### Description
Add maybe_unused attribute to variables that are only used for logging
### Motivation and Context
Building ORT with training using Xcode 14.3 causes`
-Wunused-but-set-variable` error as some variables are created and
exclusively used for debug logging. Adding maybe_unused suppresses
warnings on unused variables when logging is disabled and fixes the
local build.
ROCm CI batch size test occasionally fail. Try reduce batch size to fix
it.
error log:
Non-zero status code returned while running FusedMatMul node.
Name:'MatMul_2914_Grad/FusedMatMul_0' Status Message: HIP error
hipErrorNotFound:named symbol not found
Non-zero status code returned while running Gemm node.
Name:'MatMul_2891_Grad/Gemm_5' Status Message: HIP error
hipErrorNotFound:named symbol not found
update ROCm/MIGraphX CI to ROC5.5.
TODO:
two PR to fix failure on
orttraining/orttraining/test/python/orttraining_test_ortmodule_api.py
-
test_gradient_correctness_minmax/test_gradient_correctness_argmax_unfold/test_gradient_correctness_argmax_diagonal
(https://github.com/microsoft/onnxruntime/pull/15903)
- test_ortmodule_attribute_name_collision_warning
(https://github.com/microsoft/onnxruntime/pull/15884)
### Few minor refinements:
- Simplify ParameterOptimizerState a bit
- Use inlined containers
- Remove GetStateDict APIs]
- Re-enable cuda test for lr scheduler
### Add CPU allocation test for non-CPU devices distributed run
When CUDA EP is enabled in distributed training, CPU memory is still
used for some node output. Early we have distributed run test coverage,
but don't cover the case when some of the node are using CPU devices for
storing tensor output. As a result, I recalled we hit regression twice
in the passing months:
- https://github.com/microsoft/onnxruntime/pull/14050
- https://github.com/microsoft/onnxruntime/pull/15823
So adding this test to avoid future regressions.
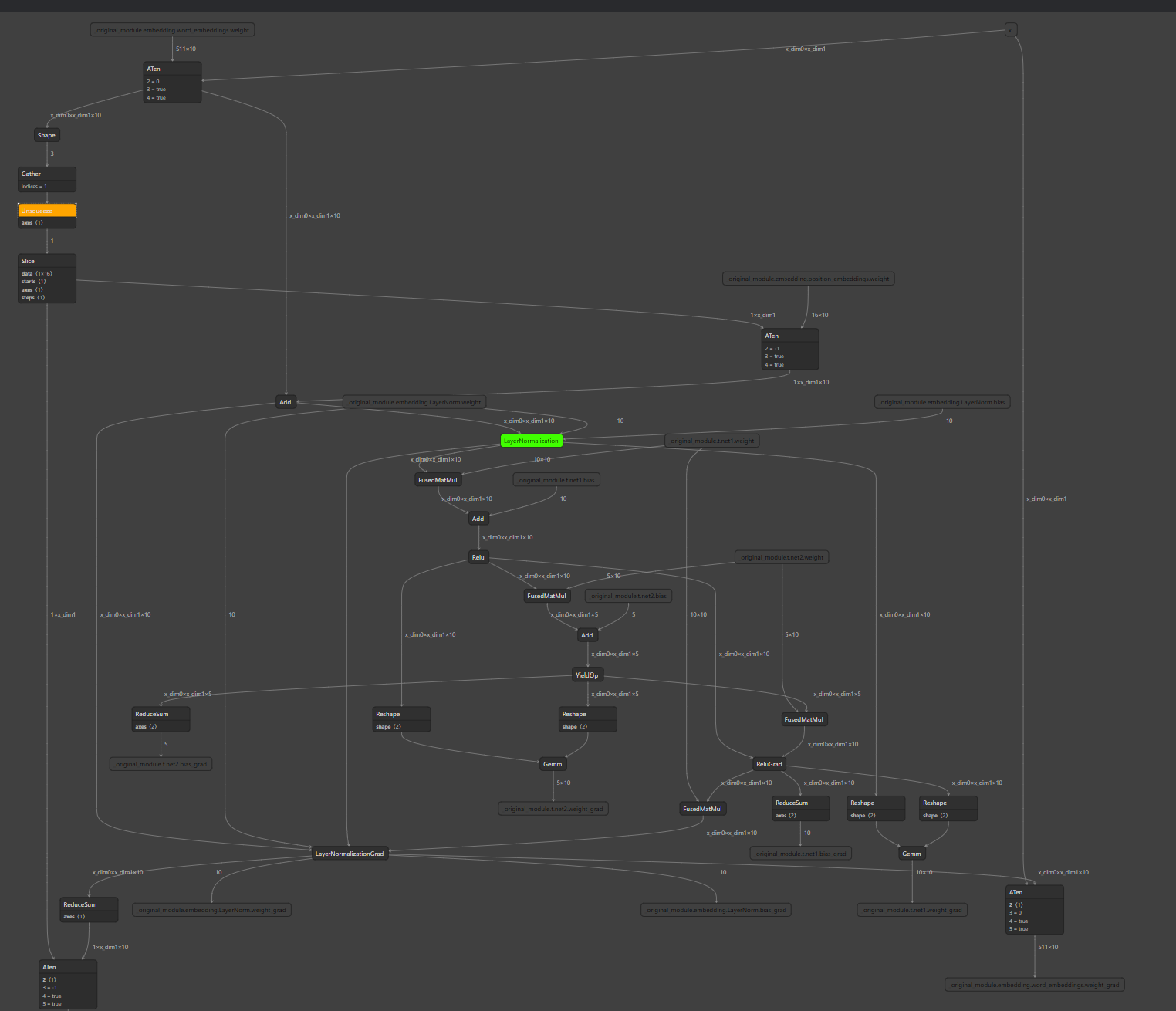
The test graph looks like this:
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
This PR creates Nuget and Android for Training.
### Motivation and Context
These packages are intended to be released in ORT 1.15 to enable
On-Device Training Scenarios.
## Packaging Story for Learning On The Edge Release
### Nuget Packages:
1. New Native package -> **Microsoft.ML.OnnxRuntime.Training** (Native
package will contain binaries for: win-x86, win-x64, win-arm, win-arm64,
linux-x64, linux-arm64, android)
2. C# bindings will be added to existing package ->
**Microsoft.ML.OnnxRuntime.Managed**
### Android Package published to Maven:
1. New package for training (full build) ->
**onnxruntime-training-android-full-aar**
### Python Package published to PyPi:
1. Python bindings and offline tooling will be added to the existing ort
training package -> **onnxruntime-training**
### Fold shape related operation at best efforts.
This is a follow up for PR
https://github.com/microsoft/onnxruntime/pull/12561.
Create a specialized shape_optimzer to constant fold shape related
operation.
ShapeOptimizer at the best efforts to constant fold the dim values that
exists from shape inferencing. This is helpful to simplify the graph,
which on the other hand, help other graph transformers to do more.
Transformer that traverses the graph top-down and performs shape
optimizations.
Try the best effort to constant fold the shape related to Shape node
outputs:
1. Shape generates 1D tensor [12, 128, 512] (all dimensions have
concrete dim value), which can be constant folded
to an initializer including 1D tensor values [12, 128, 512]. (Some logic
of ConstantFolding also does the same thing.)
2. Shape generate 1D tensor [batch_size, 128, 512] ->
Slice(start=1,end=3), we can constant fold the Shape->Slice to
an initializer including 1D tensor values [128, 512].
3. Shape generate 1D tensor [batch_size, 128, 512] -> Gather(axes=[0],
index=[2]), we can constant fold the
Shape->Gather to an initializer including 1D tensor values [512].
4. Shape 15 takes input of shape [batch_size, 128, 512], slicing from 1
to 2(exclusive), we can constant fold the
Shape15(start=1,end=2) to an initializer including 1D tensor values
[128].
This would help clean up the graph, combined with ConstantFolding, the
graph would be much more simplified.
### Motivation and Context
One direct motivation to have this is, we have a model subgraph like
this:
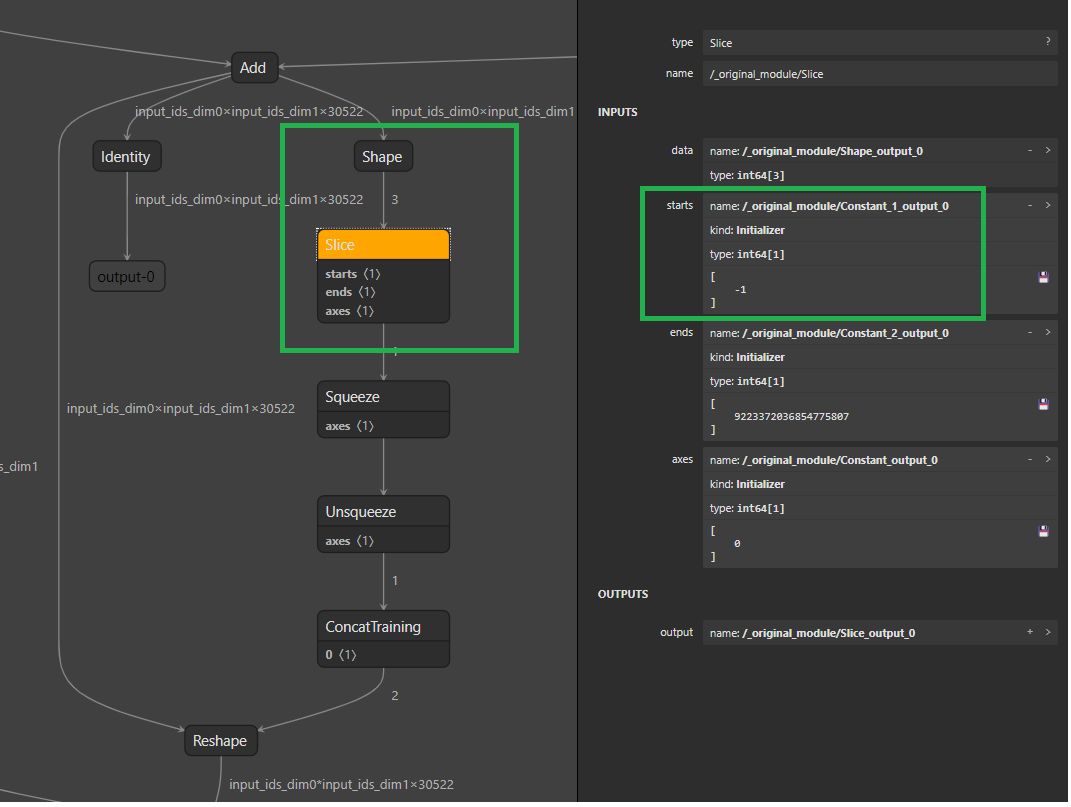
The subgraph in the green rectangle is trying to get the value `30522`,
with the changes in this PR, the subgraph will be constant folded. Plus
ConstantFolding optimizer will further to optimize out the subsquent
`Squeeze`/`Unsqueeze`/`ConcatTraining`, then we will have a clean very
clean Reshape node, with its shape input be an constant `[-1, 20522]`.
Having this simplified graph, our other compute optimizer can help
further optimize the graph by re-ordering gather/reshape nodes.
### Description
<!-- Describe your changes. -->
support the latest deepspeed 0.9.1 for the next release
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This will avoid the warn message `Skip modifying optimizer because of
unsupported DeepSpeed version`
---------
Co-authored-by: ruiren <ruiren@microsoft.com>
### Description
<!-- Describe your changes. -->
### Error
```
RuntimeError: There was an error while exporting the PyTorch model to ONNX:-
Traceback (most recent call last):
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/onnxruntime/training/ortmodule/_utils.py", line 254, in get_exception_as_string
raise exception
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/onnxruntime/training/ortmodule/_graph_execution_manager.py", line 385, in _get_exported_model
torch.onnx.export(self._flattened_module,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/__init__.py", line 305, in export
return utils.export(model, args, f, export_params, verbose, training,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 118, in export
_export(model, args, f, export_params, verbose, training, input_names, output_names,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 743, in _export
proto, export_map, val_use_external_data_format = graph._export_onnx(
RuntimeError: ONNX export failed: Couldn't export Python operator XDropout
```
The error leads to Out of Memory issue, because the log.txt file is **26
GB**.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
The root cause is that in each `_forward`
```
if log_level <= _logger.LogLevel.WARNING and not self._raised_ORTModuleONNXModelException:
warnings.warn(
(
f"Fallback to PyTorch due to exception {type(self._exception)} was triggered. "
"Report this issue with a minimal repro at https://www.github.com/microsoft/onnxruntime. "
f"See details below:\n\n{_utils.get_exception_as_string(self._exception)}"
),
UserWarning,
)
```
above code will be called and log the `exception` through
`get_exception_as_string`,
In my training case, this will lead to 40 k times of `Traceback` stdout
and 110 millions lines of `onnx graph` output and run into OOM.
### Validation
After above fixes, the log.txt file will only be **2.4 MB**.
---------
Co-authored-by: ruiren <ruiren@microsoft.com>
### Description
Removing compute optimizer from on device training builds.
### Motivation and Context
1. mitigate android build failures
2. reduce binary size
Since only CPU EP is enabled for LTE builds, we can optimize the models
offline.
### Description
Run clang-format in CI. Formatted all c/c++, objective-c/c++ files.
Excluded
```
'onnxruntime/core/mlas/**',
'onnxruntime/contrib_ops/cuda/bert/tensorrt_fused_multihead_attention/**',
```
because they contain assembly or is data heavy
### Motivation and Context
Coding style consistency
### Description
Bump ruff version in CI and fixed new lint errors.
- This change enables the flake8-implicit-str-concat rules which helps
detect unintended string concatenations:
https://beta.ruff.rs/docs/rules/#flake8-implicit-str-concat-isc
- Update gitignore to include common python files that we want to
exclude.
### Motivation and Context
Code quality
### Description
Temporarily disable BatchNormalizationGrad test due to random failure.
Example:
```
2023-04-12T06:33:24.1593811Z 1: [ RUN ] GradientCheckerTest.BatchNormalizationGrad
2023-04-12T06:33:27.5603881Z 1: D:\a\_work\1\s\orttraining\orttraining\test\gradient\gradient_ops_test.cc(1468): error: Value of: IsErrorWithinTolerance(max_error, error_tolerance)
2023-04-12T06:33:27.5604509Z 1: Actual: false
2023-04-12T06:33:27.5604719Z 1: Expected: true
2023-04-12T06:33:27.5604997Z 1: max_error: 1.776702880859375; tolerance: 0.019999999552965164; ORT test random seed: 2552121240;
2023-04-12T06:33:27.5605266Z 1: Google Test trace:
2023-04-12T06:33:27.5605531Z 1: D:\a\_work\1\s\onnxruntime\test\common\tensor_op_test_utils.cc(14): ORT test random seed: 8910
2023-04-12T06:33:27.5605843Z 1: D:\a\_work\1\s\onnxruntime\test\common\tensor_op_test_utils.cc(14): ORT test random seed: 5678
2023-04-12T06:33:27.5606478Z 1: D:\a\_work\1\s\onnxruntime\test\common\tensor_op_test_utils.cc(14): ORT test random seed: 1234
2023-04-12T06:33:27.8285560Z 1: D:\a\_work\1\s\orttraining\orttraining\test\gradient\gradient_ops_test.cc(1493): error: Value of: IsErrorWithinTolerance(max_error, error_tolerance)
2023-04-12T06:33:27.8286181Z 1: Actual: false
2023-04-12T06:33:27.8286404Z 1: Expected: true
2023-04-12T06:33:27.8286669Z 1: max_error: 1.776702880859375; tolerance: 0.019999999552965164; ORT test random seed: 2552121240;
2023-04-12T06:33:27.8286942Z 1: Google Test trace:
2023-04-12T06:33:27.8287208Z 1: D:\a\_work\1\s\onnxruntime\test\common\tensor_op_test_utils.cc(14): ORT test random seed: 8910
2023-04-12T06:33:27.8287532Z 1: D:\a\_work\1\s\onnxruntime\test\common\tensor_op_test_utils.cc(14): ORT test random seed: 5678
2023-04-12T06:33:27.8287849Z 1: D:\a\_work\1\s\onnxruntime\test\common\tensor_op_test_utils.cc(14): ORT test random seed: 1234
2023-04-12T06:33:51.6368960Z 1: [ FAILED ] GradientCheckerTest.BatchNormalizationGrad (27475 ms)
```
### Optimize SCE loss compute
Compute optimization based on label data sparsity:
- Insert ShrunkenGather before SCELoss node, to filter out invalid
labels for compute.
- Support ShrunkenGather upstream.
- Added test for the above.
- Added flag to enable label sparsity optimization with env var, by
default disabled now. Will enable after comprehensive benchmarking
later.
- Extract common logic into test_optimizer_utils.h/cc from
core/optimizer/compute_optimzier_test.cc, then the common functions can
be shared by both core/optimizer/compute_optimzier_test.cc and
orttraining/core/optimizer/compute_optimzier_test.cc
- Extract common logic into shared_utils.h/cc: `GetONNXOpSetVersion` and
`Create1DInitializerFromVector`
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
**Description**: Register an implementation for BatchNormInternal and
add a CPU kernel for BatchNormGradient. This is the third in a series of
PRs to implement BN training on CPU (first was #6946, second was #7539).
**Motivation and Context**
Support training networks with BatchNorm (e.g. convnets). Also note that
there exists a CUDA kernel for BN (forward training & backwards) but
it's currently disabled due to flaky failures; someone more familiar
with those parts can register the implementation for BNInternal on CUDA
(gradient kernel doesn't have to change).
---------
Co-authored-by: Simon Zirui Guo <simonguozirui@berkeley.edu>
Co-authored-by: mindest <linminuser@gmail.com>
Co-authored-by: mindest <30493312+mindest@users.noreply.github.com>
### Description
<!-- Describe your changes. -->
Update the support deepspeed to 0.8.3 as it's the latest version
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This will fix the error of `Skip modifying optimizer because of
unsupported DeepSpeed version`
Co-authored-by: ruiren <ruiren@microsoft.com>
### Introduce shrunken gather operator
Exist Gather operator schema won't guarantee output element count will
be smaller than input element count.
Actually, it is possible output element count >, =, or < input element
count.
For some cases we know for sure output element count MUST be <= input
element count, we will upstream those Gather operators to reduce compute
flops.
So this PR introduces an ShrunkenGather which explicitly guarantee
output count will be smaller than input count. The operator add
additional restriction on inputs, but still re-use existing Gather's
implementations plus input check during runtime.
This is a requirement for subsequent optimization (Draft PR:
https://github.com/microsoft/onnxruntime/pull/15401) we will do for
label sparsity and embedding sparsity.
### Description
`lintrunner` is a linter runner successfully used by pytorch, onnx and
onnx-script. It provides a uniform experience running linters locally
and in CI. It supports all major dev systems: Windows, Linux and MacOs.
The checks are enforced by the `Python format` workflow.
This PR adopts `lintrunner` to onnxruntime and fixed ~2000 flake8 errors
in Python code. `lintrunner` now runs all required python lints
including `ruff`(replacing `flake8`), `black` and `isort`. Future lints
like `clang-format` can be added.
Most errors are auto-fixed by `ruff` and the fixes should be considered
robust.
Lints that are more complicated to fix are applied `# noqa` for now and
should be fixed in follow up PRs.
### Notable changes
1. This PR **removed some suboptimal patterns**:
- `not xxx in` -> `xxx not in` membership checks
- bare excepts (`except:` -> `except Exception`)
- unused imports
The follow up PR will remove:
- `import *`
- mutable values as default in function definitions (`def func(a=[])`)
- more unused imports
- unused local variables
2. Use `ruff` to replace `flake8`. `ruff` is much (40x) faster than
flake8 and is more robust. We are using it successfully in onnx and
onnx-script. It also supports auto-fixing many flake8 errors.
3. Removed the legacy flake8 ci flow and updated docs.
4. The added workflow supports SARIF code scanning reports on github,
example snapshot:

5. Removed `onnxruntime-python-checks-ci-pipeline` as redundant
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Unified linting experience in CI and local.
Replacing https://github.com/microsoft/onnxruntime/pull/14306
---------
Signed-off-by: Justin Chu <justinchu@microsoft.com>
### Statistics tool for ORTModule convergence parity
As ORTModule get more and more validated, it is pretty fast to
intergrade PyTorch based model with ORT.
The same time, we need make sure once there is convergence issue, we
don't spend months of time to investigate. As part of this efforts, this
PR is introducing a tool to dump activation statistics without much
involvement from users. The dumping results contains only some statistic
numbers plus sampled data, which is not big, compared with dumping all
the tensors, it is much faster and space efficient.
For us to use it, two single lines are needed before wrapping ORTModule.
For baseline run, need also apply the same trick.
```
+ from onnxruntime.training.utils.hooks import SubscriberManager, StatisticsSubscriber
+ SubscriberManager.subscribe(model, [StatisticsSubscriber("pt_out", override_output_dir=True)])
```
Once you run the steps, following command can be used to merge result
into per-step-summary respectively for ORT and baseline runs.
```bash
python -m onnxruntime.training.utils.hooks.merge_activation_summary --pt_dir pt_out --ort_dir ort_out --output_dir /tmp/output
```
Docs is added here as part of this PR [convergence investigation
notes](https://github.com/microsoft/onnxruntime/blob/pengwa/conv_tool/docs/ORTModule_Convergence_Notes.md)
Based on the generated merged files, we can compare them with tools.

### Design and Implementation
This PR introduced a common mechanism registering custom logic for
nn.Module's post forward hooks. And statistics for activation
(StatisticsSubscriber) is one of the implementations. If there is other
needs, we can define another XXSubscriber to do the customized things.
### Fix reference count for autograd
When PythonOp kernel initialized, `AddPointerScalarArgs` creates
`const_args_` which put all non-tensor references (including
ProcessGroup, string, or other user types) in it.
In kernel's destructor, all ref cnt got decreased for `const_args_`.
```
void PythonOpBase::Clear() {
for (auto ptr : const_args_) {
auto obj = reinterpret_cast<PyObject*>(ptr);
Py_DECREF(obj);
}
}
```
It means, we did not increase cnt, but just decrease cnt. Running the
unit, segmentation fault will be thrown. The simple fix is to remove the
Py_DECREF for those pointer-type constant inputs triggered by kernel
destructor.
NONTENSOR_OBJECT_POINTER_STORE is the place we increase the reference
during export, then the reference will remain until the python program
terminates.
Additionally tunings:
1. Move some logs into verbose instead of warning in case of flooding
training logs.
2. Move pointer type ref holding from python side
(NONTENSOR_OBJECT_POINTER_STORE) to
orttraining/orttraining/core/framework/torch/custom_function_register.h.
Then we use a consistent approach to manage all PythonOp related python
object/methonds ref count increasing and decreasing.
### Description
Remove the use of `eval` in test code so we don't (1) use eval and (2)
create "unused" local vars that ruff will remove. Predecessor to #15085
### Fix training gpu ci related to pl upgrade
As new version of pln relased, old parameter of pln.Trainer, gpus looks
not supported. So we switch to new params to make it work.
```
['/home/onnxruntimedev/miniconda3/bin/python3', 'orttraining_test_ortmodule_torch_lightning_basic.py', '--train-steps=470', '--epochs=2', '--batch-size=256', '--data-dir', '/mnist']
/home/onnxruntimedev/miniconda3/lib/python3.8/site-packages/torch/onnx/utils.py:1794: FutureWarning: The first argument to symbolic functions is deprecated in 1.13 and will be removed in the future. Please annotate treat the first argument (g) as GraphContext and use context information from the object instead. warnings.warn( Traceback (most recent call last): File "orttraining_test_ortmodule_torch_lightning_basic.py", line 101, in <module> main() File "orttraining_test_ortmodule_torch_lightning_basic.py", line 96, in main trainer = pl.Trainer(**kwargs) File "/home/onnxruntimedev/miniconda3/lib/python3.8/site-packages/pytorch_lightning/utilities/argparse.py", line 69, in insert_env_defaults return fn(self, **kwargs) TypeError: __init__() got an unexpected keyword argument 'gpus'
```
### Description
While browsing the sources I found several typos here and there.
I collected them to a single PR and fixed them.
Namely these typos are: operater, tranform, neccessary, trainig.
After fixing none of them was found anymore:
$ git grep "operater"
$ git grep "tranform"
$ git grep "neccessary"
$ git grep "trainig"
$
### Motivation and Context
Since some of the typos are in example notebooks and markdown files,
users can see them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}