### Description
<!-- Describe your changes. -->
* Add aggregated op-kernel correlation information in profiler explorer
when running inference session.
* Add filtering feature so that we can focus on model runs of interest
(excluding warmup steps, etc.)
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
This PR adds an implementation of the `Squeeze` operator to WebGPU JSEP.
The implementation follows the [operator
schema](https://github.com/onnx/onnx/blob/main/docs/Operators.md#Squeeze)
and allows one or two inputs.
### How was it tested
1. I created two models. Without `axes`:
```Python
import onnx.helper
node = onnx.helper.make_node(
"Squeeze",
inputs=["T"],
outputs=["y"],
)
graph = onnx.helper.make_graph([node], "test", [onnx.helper.make_tensor_value_info("T", 1, [3, 1, 4, 5])],
[onnx.helper.make_tensor_value_info("y", 1, [3, 4, 5])])
onnx.save(onnx.helper.make_model(graph), "squeeze.onnx")
```
And with `axes`:
```Python
import onnx.helper
node = onnx.helper.make_node(
"Squeeze",
inputs=["T", "axes"],
outputs=["y"],
)
graph = onnx.helper.make_graph([node], "test", [onnx.helper.make_tensor_value_info("T", 1, [3, 1, 4, 5]), onnx.helper.make_tensor_value_info("axes", 7, [1])], [onnx.helper.make_tensor_value_info("y", 1, [3, 4, 5])])
onnx.save(onnx.helper.make_model(graph), "squeeze-dim.onnx")
```
2. I compiled the runtime using @fs-eire's
[instructions](https://gist.github.com/fs-eire/a55b2c7e10a6864b9602c279b8b75dce).
3. I ran the test models in the browser using this minimal setup:
```HTML
<html>
<script src=".\dist\ort.webgpu.min.js"></script>
<script>
async function run() {
const session = await ort.InferenceSession.create('squeeze-dim.onnx', {executionProviders: ['webgpu']});
console.log(session);
const input = new ort.Tensor('float32', new Float32Array(60), [3, 1, 4, 5]);
const dim = new ort.Tensor('int64', [-3n], [1]);
const output = await session.run({ "T": input, "axes": dim });
console.log(output);
}
run();
</script>
</html>
```
### Motivation and Context
Improve operator coverage for WebGPU JSEP.
### Description
<!-- Describe your changes. -->
Add 2 new QNN CIs to tools/python/run_CIs_for_external_pr.py
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Update tool so it runs all current CIs
This addresses a DML performance regression introduced by the constant
sharing pass.
The constant sharing pass identifies small initializer tensors which
contain identical values and merges them. This could have the effect of
causing DML to treat those tensors as non-constant and skip certain
optimization.
To prevent this, there is now an element count threshold below which the
DML EP will enable this optimization, even though it results in
duplicate work uploading and pre-processing the common tensor at
multiple operators.
### Description
The file include/onnxruntime/core/providers/cuda/cuda_provider_options.h
is a C++ file. It is not for C.
Before this commit, this header file is already not compatible with C compilers. Because it has:
```
onnxruntime::ArenaExtendStrategy arena_extend_strategy;
```
And this file is intended to be internal only. It is an internal header file. It should not be included in onnxruntime_c_api.h and should not be used with the public C APIs. User can only get the instance of OrtCUDAProviderOptionsV2 via CreateCUDAProviderOptions. In such a way we can add new members to this struct without breaking binary compatibility.
Since it is an internal header, we can safely use C++ grammar there.
### Description
ExecutionProvider API refactor - Detach allocator from EP by creating
local cpu allocator instead
### Motivation and Context
This is PR is a refactor to create local CPU allocator instead of
getting allocator from ExecutionProvider, which the final goal is to
totally detach allocators from ExecutionProvider, and put them in
session level indexed by OrtDevice
### Description
Use an assembly instruction to read the `AA64ISAR0_EL1` register for dot
product support.
### Motivation and Context
The only reliable way to check for supported instruction extensions in
ARM is to
query the instruction set attribute registers. [Dot product instructions
can
be checked using bits 47:44 in the AA64ISAR0_EL1
register](https://developer.arm.com/documentation/ddi0601/2021-12/AArch64-Registers/ID-AA64ISAR0-EL1--AArch64-Instruction-Set-Attribute-Register-0?lang=en#fieldset_0-47_44).
On `qemu-aarch64` with the `a64fx` cpu which does not support the dot
product
instructions, running a quantized BERT-Large (from MLPerf) results in
`SIGILL`.
With the change, the program continues without using the dot product
instructions. Also verified that `S8S8_SDOT` kernels are invoked when
running
on hardware that supports dot product instructions.
---------
Co-authored-by: Skand Hurkat <skhurkat@microsoft.com>
Add a configuration `max_power_of_two_extend_bytes ` to limit the arena extension size.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
In our real scenario, we observe that if the model is big enough the
BfcArena will extend uncontrollable.
As showed by the following figures, if a model uses more than 16GB
memory, the BfcArena will totally apply for 32GB memory according to the
`kNextPowerOfTwo` strategy. With the new strategy, the extension is
limited. The default maximum extension size is 1GB.
#### Without the new configuration
After loading the model, ORT uses 32G GPU memory.

#### With the new configuration
After loading the model, ORT uses 23G GPU memory.

Co-authored-by: Yuhong Guo <yuhong.gyh@antgroup.com>
1. Cherry-pick #16054 back to the main branch
2. Replace onnxruntime-gpu-winbuild-t4 with onnxruntime-Win2022-GPU-T4.
The later one has VS2022.
---------
Co-authored-by: Patrice Vignola <vignola.patrice@gmail.com>
### Description
Fix an error in test/shared_lib/test_inference.cc. It should use
ASSERT_NEAR to test float values.
### Motivation and Context
Our OpenVino pipeline is failing because of this.
### Type hint for ORTModule
Add Type hint for ORTModule
Refine comments.
The reason of removing theinterface execution_session_run_forward from
`orttraining/orttraining/python/training/ortmodule/_graph_execution_manager.py`:
PR
cc275e7529 (diff-497e18dc8878818205b81fd80f85942548d8aa15d0f1204ce3e3d9795e3dd195)
and some commit before it breaks the function interface contracts
between parent calss _graph_execution_manager.py and its children
_training_manager.py and _inference_manager.py. So there is no need to
have this interface.
### Other EE work opportunities
1. Use logger correctly.
2. Remove few duplication logic parsing input/output recursively.
3. Clean up environment variable usage.
### Description
DML_PACKAGE_DIR cmake variable is not getting set properly when dml_path
build options is used.
### Motivation and Context
- Why is this change required? What problem does it solve?
It is required for DML Perf dashboard.
<!--- If it fixes an open issue, please link to the issue here. -->
### Description
Avoid trt deprecated api warnings shown as errors when building
onnxruntime_test_all
This issue is only visible when installing trt via binaries, rather than
deb/rpm pkg (CI pipelines)
The change is similar to existing set_property for
onnxruntime_providers_tensorrt
89ea503024/cmake/onnxruntime_providers.cmake (L421)
### Motivation and Context
onnxruntime/test/unittest_main/[test_main.cc](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/test/unittest_main/test_main.cc#L32)
includes nvinfer.h, which includes deprecated trt apis and and generates
warnings.
When building onnxruntime_test_all, it will show warnings as errors and
block the build.
### Doubts
Although this issue is visible on trt tar binaries but not on trt
deb/rpm pkgs,
Their file size&hash are the same (creation time vary), regarding
headers/libs installing in different ways.
| tarBin | pkg |
| ------------------------------------------------------------ |
------------------------------------------------------------ |
| 997284784 Apr 26 15:15 libnvinfer_builder_resource.so.8.6.1 |
997284784 Apr 26 22:21 libnvinfer_builder_resource.so.8.6.1 |
| 235369632 Apr 26 15:14 libnvinfer.so.8.6.1 | 235369632 Apr 26 22:21
libnvinfer.so.8.6.1 |
### Description
This change is a follow-up to #15327. It adds Unary operators (Sqrt,
Reciprocal) and Reduce operators (ReduceSum, ReduceMean). I've tried to
follow existing patterns in the code :-)
### Motivation and Context
This reduces fragmentation across EPs when using CoreML on macOS,
thereby speeding up execution.
---------
Co-authored-by: Edward Chen <18449977+edgchen1@users.noreply.github.com>
### Description
<!-- Describe your changes. -->
Pad18 adds the `axes` input, which is used to indicate what axes the
padding values should be applied to. Add logic to manipulate paddings
into DML padding operator inputs.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Linnea May <linneamay@microsoft.com>
### Description
Adds the session config option `disable_cpu_ep_fallback` to allow the
user to prevent the CPU EP from handling
nodes not supported by other execution providers.
```C++
// Graph nodes that are not supported by the execution providers (EPs) explicitly added to the session are
// assigned (i.e., "fallback") to the CPU EP by default.
//
// This option allows the user to disable the fallback of unsupported graph nodes to the CPU EP.
// If this option is set to "1", session creation will fail if the execution providers other than the CPU EP cannot
// fully support all of the nodes in the graph.
//
// It is invalid to set this option and explicitly add the CPU EP to the session. In this case, session creation
// will also fail with an error.
//
// Option values:
// - "0": CPU EP fallback is not disabled. [DEFAULT]
// - "1": CPU EP fallback is disabled.
static const char* const kOrtSessionOptionsDisableCPUEPFallback = "session.disable_cpu_ep_fallback";
```
#### Example use
```C++
#include "core/session/onnxruntime_cxx_api.h"
#include "core/session/onnxruntime_session_options_config_keys.h"
int main(int argc, char** argv) {
Ort::SessionOptions so;
so.AddConfigEntry(kOrtSessionOptionsDisableCPUEPFallback, "1"); // Disable fallback to the CPU EP.
onnxruntime::ProviderOptions options;
#if defined(_WIN32)
options["backend_path"] = "QnnCpu.dll";
#else
options["backend_path"] = "libQnnCpu.so";
#endif
so.AppendExecutionProvider("QNN", options);
const ORTCHAR_T* ort_model_path = ORT_MODEL_FOLDER "qnn_ep_partial_support.onnx";
Ort::Session session(*ort_env, ort_model_path, so); // Throws exception if nodes fallback to CPU
// ...
```
### Motivation and Context
Makes it easier for application developers to ensure that the entire
model runs on specific EPs. This is critical for Qualcomm/scenarios. If
the compute cannot be offloaded to the NPU, running on CPU is not
acceptable. (could be the difference between 90 second inference and 6
seconds inference)
---------
Co-authored-by: Pranav Sharma <prs@microsoft.com>
### Description
Transpose will fail in cuda for FLOAT16 for tensors larger than
1048x1048 due to our optimized case exceeding the cuda grid size of
65536.
The fix is to just use our regular cuda transpose in these cases.
### Motivation and Context
https://github.com/microsoft/onnxruntime/issues/16039
### Description
- Adds support for Resize with the `asymmetric` coordinate
transformation mode on the QNN HTP backend.
- Adds unit test that shows this is only correct if the `nearest_mode`
is `"floor"`.
### Motivation and Context
This is needed to enable more models to run on the QNN HTP backend.
Note:
QNN's ONNX converter tool translates an ONNX Resize op with `{mode:
"nearest", coordinate_transformation_mode: "asymmetric", "nearest_mode":
<ANYTHING>}` to QNN's ResizeNearestNeighbor with `{align_corners: 0,
half_pixel: 0}`.
Unit tests show that this is only accurate if the ONNX attribute
nearest_mode is "floor". Need to investigate how to handle other
rounding modes. Ideally, we would use QNN's own Resize operator (instead
of ResizeNearestNeighbor), but that doesn't support the "asymmetric"
coordinate transformation mode on the HTP backend.
### Description
<!-- Describe your changes. -->
The CoreML EP implementation was not reading the axis attribute
correctly causing an incorrect output shape to be produced for a Flatten
node. That issue gets hidden as the Tensor to write the output to is
created by the CoreML EP using the inferred output shape (which is
correct) and we provide the Tensor's buffer but not the shape when
executing the CoreML model. As the flatten isn't changing or moving any
data nothing breaks when we test with only a Flatten node in the model.
Fix the attribute name and add a test that uses a model with a Flatten
followed by a Mul which requires broadcasting. Both nodes are handled by
CoreML, so if the axis is not correctly processed the output from
Flatten will not be broadcastable and the CoreML model execution will
fail.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Bug fix.
### Description
Redirect Qnn log to Ort log.
Set Qnn log level align with Ort log level
Always output Qnn log as Ort verbose log
### Motivation and Context
Redirect Qnn log to Ort log instead of print to console.
---------
Co-authored-by: Edward Chen <18449977+edgchen1@users.noreply.github.com>
### Enable conditional optimization on inputs
Label sparsity based optimization can be enabled depending on the input
inspection result.
So this PR introduce a conditional optimization path for ORTModule,
where we automatically detect data sparsity from label or embedding, and
enable the graph optimization accordingly without any user interaction.
This feature had a new requirement of delaying passing pre_grad graph
transformation config to OrtModuleGraphBuilder, from `Initialize` phase
to its `Build` phase. Because once after `_initialize_graph_builder` we
can detect the input sparsity, and make a decision to enable the
label/embed sparisty based graph optimizations.
Add UT cases for label/embed input runtime inspector.
### Description
Remove NETSTANDARD1.1 moniker and NETSTD1.1 specific code. We no longer
target this platform.
### Motivation and Context
NETSTANDARD1.1 target constraints the development and the modern
libraries we would like to use in the code while it is apparently no
longer required by customers.
### Description
<!-- Describe your changes. -->
Use the unique name of the function node name to uniquify the subgraph
node names.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
Prevent duplicate node names in the graph.
- If it fixes an open issue, please link to the issue here. -->
https://github.com/microsoft/onnxruntime/issues/15849
---------
Co-authored-by: Satya Jandhyala <sajandhy@microsoft.com>
improve softmax forward when number of elem to do softmax is between
(1024,2048]
several optimizations done in the PR:
1. originally ort will call softmax_block_forward when shape is 1500,
this will cause 5.53ms, however ort has another implementation called
softmax_warp_forward, this function will only need 4.74ms, so i modified
the function selection logic to call the faster version.
2. softmax_warp_forward will use register to cache the input in fp32
mode, this will consume many registers when data number is large and
will make warp occupancy quite low, also compiler can do some of its
optimizations, so the pr implements another version of
softmax_warp_forward, it will use shared memory instead of register to
cache the input; also when the for loop in the function has many
iterations, actually disable loop unrolling will make kernel faster
further.
the perf table between softmax_warp_forward1(the original version) and
softmax_warp_forward2
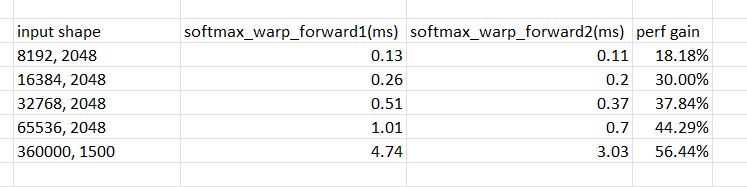
in open-ai whisper case, the kernel gain will be 5.53ms/3.03ms = 82%
(softmax_block_forward vs softmax_warp_forward2)
### Description
Remove the "onnxruntime_BUILD_WEBASSEMBLY" cmake option. Use `if
(CMAKE_SYSTEM_NAME STREQUAL "Emscripten")` instead. It makes some code
look more nature.
For example,
```cmake
if (CMAKE_SYSTEM_NAME STREQUAL "iOS" OR CMAKE_SYSTEM_NAME STREQUAL "Android" OR onnxruntime_BUILD_WEBASSEMBLY)
```
becomes
```cmake
if (CMAKE_SYSTEM_NAME STREQUAL "iOS" OR CMAKE_SYSTEM_NAME STREQUAL "Android" OR CMAKE_SYSTEM_NAME STREQUAL "Emscripten")
```
### Description
because of #15618 , the default allocator changed to device allocator,
which will be GPU instead of CPU. in transpose optimizer we expect to
read data from initializers so a CPU allocator is required here.
this change fixes transpose optimizer on GPU EP
Fixes the issue referred to in #15869, #15796
### Description
Enable Qnn Context cache feature to save model initialization time
Provider options:
qnn_context_cache_enable|1 to enable the cache feature
qnn_context_cache_path to set the cache path. It is set to model_file.onnx.bin by default.
### Motivation and Context
Model initialization time takes long because the cost of conversion from Onnx model to Qnn model. Qnn have feature to serialize the Qnn context to file, then next time user can load it from the cache context and execute the graph to save the cost.
---------
Co-authored-by: Adrian Lizarraga <adlizarraga@microsoft.com>
{kind=link}
{kind=link}