improve softmax forward when number of elem to do softmax is between (1024,2048] several optimizations done in the PR: 1. originally ort will call softmax_block_forward when shape is 1500, this will cause 5.53ms, however ort has another implementation called softmax_warp_forward, this function will only need 4.74ms, so i modified the function selection logic to call the faster version. 2. softmax_warp_forward will use register to cache the input in fp32 mode, this will consume many registers when data number is large and will make warp occupancy quite low, also compiler can do some of its optimizations, so the pr implements another version of softmax_warp_forward, it will use shared memory instead of register to cache the input; also when the for loop in the function has many iterations, actually disable loop unrolling will make kernel faster further. the perf table between softmax_warp_forward1(the original version) and softmax_warp_forward2 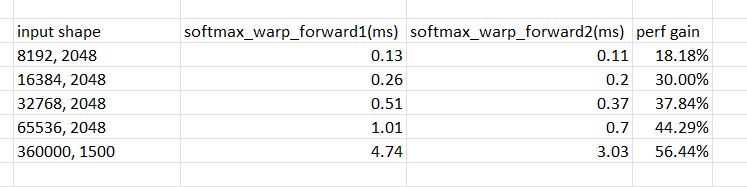 in open-ai whisper case, the kernel gain will be 5.53ms/3.03ms = 82% (softmax_block_forward vs softmax_warp_forward2) |
||
|---|---|---|
| .config | ||
| .devcontainer | ||
| .gdn | ||
| .github | ||
| .pipelines | ||
| .vscode | ||
| cgmanifests | ||
| cmake | ||
| csharp | ||
| dockerfiles | ||
| docs | ||
| include/onnxruntime/core | ||
| java | ||
| js | ||
| objectivec | ||
| onnxruntime | ||
| orttraining | ||
| rust | ||
| samples | ||
| swift/OnnxRuntimeBindingsTests | ||
| tools | ||
| winml | ||
| .clang-format | ||
| .clang-tidy | ||
| .dockerignore | ||
| .gitattributes | ||
| .gitignore | ||
| .gitmodules | ||
| .lintrunner.toml | ||
| build.amd64.1411.bat | ||
| build.bat | ||
| build.sh | ||
| CITATION.cff | ||
| CODEOWNERS | ||
| CONTRIBUTING.md | ||
| lgtm.yml | ||
| LICENSE | ||
| NuGet.config | ||
| ort.wprp | ||
| ORT_icon_for_light_bg.png | ||
| Package.swift | ||
| packages.config | ||
| pyproject.toml | ||
| README.md | ||
| requirements-dev.txt | ||
| requirements-doc.txt | ||
| requirements-lintrunner.txt | ||
| requirements-training.txt | ||
| requirements.txt.in | ||
| SECURITY.md | ||
| setup.py | ||
| ThirdPartyNotices.txt | ||
| VERSION_NUMBER | ||
{kind=link}
{kind=link}
![]()
ONNX Runtime is a cross-platform inference and training machine-learning accelerator.
ONNX Runtime inference can enable faster customer experiences and lower costs, supporting models from deep learning frameworks such as PyTorch and TensorFlow/Keras as well as classical machine learning libraries such as scikit-learn, LightGBM, XGBoost, etc. ONNX Runtime is compatible with different hardware, drivers, and operating systems, and provides optimal performance by leveraging hardware accelerators where applicable alongside graph optimizations and transforms. Learn more →
ONNX Runtime training can accelerate the model training time on multi-node NVIDIA GPUs for transformer models with a one-line addition for existing PyTorch training scripts. Learn more →
Get Started & Resources
-
General Information: onnxruntime.ai
-
Usage documention and tutorials: onnxruntime.ai/docs
-
YouTube video tutorials: youtube.com/@ONNXRuntime
-
Companion sample repositories:
- ONNX Runtime Inferencing: microsoft/onnxruntime-inference-examples
- ONNX Runtime Training: microsoft/onnxruntime-training-examples
Build Pipeline Status
| System | Inference | Training |
|---|---|---|
| Windows | ||
| Linux | ||
| Mac | ||
| Android | ||
| iOS | ||
| Web | ||
| Other |
Data/Telemetry
Windows distributions of this project may collect usage data and send it to Microsoft to help improve our products and services. See the privacy statement for more details.
Contributions and Feedback
We welcome contributions! Please see the contribution guidelines.
For feature requests or bug reports, please file a GitHub Issue.
For general discussion or questions, please use GitHub Discussions.
Code of Conduct
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
License
This project is licensed under the MIT License.