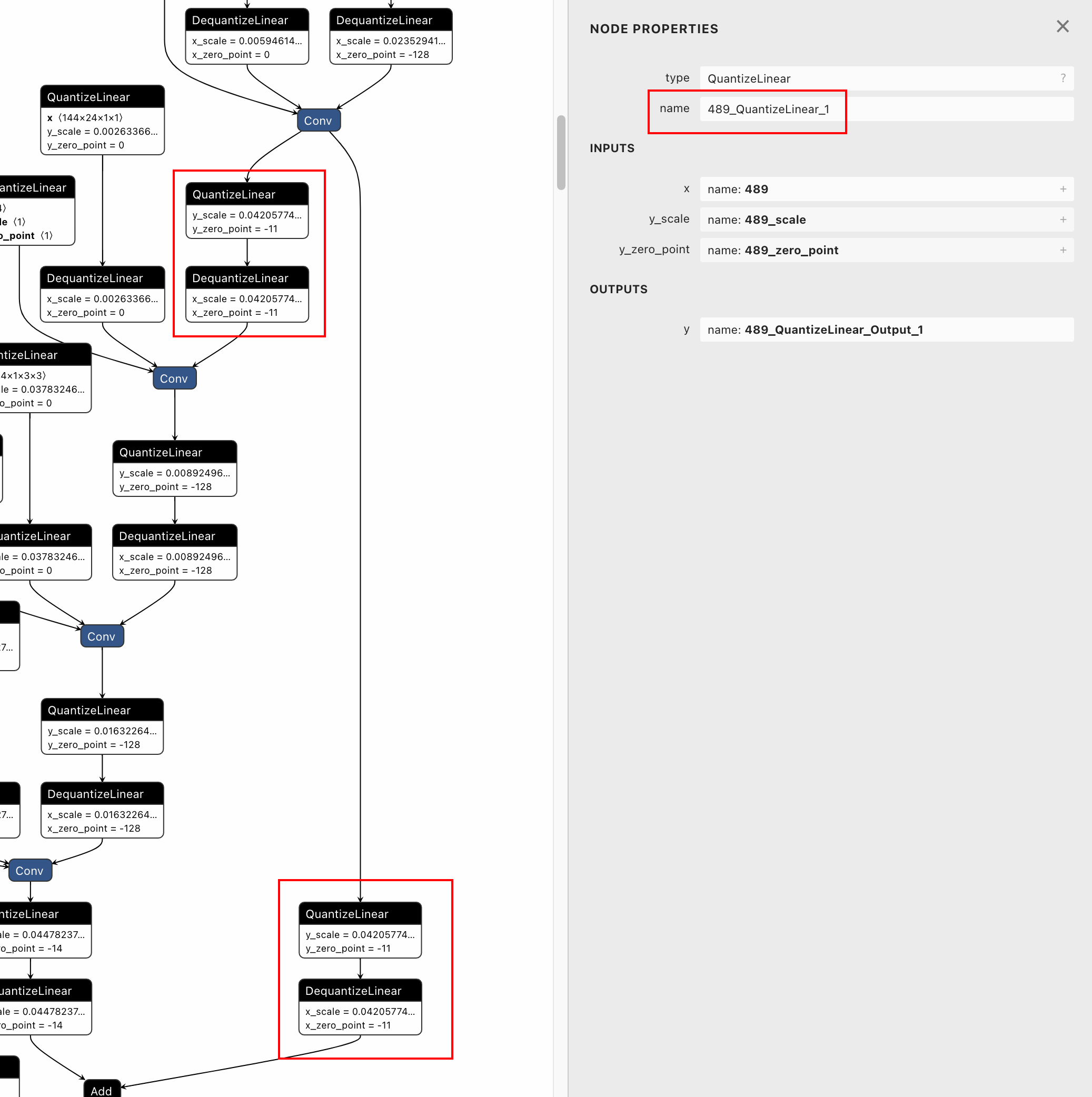
Therefore, I add postfix to node names of QDQ pairs similar to doing so
to tensor names. After this modification, the quantized model can be
loaded successfully and dedicated QDQ pairs have different node names.👌🏻
<img width="1037" alt="image"
src="https://user-images.githubusercontent.com/12782861/212010594-78eba39d-eab6-4d77-9ecd-b55f5303bcf4.png">
Description
Add bindings for Android and iOS.
Motivation and Context
Enable mobile app linking against ort-extensions library and registering the custom ops with ORT.
### Description
If the number of trees is >= 100 and batch size >= 2000, the
parallelization by tree becomes slower than the parallelization by rows.
However, by applying the parallelization by trees over smaller chunks of
data, it is still better than the parallelization by rows. The following
script was used to measure the performance
[plot_gexternal_lightgbm_reg_per.zip](https://github.com/microsoft/onnxruntime/files/10149092/plot_gexternal_lightgbm_reg_per.zip)
with different thresholds. The graph were produced by the script
following the graph.
* //N means parallelization by rows
* //T means parallelization by trees
* //T-128 means parallelization by trees every batch of 128 rows.
* //T-1024 means parallelization by trees every batch of 1024 rows.
The following graphs shows that the parallelization by trees is better
than the parallelization by rows on small batches only. It is also
better to split the input tensor by chunks of 128 rows and parallelize
by trees on every chunk of 128 rows. The proposed changes implements
that optimization.
It applies the same idea even when there is only one thread. It also
makes sure one thread is used when the user only wants one.

```python
import pandas
import matplotlib.pyplot as plt
filenames = [
("//N",r"plot_gexternal_lightgbm_reg_per_N.csv"),
("//T", "plot_gexternal_lightgbm_reg_per_T.csv"),
("//T-128", "plot_gexternal_lightgbm_reg_per_128.csv"),
("//T-1024", "plot_gexternal_lightgbm_reg_per_1024.csv"),
]
dfs = []
for name, filename in filenames:
df = pandas.read_csv(filename)
for c in df.columns:
if "batch" in c:
df[f"-{name}-{c}"] = df[c]
dfs.append(df)
df = dfs[0][["N"]].copy()
for _df in dfs:
for c in _df.columns:
if c[0] == "-":
df[c] = _df[c].copy()
fig, ax = plt.subplots(1, 3, figsize=(14, 6))
Ts = [50, 500, 2000]
ga = df.set_index("N")
for i, nt in enumerate(Ts):
cs = [c for c in ga.columns if c.endswith(f"-{nt}")]
ga[cs].plot(ax=ax[i], title=f"Trees={nt}", logy=True, logx=True)
```
Below the performance gain for the monothread implementation by looping
on data in the inner loop.

### Motivation and Context
Performance.
Signed-off-by: xadupre <xadupre@microsoft.com>
### Description
Use pytest-xdist to distribute tests across multiple CPUs to speed up
test execution.
Use pytest-rerunfailures to rerun failed test in case of pytest-xdist
crash.
`pytest -n 16` can reduce pytest time from 80 minutes to 20 minutes.
### Motivation and Context
Now kernel explorer pytest of ROCm CI takes nearly 1 hour 20 minutes. It
will take longer time when we add more tunableOp in the future.
### Description
<!-- Describe your changes. -->
Change tolerance for tests involving MNIST and cuda to try and fix flaky
CI tests.
Errors from CI:
ModelTests/ModelTest.Run/cuda__models_zoo_opset8_MNIST_model
expected 4.0755 (40826a83), got 4.06948 (40823938), diff: 0.00601721,
tol=0.0050755 idx=4. 2 of 10 differ
ModelTests/ModelTest.Run/cuda__models_zoo_opset7_MNIST_model
expected 7.89851 (40fcc09e), got 7.88879 (40fc70f8), diff: 0.00972271,
tol=0.00889851 idx=4. 4 of 10 differ
ModelTests/ModelTest.Run/cuda__models_zoo_opset12_MNIST12_mnist12
expected -5.50068 (c0b00595), got -5.49023 (c0afaff0), diff: 0.0104547,
tol=0.00650068 idx=1. 1 of 10 differ
Use rtol of 1e-2 if cuda is enabled. Use same for openvino for
simplicity.
```
>>> expected = np.array([4.0755, 7.89851, -5.50068], dtype=np.float32)
>>> actual = np.array([4.06948, 7.88879, -5.49023], dtype=np.float32)
>>> np.isclose(expected, actual, rtol=1e-2, atol=1e-3)
array([ True, True, True])
```
Whitespace changes are from clang-format.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
CI fails semi-frequently causing unnecessary re-runs.
### Description
Right now prepacking code is not compiled when training is enabled. Our
partners want a single build of ort which can do both optimized
inference + training on device. This PR enables prepacking code in a
training build and controls whether it is enabled or not using already
existing session option - kOrtSessionOptionsConfigDisablePrepacking
For Inference scenarios - prepacking will be turned on by default and
this behavior remains the same after this PR too.
For training scenarios - prepacking will be disabled by default and if
user explicitly enables it then an error will be thrown.
### Motivation and Context
Enable both optimized inference as well as on device training in a
single build. For on device training use flag --enable_training_apis.
### Description
<!-- Describe your changes. -->
Skip tests for opset18 models that we haven't implemented kernels for
yet.
Slice was checked in today so those failures should go away.
Resize: #13890 (all resize failures are fixed by this PR as confirmed in
output
[here](https://dev.azure.com/aiinfra/530acbc4-21bc-487d-8cd8-348ff451d2ff/_apis/build/builds/264725/logs/729))
Col2Im: #12311
ScatterND and ScatterElement: #14224
Pad (should also fix CenterCropPad failures): #14219 Bitwise ops: #14197
Optional: Unknown if we're intending to support this in 1.14
Not sure about SoftPlus as that is failing due to `Could not find an
implementation for Exp(1)`. ORT supports Exp from opset 6 and on, and it
seems incorrect for the test model created for opset 18 to be using a
version of Exp that is so old. Would have expected it to use the latest
- Exp(13). @liqunfu is this something that requires a fix to the ONNX
model?
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Fix pipeline
### Description
<!-- Describe your changes. -->
1. add an optional input to pass in seed
2. two UTs. one for top_p=0.5, another for top_p=0.01(create greedy
search result, in convert_generation.py)
3. fix a bug in cpu kernel
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
This PR registers ScatterND-16 to the DML EP
- CPU fallback is added if the reduction attribute is in use, as this is
not yet supported by DML.
Co-authored-by: Numfor Mbiziwo-Tiapo <numform@microsoft.com>
### Description
Data processing capabilities to ORT Web.
This PR will focus augmenting raw data to and from Tensors.
### Motivation and Context
Enabling different app building use cases to leverage ORT in a more
natural form.
Currently, the user needs to process the data and call Tensor
constructors - these util functions will provide a direct path to
generating ORT tensors.
Co-authored-by: shalvamist <shalva.mist@microsoft.com>
### Description
Add FusedMatMul
### Motivation and Context
- Add the FusedMatMul fusion for DML
- Fix the FusedMatMul logic and tests when transposed batches are
involved
### Description
<!-- Describe your changes. -->
Use dlsym/GetProcAddress to lookup a custom ops registration function by
name and call it.
This will be better on mobile platforms where the custom ops library is
linked against, and there isn't necessarily a filesystem that a library
path can be loaded from.
Alternative is to wire up passing in the address of the function, but
that has multiple complications which differ by platform.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Enable using ort and ort-ext packages on mobile platforms.
Co-authored-by: Edward Chen <18449977+edgchen1@users.noreply.github.com>
### Description
Changes to incorporate OpenVINO EP 2022.3
### Motivation and Context
This change is required to incorportate OpenVINO EP 2022.3
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: mohsinmx <mohsinx.mohammad@intel.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
Co-authored-by: Aravind <aravindx.gunda@intel.com>
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: flexci <mohsinmx>
### Description
<!-- Describe your changes. -->
Opset 18 Split changes. Adds ability to specify num_outputs which also
allows uneven splitting.
https://github.com/onnx/onnx/releases/tag/v1.13.0
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Support ONNX opset 18.
Add an option --use_multi_head_attention to fuse model with
MultiHeadAttention operator instead of Attention operator for testing
purpose.
Note that MultiHeadAttention can be used in self-attention and
cross-attention, while Attention operator is used for self-attention
only. In Attention operator, there is packed Q/K/V weights for input
projection, but that MatMul of input projection is excluded from
MultiHeadAttention.
Fix https://github.com/microsoft/onnxruntime/issues/14017.
Before: shape_value = np.asarray([0, 0, np.array([4]), np.array([8])],
dtype=np.int64) raise Error in numpy 1.24.
After: shape_value = np.asarray([0, 0, 4, 8)], dtype=np.int64) is good
in numpy 1.24.
Update test environment to use numpy 1.24.
### Description
Fix FusedMatMul crash when batch > 1
### Motivation and Context
FusedMatMul calls `SetStrides` on its input tensors but doesn't update
the tensorSizeInBytes value. Calling `SetStrides` is very error-prone
because it puts the tensor in an invalid state, and the caller needs to
manually adjust it after the call. To avoid this situation in the
future, we now update the size of the tensor in the `SetStrides` call
itself.
Use json format to save and load partition config, previously it was
csv, which brought issues among windows and posix due to different line
breaks.
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
Improve TopP sampling's filter kernel with cub::scan. It reduces TopP
sampling latency from 3.67 to 0.92 for batch size 8 and vocabulary size
51k.
### Description
Enable creating dedicated build for on device training. With this PR we
can build a lean binary for on device training using flag
--enable_training_apis. This binary includes only the essentials like
training ops, optimizers etc and NOT features like Aten fallback,
strided tensors, gradient builders etc . This binary also removes all
the deprecated components like training::TrainingSession and OrtTrainer
etc
### Motivation and Context
This enables our partners to create a lean binary for on device
training.
### Description
<!-- Describe your changes. -->
rename the CrossAttention to MultiheadAttention since this op can also
be used as self attention
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
This PR Registers Identity-16 to the DML EP.
ONNX Backend tests and optional type tests were skipped pending future
additions.
Co-authored-by: Numfor Mbiziwo-Tiapo <numform@microsoft.com>
### Description
Hot fix python packaging pipeline failures by disabling an attention op
test which causes cl crashes in prefast build.
Verified that python package is good with this hot fix:
https://aiinfra.visualstudio.com/Lotus/_build/results?buildId=263786&view=results
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Failed in prefast build that linker crashes:
```
cl : command line error D8040: error creating or communicating with child process
```
The cause is high stack usage in an attention op unit test introduced in
https://github.com/microsoft/onnxruntime/pull/13953.
### Description
Uses a local copy of murmurhash3 in TensorRT.
### Motivation and Context
The current murmurhash3 implementation is located in core/framework,
which is not linked to the provider shared library. This causes a
segfault when tensorrt shared library is used standalone.
### Description
Add protected destructor so that any inherited classes can't
accidentally be deleted through a pointer to the base.
Fixes this prefast warning:
The type 'struct onnxruntime::CUDA_Provider' with a virtual function
needs either public virtual or protected non-virtual destructor (c.35).
Internal bug 8999
### Description
Fairly self explanatory. Someone pointed out we could miss some
exceptions, and we never want to throw exceptions through the C API.
### Motivation and Context
This doesn't fix any known issue, it's just a good idea to have.
### Description
Update the MIGraphX version used in ORT to rocm-5.4.0
### Motivation and Context
The previous branch migraphx_for_ort has stopped updating, it is too far
away from the MIgraphX latest release branch. More discussion here:
https://github.com/microsoft/onnxruntime/issues/14126#issuecomment-1373201049
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
1. Set the WithCache default value as false in Mac OS CI workflow too.
2. Add date of today in cache key to avoid cache size keep increasing
too.
WithCache, the pipeline duration reduced from 70 more minutes to 10 more
minutes
### Description
Fix unconnected node removal logic
### Motivation and Context
The edges need to be removed before the nodes themselves, otherwise the
indices will reference the wrong nodes.
### Description
DML EP was using very old feature level (2.0) which may lead to model
(having latest operator) execution failure, if model is running against
old DirectML.dll.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
{kind=link}
{kind=link}
{kind=link}
{kind=link}