### Description
Remove NETSTANDARD1.1 moniker and NETSTD1.1 specific code. We no longer
target this platform.
### Motivation and Context
NETSTANDARD1.1 target constraints the development and the modern
libraries we would like to use in the code while it is apparently no
longer required by customers.
### Description
<!-- Describe your changes. -->
Use the unique name of the function node name to uniquify the subgraph
node names.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
Prevent duplicate node names in the graph.
- If it fixes an open issue, please link to the issue here. -->
https://github.com/microsoft/onnxruntime/issues/15849
---------
Co-authored-by: Satya Jandhyala <sajandhy@microsoft.com>
improve softmax forward when number of elem to do softmax is between
(1024,2048]
several optimizations done in the PR:
1. originally ort will call softmax_block_forward when shape is 1500,
this will cause 5.53ms, however ort has another implementation called
softmax_warp_forward, this function will only need 4.74ms, so i modified
the function selection logic to call the faster version.
2. softmax_warp_forward will use register to cache the input in fp32
mode, this will consume many registers when data number is large and
will make warp occupancy quite low, also compiler can do some of its
optimizations, so the pr implements another version of
softmax_warp_forward, it will use shared memory instead of register to
cache the input; also when the for loop in the function has many
iterations, actually disable loop unrolling will make kernel faster
further.
the perf table between softmax_warp_forward1(the original version) and
softmax_warp_forward2
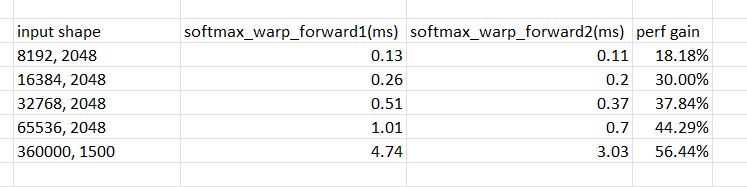
in open-ai whisper case, the kernel gain will be 5.53ms/3.03ms = 82%
(softmax_block_forward vs softmax_warp_forward2)
### Description
Remove the "onnxruntime_BUILD_WEBASSEMBLY" cmake option. Use `if
(CMAKE_SYSTEM_NAME STREQUAL "Emscripten")` instead. It makes some code
look more nature.
For example,
```cmake
if (CMAKE_SYSTEM_NAME STREQUAL "iOS" OR CMAKE_SYSTEM_NAME STREQUAL "Android" OR onnxruntime_BUILD_WEBASSEMBLY)
```
becomes
```cmake
if (CMAKE_SYSTEM_NAME STREQUAL "iOS" OR CMAKE_SYSTEM_NAME STREQUAL "Android" OR CMAKE_SYSTEM_NAME STREQUAL "Emscripten")
```
### Description
because of #15618 , the default allocator changed to device allocator,
which will be GPU instead of CPU. in transpose optimizer we expect to
read data from initializers so a CPU allocator is required here.
this change fixes transpose optimizer on GPU EP
Fixes the issue referred to in #15869, #15796
### Description
Enable Qnn Context cache feature to save model initialization time
Provider options:
qnn_context_cache_enable|1 to enable the cache feature
qnn_context_cache_path to set the cache path. It is set to model_file.onnx.bin by default.
### Motivation and Context
Model initialization time takes long because the cost of conversion from Onnx model to Qnn model. Qnn have feature to serialize the Qnn context to file, then next time user can load it from the cache context and execute the graph to save the cost.
---------
Co-authored-by: Adrian Lizarraga <adlizarraga@microsoft.com>
* graph tools update
* cuda kernel update
* operator spec update and implementation update
* greed search bug fix on wrong assumption for cross/self attention
input length
* avoid use of "" name in value info when loading graph which
historically in many model
### Description
In PR #15797, the author manually edited the
cgmanifests/generated/cgmanifest.json file and made an error that makes the file ill formed.
### Motivation and Context
### Description
<!-- Describe your changes. -->
Should not set up dependent node list for empty('') input
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Removing C4090 warning suppression after windows pipelines adapt vs2022
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
This PR adds the training headers to the training android packages.
### Motivation and Context
Training headers need to be added as part of the training android
packages, however because of the typo in the cmake these headers were
not being added. This PR fixes the issue.
### Description
Revert a change in #15797: restore the correct version of emsdk
### Motivation and Context
Without change, when you build it on Windows you will see:
```
2023-05-17 19:41:30,093 build [INFO] - Activating emsdk...
2023-05-17 19:41:30,093 util.run [INFO] - Running subprocess in 'C:\src\onnxruntime2\cmake\external\emsdk'
'C:\src\onnxruntime2\cmake\external\emsdk\emsdk.bat' activate 3.1.37
error: tool or SDK not found: '3.1.37'
```
### Description
<!-- Describe your changes. -->
Minor changes to allow CoreML EP to handle more nodes and models.
- Remove graph input dynamic shape check from
coreml::GetSupportedNodes(). Each node input is still checked.
- Add check for optional input in coreml::IsInputSupported(). If an
input does not exist it should not be considered unsupported.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Some CoreML EP checks seem too strict now.
Here's the motivating issue:
https://github.com/microsoft/azure-pipelines-tasks/issues/10331
Noticed some problems in other repos so also updating usages in ORT.
We may be fine now without it, but this change adds some safeguard against future additions of 'set -x' for debugging.
### Description
Change CUDA pipelines to download CUDA SDK in every build job
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Add dml registration for bitwise and, or, xor and not added in opset 18.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Linnea May <linneamay@microsoft.com>
### Description
Add maybe_unused attribute to variables that are only used for logging
### Motivation and Context
Building ORT with training using Xcode 14.3 causes`
-Wunused-but-set-variable` error as some variables are created and
exclusively used for debug logging. Adding maybe_unused suppresses
warnings on unused variables when logging is disabled and fixes the
local build.
### Description
1. Set gtest output while ctest is set to empty.
2. onnx_src in _deps shouldn't be removed because
onnx_test_pytorch_converted and onnx_test_pytorch_converted need to read
data from onnx/backend/test/data/..
### Motivation and Context
Test result report is important to find the flaky tests.
### To do
Tests are not inconsistent.
If ctest_path is empty, onnx_test_pytorch_converted and
onnx_test_pytorch_converted will not be executed, if it's not,
onnxruntime_mlas_test will not be executed.
270c09a37f/tools/ci_build/build.py (L1743-L1753)
### Description
After this PR there are following pool need to be updated.
old|new|note
---|---|---
onnxruntime-Win2019-GPU-dml-A10|tbd|
onnxruntime-Win2019-GPU-T4|onnxruntime-Win2022-GPU-T4|
onnxruntime-Win2019-GPU-training-T4|onnxruntime-Win2022-GPU-T4|ame as
the above because we do not have many T4 GPUs
onnxruntime-tensorrt8-winbuild-T4|tbd|
aiinfra-dml-winbuild|tbd|
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This reduces peak nonlocal memory consumption when uploading large
weights for big models (e.g. LLMs), while at the same time trying to
keep the GPU as busy as possible. This change could be more
sophisticated, but at this stage it is the most minimal and least risky
change required to support LLMs.
### Description
In some scenarios, the triton written kernels are more performant than
CK or other handwritten kernels, so we implement a framework that
onnxruntime can use these triton written kernels.
This PR is to integrate triton into ort, so that ort can use kernels
that written and compiled by triton.
The main change focus on two part:
1. a build part to compile triton written kernel and combine these
kernels into libonnxruntime_providers_rocm.so
2. a loader and launcher in c++, for loading and launch triton written
kernels.
#### Build
To compile triton written kernel, add a script
`tools/ci_build/compile_triton.py`. This script will dynamic load all
kernel files, compile them, and generate `triton_kernel_infos.a` and
`triton_kernel_infos.h`.
`triton_kernel_infos.a` contains all compiled kernel instructions, this
file will be combined into libonnxruntime_providers_rocm.so, using
--whole-archive flag.
`triton_kernel_infos.h` defines a const array that contains all the
metadata for each compiled kernel. These metadata will be used for load
and launch. So this header file is included by 'triton_kernel.cu' which
defines load and launch functions.
Add a build flag in build.py and CMakeList.txt, when building rocm
provider, it will call triton_kernel build command, and generate all
necessary files.
#### C++ Load and Launch
On c++ part, we implement load and launch functions in triton_kernel.cu
and triton_kernel.h.
These two files located in `providers/cuda`, and when compiling rocm,
they will be hipified. so this part supports both cuda and rocm. But
currently we only call triton kernel in rocm.
We also implement a softmax triton op for example. Because there will
generate many kernels for different input shape of softmax, we use
TunableOp to select the best one.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Register Split18 for DirectML
Split13 was previously implemented. Split18 adds a new attribute called
"num_outputs" that must be used mutually exclusively with the "split"
input.
The "num_outputs" attribute wil split the tensor evenly (and handles odd
uneven splits). To implement, the DML split tensor just needs to be
overridden in the presence of the num_output attribute.
---------
Co-authored-by: Dwayne Robinson <dwayner@microsoft.com>
### Description
<!-- Describe your changes. -->
Old pool | New pool | Notes
-- | -- | --
onnxruntime-Win-CPU-2019 | onnxruntime-Win-CPU-2022 |
onnxruntime-Win2019-CPU-training | onnxruntime-Win2022-CPU-training-AMD
|
onnxruntime-Win2019-CPU-training-AMD |
onnxruntime-Win2022-CPU-training-AMD | Same as the above
onnxruntime-Win2019-GPU-dml-A10 | Need be created | You need to create a
new image for it first
onnxruntime-Win2019-GPU-T4 | onnxruntime-Win2022-GPU-T4 |
onnxruntime-Win2019-GPU-training-T4 | onnxruntime-Win2022-GPU-T4 | Same
as the above because we do not have many T4 GPUs
onnxruntime-tensorrt8-winbuild-T4| TBD|TBD
Win-CPU-2021|onnxruntime-Win-CPU-2022| will do it in next PR
Win-CPU-2019|onnxruntime-Win2022-Intel-CPU'| Intel CPU needed for
win-ci-pipeline.yml -> `stage: x64_release_dnnl`
<br class="Apple-interchange-newline">
### Motivation and Context
With vs2022 we can take the advantage of 64bit compiler. It also with
better c++20 support
Set default value for parameters in nuget-zip pipeline, and only apply
the configurations when they are not "NONE".
---------
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
<!-- Describe your changes. -->
Adds option to pass in pretrained weights file during T5 inference onnx
export. Mimics the changes made to whisper:
https://github.com/microsoft/onnxruntime/pull/15759
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Required for ONNX Runtime demo being presented at BUILD.
ROCm CI batch size test occasionally fail. Try reduce batch size to fix
it.
error log:
Non-zero status code returned while running FusedMatMul node.
Name:'MatMul_2914_Grad/FusedMatMul_0' Status Message: HIP error
hipErrorNotFound:named symbol not found
Non-zero status code returned while running Gemm node.
Name:'MatMul_2891_Grad/Gemm_5' Status Message: HIP error
hipErrorNotFound:named symbol not found
### Description
Added MaxPool tests to show the issues with MaxPool and also provide
test coverage
The following tests are currently Failing:
./onnxruntime_test_all --gtest_filter=*.TestMaxPool*
[ FAILED ] 5 tests, listed below:
[ FAILED ] QnnCPUBackendTests.TestMaxPool_Ceil
[ FAILED ] QnnCPUBackendTests.TestMaxPool_Large_Input2_Ceil
[ FAILED ] QnnHTPBackendTests.TestMaxPool_Large_Input_HTP_u8
[ FAILED ] QnnHTPBackendTests.TestMaxPool_Large_Input2_HTP_u8
[ FAILED ] QnnHTPBackendTests.TestMaxPool_Large_Input2_Ceil_HTP_u8
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
Provide test coverage for MaxPool and debug model related issues.
This PR mainly fixes building errors when trying to build nupkg for ROCm EP.
It also slighly improve the packaging logic so that devlopers can
produce the nupkg on linux natively.
### Description
<!-- Describe your changes. -->
This should produced fused Resnet50.fp16.onnx
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
This PR enables Whisper's multitask format and allows a user to use
Whisper for multiple tasks (e.g. transcription, translation) and for
multilingual purposes (e.g. English, Spanish). This PR also removes
`attention_mask` as a required input for Whisper with beam search.
### Usage
Here is an example of how you can use Whisper for English transcription.
```
import numpy as np
import onnxruntime as ort
from datasets import load_dataset
from transformers import AutoConfig, AutoProcessor
model = "openai/whisper-tiny"
config = AutoConfig.from_pretrained(model)
processor = AutoProcessor.from_pretrained(model)
forced_decoder_ids = processor.get_decoder_prompt_ids(language="english", task="transcribe")
# forced_decoder_ids is of the format [(1, 50259), (2, 50359), (3, 50363)] and needs to be
# of the format [50258, 50259, 50359, 50363] where 50258 is the start token id
forced_decoder_ids = [config.decoder_start_token_id] + list(map(lambda token: token[1], forced_decoder_ids))
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
input_features = processor(ds[0]["audio"]["array"], return_tensors="np").input_features
inputs = {
"input_features": np.float32(input_features),
"max_length": np.array([26], dtype=np.int32),
"min_length": np.array([1], dtype=np.int32),
"num_beams": np.array([2], dtype=np.int32),
"num_return_sequences": np.array([1], dtype=np.int32),
"length_penalty": np.array([1.0], dtype=np.float32),
"repetition_penalty": np.array([1.0], dtype=np.float32),
"decoder_input_ids": np.array([forced_decoder_ids], dtype=np.int32),
}
sess = ort.InferenceSession("whisper-tiny_beamsearch.onnx", providers=["CPUExecutionProvider"])
outputs = sess.run(None, inputs)
# Print tokens and decoded output
print(outputs[0][0][0])
print(processor.decode(outputs[0][0][0]))
```
If you don't want to provide specific decoder input ids or you want
Whisper to predict the output language and task, you can set
`forced_decoder_ids = [config.decoder_start_token_id]` instead.
### Motivation and Context
As seen in the figure below from the [OpenAI Whisper
paper](https://cdn.openai.com/papers/whisper.pdf), Whisper can be used
for multiple tasks and languages.

{kind=link}
{kind=link}