mirror of
https://github.com/saymrwulf/onnxruntime.git
synced 2026-07-22 19:23:30 +00:00
Introduce register-efficient warp-wise Softmax (#15266)
improve softmax forward when number of elem to do softmax is between (1024,2048] several optimizations done in the PR: 1. originally ort will call softmax_block_forward when shape is 1500, this will cause 5.53ms, however ort has another implementation called softmax_warp_forward, this function will only need 4.74ms, so i modified the function selection logic to call the faster version. 2. softmax_warp_forward will use register to cache the input in fp32 mode, this will consume many registers when data number is large and will make warp occupancy quite low, also compiler can do some of its optimizations, so the pr implements another version of softmax_warp_forward, it will use shared memory instead of register to cache the input; also when the for loop in the function has many iterations, actually disable loop unrolling will make kernel faster further. the perf table between softmax_warp_forward1(the original version) and softmax_warp_forward2 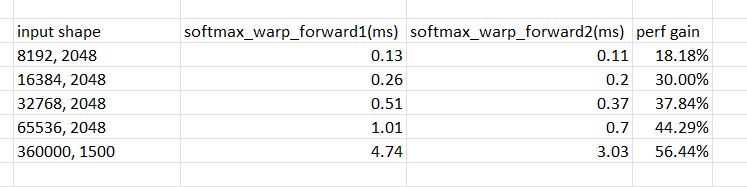 in open-ai whisper case, the kernel gain will be 5.53ms/3.03ms = 82% (softmax_block_forward vs softmax_warp_forward2)
{kind=link}
This commit is contained in:
parent
0204594f90
commit
5607a7151a
3 changed files with 118 additions and 56 deletions
|
|
@ -26,8 +26,9 @@ Status SoftMaxComputeHelper(
|
|||
int64_t D = input_shape.SizeFromDimension(axis);
|
||||
auto Y_data = reinterpret_cast<CudaT_OUT*>(Y);
|
||||
auto X_data = reinterpret_cast<const CudaT_IN*>(X);
|
||||
|
||||
if (D <= 1024 && D * sizeof(T) <= 4096) {
|
||||
// According to nsight compute profiling, softmax_warp_forward_resource_efficient is better than dispatch_blockwise_softmax_forward when 1024 < D <=2048 and N >= 8192.
|
||||
const bool use_softmax_warp_forward_resource_efficient = 1024 < D && D <= 2048 && D * sizeof(T) <= 4096 && N >= 8192;
|
||||
if ((D <= 1024 && D * sizeof(T) <= 4096) or use_softmax_warp_forward_resource_efficient) {
|
||||
return dispatch_warpwise_softmax_forward<
|
||||
CudaT_IN, CudaT_OUT, AccumulationType_t<CudaT_ACCUM>, is_log_softmax>(
|
||||
stream, Y_data, X_data, gsl::narrow_cast<int>(D), gsl::narrow_cast<int>(D), gsl::narrow_cast<int>(N));
|
||||
|
|
|
|||
|
|
@ -39,67 +39,59 @@ Status dispatch_warpwise_softmax_forward(cudaStream_t stream, output_t* dst, con
|
|||
|
||||
// This value must match the WARP_SIZE constexpr value computed inside softmax_warp_forward.
|
||||
int warp_size = (next_power_of_two < GPU_WARP_SIZE_HOST) ? next_power_of_two : GPU_WARP_SIZE_HOST;
|
||||
|
||||
// This value must match the WARP_BATCH constexpr value computed inside softmax_warp_forward.
|
||||
int threads_per_block, shared_memory_size;
|
||||
// there are 2 options to save one row of the input matrix: register or shared memory
|
||||
// when the number of elements is small, we use register; otherwise, we use shared memory;
|
||||
int batches_per_warp = (next_power_of_two <= 128) ? 2 : 1;
|
||||
|
||||
// use 128 threads per block to maximimize gpu utilization
|
||||
constexpr int threads_per_block = 128;
|
||||
|
||||
if (log2_elements <= 10){
|
||||
// This value must match the WARP_BATCH constexpr value computed inside softmax_warp_forward.
|
||||
// use 128 threads per block to maximimize gpu utilization
|
||||
threads_per_block = 128;
|
||||
shared_memory_size = 0;
|
||||
} else{
|
||||
// setting the number of threads per block to 32 will make index offset calculations easier,
|
||||
// under this setting, the cuda block number will be equal to batch size.
|
||||
threads_per_block = 32;
|
||||
// use shared memory to contain one row of elements
|
||||
// TODO: one more optimization can be done here: we actually not need to save next_power_of_two elements, we can just save the valid elements
|
||||
shared_memory_size = next_power_of_two * sizeof(input_t);
|
||||
}
|
||||
int warps_per_block = (threads_per_block / warp_size);
|
||||
int batches_per_block = warps_per_block * batches_per_warp;
|
||||
int blocks = (batch_count + batches_per_block - 1) / batches_per_block;
|
||||
dim3 threads(warp_size, warps_per_block, 1);
|
||||
// Launch code would be more elegant if C++ supported FOR CONSTEXPR
|
||||
switch (log2_elements) {
|
||||
case 0: // 1
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 0, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 1: // 2
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 1, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 2: // 4
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 2, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 3: // 8
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 3, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 4: // 16
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 4, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 5: // 32
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 5, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 6: // 64
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 6, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 7: // 128
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 7, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 8: // 256
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 8, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 9: // 512
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 9, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
case 10: // 1024
|
||||
softmax_warp_forward<input_t, output_t, acc_t, 10, is_log_softmax>
|
||||
<<<blocks, threads, 0, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
break;
|
||||
default:
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
#define LAUNCH_KERNEL(kernel_name, log2_elements_value) \
|
||||
kernel_name<input_t, output_t, acc_t, log2_elements_value, is_log_softmax> \
|
||||
<<<blocks, threads, shared_memory_size, stream>>>(dst, src, batch_count, softmax_elements_stride, softmax_elements);
|
||||
|
||||
#define CASE_LOG2_ELEMENTS(log2_elements_value) \
|
||||
case log2_elements_value: { \
|
||||
if constexpr (log2_elements_value <= 10) { \
|
||||
LAUNCH_KERNEL(softmax_warp_forward, log2_elements_value) \
|
||||
} else { \
|
||||
LAUNCH_KERNEL(softmax_warp_forward_resource_efficient, log2_elements_value) \
|
||||
} \
|
||||
} break
|
||||
|
||||
CASE_LOG2_ELEMENTS(0);
|
||||
CASE_LOG2_ELEMENTS(1);
|
||||
CASE_LOG2_ELEMENTS(2);
|
||||
CASE_LOG2_ELEMENTS(3);
|
||||
CASE_LOG2_ELEMENTS(4);
|
||||
CASE_LOG2_ELEMENTS(5);
|
||||
CASE_LOG2_ELEMENTS(6);
|
||||
CASE_LOG2_ELEMENTS(7);
|
||||
CASE_LOG2_ELEMENTS(8);
|
||||
CASE_LOG2_ELEMENTS(9);
|
||||
CASE_LOG2_ELEMENTS(10);
|
||||
CASE_LOG2_ELEMENTS(11); // start to use softmax_warp_forward_resource_efficient instead of softmax_warp_forward for better performance
|
||||
#undef LAUNCH_KERNEL
|
||||
#undef CASE_LOG2_ELEMENTS
|
||||
} // switch
|
||||
} // else
|
||||
return CUDA_CALL(cudaGetLastError());
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -163,5 +163,74 @@ __global__ void softmax_warp_forward(output_t* dst, const input_t* src, int batc
|
|||
}
|
||||
}
|
||||
|
||||
|
||||
// softmax_warp_forward uses register to store data in fp32 even when data is fp16, which will cause register resource oversubscription when data is large,
|
||||
// and will lead to low CUDA warp occupancy and thus a poor kernel performance.
|
||||
// softmax_warp_forward_resource_efficient is implemented to solve the issue, it caches data in original data type, and casts it into fp32 when needed,
|
||||
// the idea is like we use recomputation to save resource usage.
|
||||
template <typename input_t, typename output_t, typename acc_t, int log2_elements, bool is_log_softmax>
|
||||
__global__ void softmax_warp_forward_resource_efficient(output_t* dst, const input_t* src, int batch_size, int stride, int element_count) {
|
||||
// 1 cuda block only processes one row and contains 1 cuda warp only.
|
||||
constexpr int next_power_of_two = 1 << log2_elements;
|
||||
constexpr int WARP_SIZE = (next_power_of_two < GPU_WARP_SIZE) ? next_power_of_two : GPU_WARP_SIZE;
|
||||
constexpr int WARP_ITERATIONS = next_power_of_two / WARP_SIZE;
|
||||
|
||||
int local_idx = threadIdx.x;
|
||||
src += blockIdx.x * stride + local_idx;
|
||||
dst += blockIdx.x * stride + local_idx;
|
||||
extern __shared__ unsigned char smem[];
|
||||
input_t (&elements)[WARP_ITERATIONS][WARP_SIZE] = *reinterpret_cast<input_t (*)[WARP_ITERATIONS][WARP_SIZE]>(smem);
|
||||
#pragma unroll
|
||||
for (int it = 0; it < WARP_ITERATIONS; ++it) {
|
||||
int element_index = local_idx + it * WARP_SIZE;
|
||||
if (element_index < element_count) {
|
||||
elements[it][local_idx] = src[it * WARP_SIZE];
|
||||
} else {
|
||||
elements[it][local_idx] = -std::numeric_limits<input_t>::infinity();
|
||||
}
|
||||
}
|
||||
// compute max_value
|
||||
input_t max_value = elements[0][local_idx];
|
||||
#pragma unroll
|
||||
for (int it = 1; it < WARP_ITERATIONS; ++it) {
|
||||
max_value = (max_value > elements[it][local_idx]) ? max_value : elements[it][local_idx];
|
||||
}
|
||||
warp_reduce<input_t, 1, WARP_SIZE, Max>(&max_value);
|
||||
// compute sum
|
||||
acc_t sum{0.0f};
|
||||
// #pragma unroll
|
||||
// "exp" contains many instructions, if we unroll the loop then cuda warp will be stalled because of icache miss and thus lower the perf.
|
||||
for (int it = 0; it < WARP_ITERATIONS; ++it) {
|
||||
int element_index = local_idx + it * WARP_SIZE;
|
||||
if (element_index >= element_count)
|
||||
break;
|
||||
if (is_log_softmax) {
|
||||
sum += std::exp((float)(elements[it][local_idx] - max_value));
|
||||
} else {
|
||||
acc_t tmp = std::exp((float)(elements[it][local_idx] - max_value));
|
||||
elements[it][local_idx] = tmp;
|
||||
sum += tmp;
|
||||
}
|
||||
}
|
||||
warp_reduce<acc_t, 1, WARP_SIZE, Add>(&sum);
|
||||
// store result
|
||||
if (is_log_softmax) sum = static_cast<acc_t>(max_value) + std::log((float)(sum));
|
||||
// do the reciprocal once, so the div operation can be replaced by mul.
|
||||
acc_t invsum = static_cast<acc_t>(1.0f / sum);
|
||||
#pragma unroll
|
||||
for (int it = 0; it < WARP_ITERATIONS; ++it) {
|
||||
int element_index = local_idx + it * WARP_SIZE;
|
||||
if (element_index < element_count) {
|
||||
if (is_log_softmax) {
|
||||
dst[it * WARP_SIZE] = (float)elements[it][local_idx] - sum;
|
||||
} else {
|
||||
dst[it * WARP_SIZE] = (float)elements[it][local_idx] * invsum;
|
||||
}
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
} // namespace cuda
|
||||
} // namespace onnxruntime
|
||||
|
|
|
|||
Loading…
Reference in a new issue