mirror of
https://github.com/saymrwulf/onnxruntime.git
synced 2026-05-22 22:01:08 +00:00
Fold shape related operation (#14936)
### Fold shape related operation at best efforts. This is a follow up for PR https://github.com/microsoft/onnxruntime/pull/12561. Create a specialized shape_optimzer to constant fold shape related operation. ShapeOptimizer at the best efforts to constant fold the dim values that exists from shape inferencing. This is helpful to simplify the graph, which on the other hand, help other graph transformers to do more. Transformer that traverses the graph top-down and performs shape optimizations. Try the best effort to constant fold the shape related to Shape node outputs: 1. Shape generates 1D tensor [12, 128, 512] (all dimensions have concrete dim value), which can be constant folded to an initializer including 1D tensor values [12, 128, 512]. (Some logic of ConstantFolding also does the same thing.) 2. Shape generate 1D tensor [batch_size, 128, 512] -> Slice(start=1,end=3), we can constant fold the Shape->Slice to an initializer including 1D tensor values [128, 512]. 3. Shape generate 1D tensor [batch_size, 128, 512] -> Gather(axes=[0], index=[2]), we can constant fold the Shape->Gather to an initializer including 1D tensor values [512]. 4. Shape 15 takes input of shape [batch_size, 128, 512], slicing from 1 to 2(exclusive), we can constant fold the Shape15(start=1,end=2) to an initializer including 1D tensor values [128]. This would help clean up the graph, combined with ConstantFolding, the graph would be much more simplified. ### Motivation and Context One direct motivation to have this is, we have a model subgraph like this: 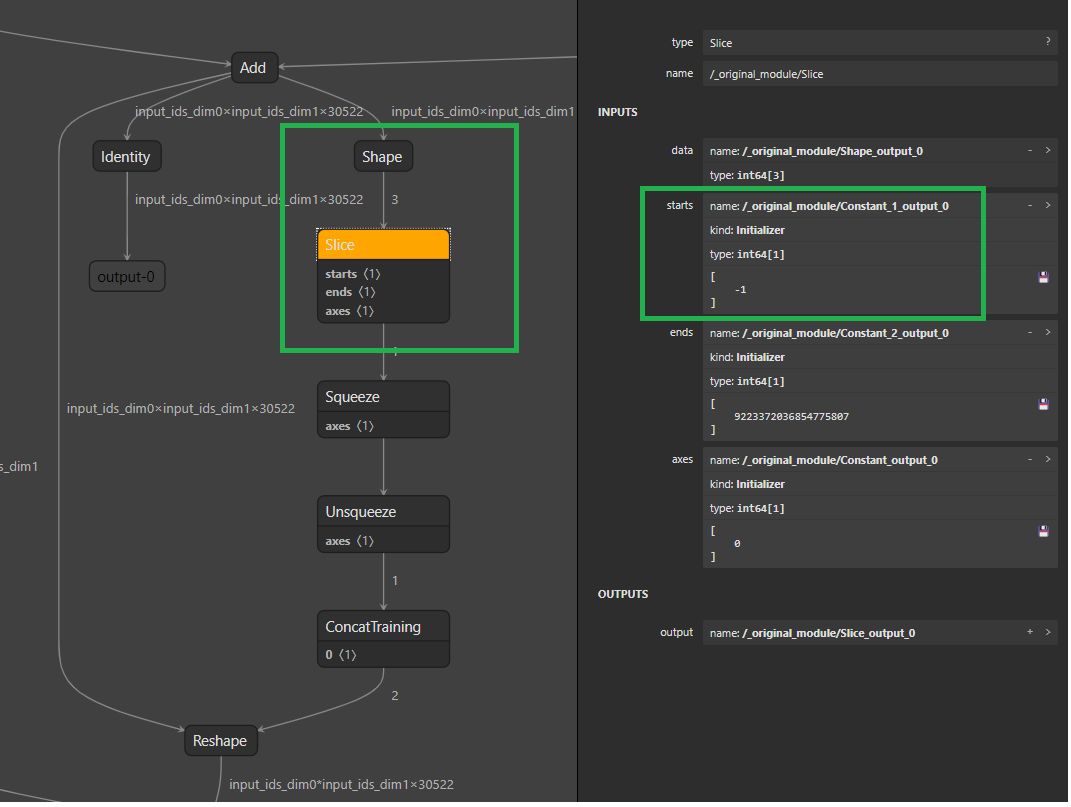 The subgraph in the green rectangle is trying to get the value `30522`, with the changes in this PR, the subgraph will be constant folded. Plus ConstantFolding optimizer will further to optimize out the subsquent `Squeeze`/`Unsqueeze`/`ConcatTraining`, then we will have a clean very clean Reshape node, with its shape input be an constant `[-1, 20522]`. Having this simplified graph, our other compute optimizer can help further optimize the graph by re-ordering gather/reshape nodes.
{kind=link}
This commit is contained in:
parent
53ff50d19a
commit
2efb75bfe9
5 changed files with 1483 additions and 0 deletions
|
|
@ -107,6 +107,29 @@ class ModelTestBuilder {
|
|||
return &graph_.GetOrCreateNodeArg(name, &type_proto);
|
||||
}
|
||||
|
||||
template <typename T>
|
||||
NodeArg* MakeSymbolicInput(const std::vector<std::variant<int64_t, std::string>>& shape) {
|
||||
ONNX_NAMESPACE::TypeProto type_proto;
|
||||
type_proto.mutable_tensor_type()->set_elem_type(utils::ToTensorProtoElementType<T>());
|
||||
type_proto.mutable_tensor_type()->mutable_shape();
|
||||
for (auto& d : shape) {
|
||||
auto dim = type_proto.mutable_tensor_type()->mutable_shape()->add_dim();
|
||||
std::visit([&dim](auto&& arg) -> void {
|
||||
using V = std::decay_t<decltype(arg)>;
|
||||
if constexpr (std::is_same_v<V, int64_t>) {
|
||||
ORT_ENFORCE(arg >= 0, "Negative dimension is not allowed in symbolic shape");
|
||||
dim->set_dim_value(arg);
|
||||
} else {
|
||||
dim->set_dim_param(arg);
|
||||
}
|
||||
},
|
||||
d);
|
||||
}
|
||||
|
||||
std::string name = graph_.GenerateNodeArgName("symbolic_input");
|
||||
return &graph_.GetOrCreateNodeArg(name, &type_proto);
|
||||
}
|
||||
|
||||
NodeArg* MakeOutput() {
|
||||
std::string name = graph_.GenerateNodeArgName("output");
|
||||
output_names_.push_back(name);
|
||||
|
|
|
|||
|
|
@ -59,6 +59,8 @@
|
|||
#include "orttraining/core/optimizer/lstm_replacement.h"
|
||||
#include "orttraining/core/optimizer/transformer_layer_recompute.h"
|
||||
#include "orttraining/core/optimizer/qdq_fusion.h"
|
||||
#include "orttraining/core/optimizer/shape_optimizer.h"
|
||||
#include "orttraining/core/optimizer/transformer_layer_recompute.h"
|
||||
|
||||
// Only enabled in full training build. Not in on device training builds
|
||||
#ifdef ENABLE_TRAINING
|
||||
|
|
@ -145,6 +147,10 @@ std::vector<std::unique_ptr<GraphTransformer>> GeneratePreTrainingTransformers(
|
|||
transformers.emplace_back(std::make_unique<ConstantFolding>(
|
||||
execution_provider, false /*skip_dequantize_linear*/, compatible_eps, excluded_initializers));
|
||||
transformers.emplace_back(std::make_unique<ReshapeFusion>(compatible_eps));
|
||||
// Put fine-grained optimizer (e.g. ShapeOptimizer) after ReshapeFusion to avoid it breaks the strong patterns
|
||||
// it defines. ReshapeFusion depends on subgraph pattern matching and do replacement accordingly, ShapeOptimizer
|
||||
// potentially will optimize out some nodes defined in the subgraph patterns. So we put it after ReshapeFusion.
|
||||
transformers.emplace_back(std::make_unique<ShapeOptimizer>(compatible_eps));
|
||||
transformers.emplace_back(std::make_unique<ConcatSliceElimination>(compatible_eps));
|
||||
|
||||
if (config.gelu_recompute) {
|
||||
|
|
|
|||
369
orttraining/orttraining/core/optimizer/shape_optimizer.cc
Normal file
369
orttraining/orttraining/core/optimizer/shape_optimizer.cc
Normal file
|
|
@ -0,0 +1,369 @@
|
|||
// Copyright (c) Microsoft Corporation. All rights reserved.
|
||||
// Licensed under the MIT License.
|
||||
|
||||
#include "orttraining/core/optimizer/shape_optimizer.h"
|
||||
|
||||
#include <limits>
|
||||
|
||||
#include "core/common/inlined_containers.h"
|
||||
#include "core/framework/tensorprotoutils.h"
|
||||
#include "core/graph/graph_utils.h"
|
||||
#include "core/optimizer/utils.h"
|
||||
|
||||
using namespace onnxruntime::common;
|
||||
|
||||
namespace onnxruntime {
|
||||
|
||||
// TODO(pengwa): better way (instead of defining MACROs locally) to enable detailed debug logs
|
||||
// for some specific graph transformers.
|
||||
// Uncomment to log debug info for SO(Shape Optimizer).
|
||||
// #define NEED_SO_LOG_DEBUG_INFO 1
|
||||
|
||||
#ifndef SO_LOG_DEBUG_INFO
|
||||
#ifdef NEED_SO_LOG_DEBUG_INFO
|
||||
#define SO_LOG_DEBUG_INFO(logger, message) LOGS(logger, WARNING) << message
|
||||
#else
|
||||
#define SO_LOG_DEBUG_INFO(logger, message) \
|
||||
ORT_UNUSED_PARAMETER(logger); \
|
||||
do { \
|
||||
} while (0)
|
||||
#endif
|
||||
#endif
|
||||
|
||||
// Put utilities into an anonymous namespace.
|
||||
namespace {
|
||||
|
||||
constexpr int64_t NormalizeIndex(int64_t initial_index_value, int64_t rank) {
|
||||
// Negative handling
|
||||
int64_t non_negative_index = initial_index_value < 0 ? initial_index_value + rank : initial_index_value;
|
||||
|
||||
// Clamp to [0, rank].
|
||||
if (non_negative_index < 0) {
|
||||
non_negative_index = 0;
|
||||
} else if (non_negative_index > rank) {
|
||||
non_negative_index = rank;
|
||||
}
|
||||
|
||||
return non_negative_index;
|
||||
}
|
||||
|
||||
bool IsSingleValue1DShape(const ONNX_NAMESPACE::TensorShapeProto* input_shape) {
|
||||
if (input_shape == nullptr) {
|
||||
return false;
|
||||
}
|
||||
|
||||
size_t dim_size = static_cast<size_t>(input_shape->dim_size());
|
||||
if (dim_size == 1 && utils::HasDimValue(input_shape->dim(0)) && input_shape->dim(0).dim_value() == 1) {
|
||||
return true;
|
||||
}
|
||||
|
||||
return false;
|
||||
}
|
||||
|
||||
bool CanShapeNodeBeReplacedWithConstant(const Node& shape_node, const TensorShapeVector& dim_values,
|
||||
TensorShapeVector& fold_values) {
|
||||
int64_t data_rank = static_cast<int64_t>(dim_values.size());
|
||||
int64_t start = 0;
|
||||
int64_t end = data_rank; // end is exclusive
|
||||
if (graph_utils::IsSupportedOptypeVersionAndDomain(shape_node, "Shape", {15})) {
|
||||
// Opset-15 Shape supports slicing using a 'start' and 'end' attribute
|
||||
const auto& shape_attributes = shape_node.GetAttributes();
|
||||
for (const auto& attr : shape_attributes) {
|
||||
if (attr.first == "start") {
|
||||
start = attr.second.i();
|
||||
} else if (attr.first == "end") {
|
||||
end = attr.second.i();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
int64_t start_index_normalized = NormalizeIndex(start, data_rank);
|
||||
int64_t end_index_normalized = NormalizeIndex(end, data_rank);
|
||||
|
||||
int64_t slice_length = end_index_normalized - start_index_normalized;
|
||||
slice_length = slice_length < 0 ? 0 : slice_length;
|
||||
|
||||
fold_values.clear();
|
||||
fold_values.reserve(slice_length);
|
||||
for (int64_t i = start_index_normalized; i < end_index_normalized; ++i) {
|
||||
if (dim_values[i] == -1) {
|
||||
// Return false if it contains symbolic dim values.
|
||||
return false;
|
||||
} else {
|
||||
fold_values.push_back(dim_values[i]);
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
bool CanSliceNodeBeReplacedWithConstant(const Graph& graph, const Node& slice_node,
|
||||
const TensorShapeVector& dim_values,
|
||||
TensorShapeVector& fold_values) {
|
||||
const NodeArg* starts_input = slice_node.InputDefs()[1];
|
||||
const NodeArg* ends_input = slice_node.InputDefs()[2];
|
||||
const NodeArg* axes_input = slice_node.InputDefs().size() > 3 ? slice_node.InputDefs()[3] : nullptr;
|
||||
const NodeArg* steps_input = slice_node.InputDefs().size() > 4 ? slice_node.InputDefs()[4] : nullptr;
|
||||
|
||||
// TODO: We support with some constraints currently, can be extended further to support other cases.
|
||||
// Support cases:
|
||||
// 1. starts/ends/axes/steps are all single-value 1D tensors, axes=[0] and steps=[1].
|
||||
// 2. starts/ends are single-value 1D tensors, axes/steps are not provided, (default value: axes=[0] and steps=[1]).
|
||||
if (!IsSingleValue1DShape(starts_input->Shape()) ||
|
||||
!IsSingleValue1DShape(ends_input->Shape()) ||
|
||||
(axes_input && !IsSingleValue1DShape(axes_input->Shape())) ||
|
||||
(steps_input && !IsSingleValue1DShape(steps_input->Shape()))) {
|
||||
return false;
|
||||
}
|
||||
|
||||
// Try to parse the value and double-check.
|
||||
InlinedVector<int64_t> starts_values, ends_values, axes_values, steps_values;
|
||||
if (!(optimizer_utils::AppendTensorFromInitializer(graph, *starts_input, starts_values, true) &&
|
||||
starts_values.size() == 1)) {
|
||||
return false;
|
||||
}
|
||||
if (!(optimizer_utils::AppendTensorFromInitializer(graph, *ends_input, ends_values, true) &&
|
||||
ends_values.size() == 1)) {
|
||||
return false;
|
||||
}
|
||||
if (axes_input && !(optimizer_utils::AppendTensorFromInitializer(graph, *axes_input, axes_values, true) &&
|
||||
axes_values.size() == 1 && axes_values[0] == 0)) {
|
||||
return false;
|
||||
}
|
||||
if (steps_input && !(optimizer_utils::AppendTensorFromInitializer(graph, *steps_input, steps_values, true) &&
|
||||
steps_values.size() == 1 && steps_values[0] == 1)) {
|
||||
return false;
|
||||
}
|
||||
|
||||
int64_t start = starts_values[0];
|
||||
int64_t end = ends_values[0];
|
||||
|
||||
int64_t data_rank = static_cast<int64_t>(dim_values.size());
|
||||
int64_t start_index_normalized = NormalizeIndex(start, data_rank);
|
||||
int64_t end_index_normalized = NormalizeIndex(end, data_rank);
|
||||
|
||||
int64_t slice_length = end_index_normalized - start_index_normalized;
|
||||
slice_length = slice_length < 0 ? 0 : slice_length;
|
||||
fold_values.clear();
|
||||
fold_values.reserve(slice_length);
|
||||
for (int64_t i = start_index_normalized; i < end_index_normalized; ++i) {
|
||||
if (dim_values[i] == -1) {
|
||||
// Return false if it contains symbolic dim values.
|
||||
return false;
|
||||
} else {
|
||||
fold_values.push_back(dim_values[i]);
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
bool CanGatherNodeBeReplacedWithConstant(const Graph& graph, const Node& gather_node,
|
||||
const TensorShapeVector& dim_values,
|
||||
TensorShapeVector& fold_values, int& gather_output_rank) {
|
||||
const NodeArg* data_input = gather_node.InputDefs()[0];
|
||||
|
||||
// TODO: We support with some constraints currently, can be extended further to support other cases.
|
||||
// Support cases:
|
||||
// 1. data is 1D tensor, indices is a scalar, axis=0.
|
||||
// 2. data is 1D tensor, indices is a scalar, axis=0 or axis is not provided (default value: axis=0).
|
||||
// 3. data is 1D tensor, indices is 1D tensor with single element, axis=0.
|
||||
// 4. data is 1D tensor, indices is 1D tensor with single element, axis is not provided (default value: axis=0).
|
||||
|
||||
// Gather's input MUST be 1D tensor.
|
||||
if (!data_input->Shape() || data_input->Shape()->dim_size() != 1) {
|
||||
return false;
|
||||
}
|
||||
|
||||
const NodeArg* indices_input = gather_node.InputDefs()[1];
|
||||
auto indices_shape = indices_input->Shape();
|
||||
// Indices can be 1D tensor or scalar.
|
||||
if (!indices_shape || !(indices_shape->dim_size() == 0 || IsSingleValue1DShape(indices_shape))) {
|
||||
// If the indices did not contain one single element, then skip it.
|
||||
return false;
|
||||
}
|
||||
|
||||
// Try to parse int64 type constant initializers.
|
||||
InlinedVector<int64_t> indices_values;
|
||||
if (!(optimizer_utils::AppendTensorFromInitializer(graph, *indices_input, indices_values, true) &&
|
||||
indices_values.size() == 1)) {
|
||||
return false;
|
||||
}
|
||||
|
||||
const ONNX_NAMESPACE::AttributeProto* axis_attr = graph_utils::GetNodeAttribute(gather_node, "axis");
|
||||
if (axis_attr && static_cast<int>(axis_attr->i()) != 0) {
|
||||
return false;
|
||||
}
|
||||
|
||||
int64_t start = indices_values[0];
|
||||
int64_t data_rank = static_cast<int64_t>(dim_values.size());
|
||||
int64_t start_index_normalized = NormalizeIndex(start, data_rank);
|
||||
|
||||
if (dim_values[static_cast<size_t>(start_index_normalized)] == -1) {
|
||||
// Return false if it contains symbolic dim values.
|
||||
return false;
|
||||
} else {
|
||||
fold_values.push_back(dim_values[static_cast<size_t>(start_index_normalized)]);
|
||||
}
|
||||
|
||||
gather_output_rank = data_input->Shape()->dim_size() + indices_shape->dim_size() - 1;
|
||||
return true;
|
||||
}
|
||||
|
||||
void UpdateNodeArgToConstant(Graph& graph, NodeArg* arg_to_update, const TensorShapeVector& values,
|
||||
bool create_scalar_for_single_value = false) {
|
||||
size_t length = values.size();
|
||||
bool is_scalar = length == 1 && create_scalar_for_single_value;
|
||||
|
||||
// Create new TensorProto.
|
||||
ONNX_NAMESPACE::TensorProto constant_tensor_proto;
|
||||
constant_tensor_proto.set_name(arg_to_update->Name());
|
||||
constant_tensor_proto.set_data_type(ONNX_NAMESPACE::TensorProto_DataType_INT64);
|
||||
if (!is_scalar) {
|
||||
constant_tensor_proto.add_dims(length);
|
||||
}
|
||||
constant_tensor_proto.set_raw_data(values.data(), length * sizeof(int64_t));
|
||||
|
||||
// Add initializer into Graph.
|
||||
graph.AddInitializedTensor(constant_tensor_proto);
|
||||
|
||||
// Update the output arg shape.
|
||||
ONNX_NAMESPACE::TensorShapeProto new_shape;
|
||||
if (!is_scalar) {
|
||||
new_shape.add_dim()->set_dim_value(length);
|
||||
}
|
||||
arg_to_update->SetShape(new_shape);
|
||||
}
|
||||
|
||||
} // namespace
|
||||
|
||||
Status ShapeOptimizer::ApplyImpl(Graph& graph, bool& modified, int graph_level, const logging::Logger& logger)
|
||||
const {
|
||||
GraphViewer graph_viewer(graph);
|
||||
auto& order = graph_viewer.GetNodesInTopologicalOrder();
|
||||
|
||||
for (NodeIndex i : order) {
|
||||
auto* node = graph.GetNode(i);
|
||||
if (!node) {
|
||||
continue;
|
||||
}
|
||||
|
||||
if (!graph_utils::IsSupportedOptypeVersionAndDomain(*node, "Shape", {1, 13, 15})) {
|
||||
continue;
|
||||
}
|
||||
|
||||
ORT_RETURN_IF_ERROR(Recurse(*node, modified, graph_level, logger));
|
||||
|
||||
auto data_shape = node->MutableInputDefs()[0]->Shape();
|
||||
if (data_shape == nullptr) {
|
||||
SO_LOG_DEBUG_INFO(logger, "Shape node's data input shape is missing." + node->Name());
|
||||
continue;
|
||||
}
|
||||
|
||||
// Parse data input shape, fill -1 for symbolic dimensions.
|
||||
TensorShapeVector dim_values;
|
||||
dim_values.reserve(data_shape->dim_size());
|
||||
bool has_concrete_dim = false;
|
||||
for (int dim_index = 0; dim_index < data_shape->dim_size(); dim_index++) {
|
||||
auto dim = data_shape->dim(dim_index);
|
||||
if (utils::HasDimValue(dim)) {
|
||||
dim_values.push_back(dim.dim_value());
|
||||
has_concrete_dim = true;
|
||||
} else {
|
||||
// Fill with -1 for symbolic dimension.
|
||||
dim_values.push_back(-1);
|
||||
}
|
||||
}
|
||||
|
||||
if (!has_concrete_dim) {
|
||||
SO_LOG_DEBUG_INFO(logger, "No concrete dimension found, don't need try further." + node->Name());
|
||||
continue;
|
||||
}
|
||||
|
||||
InlinedVector<Node*> nodes_to_remove;
|
||||
TensorShapeVector fold_values;
|
||||
// Short path - check if the shape node can be constant folded.
|
||||
if (CanShapeNodeBeReplacedWithConstant(*node, dim_values, fold_values)) {
|
||||
SO_LOG_DEBUG_INFO(logger, "Shape node can be constant folded." + node->Name());
|
||||
UpdateNodeArgToConstant(graph, node->MutableOutputDefs()[0], fold_values);
|
||||
nodes_to_remove.push_back(node);
|
||||
} else {
|
||||
// Check consumers of Shape node, try best effort to constant fold them if possible.
|
||||
// Currently support Gather and Slice in some cases.
|
||||
auto p_ip_node = node->OutputNodesBegin();
|
||||
const auto p_ip_node_end = node->OutputNodesEnd();
|
||||
InlinedHashSet<const Node*> visited_nodes;
|
||||
while (p_ip_node != p_ip_node_end) {
|
||||
if (visited_nodes.find(&(*p_ip_node)) != visited_nodes.end()) {
|
||||
// Already handled, skip the node.
|
||||
++p_ip_node;
|
||||
continue;
|
||||
}
|
||||
|
||||
auto& output_node = *graph.GetNode(p_ip_node->Index());
|
||||
visited_nodes.insert(&output_node);
|
||||
++p_ip_node;
|
||||
|
||||
NodeArg* data_input = output_node.MutableInputDefs()[0];
|
||||
// Skip when shape is not used as sliced data.
|
||||
if (data_input != node->MutableOutputDefs()[0]) {
|
||||
continue;
|
||||
}
|
||||
|
||||
TensorShapeVector slice_fold_values;
|
||||
if (graph_utils::IsSupportedOptypeVersionAndDomain(output_node, "Slice", {10, 11, 13}) &&
|
||||
CanSliceNodeBeReplacedWithConstant(graph, output_node, dim_values, slice_fold_values)) {
|
||||
SO_LOG_DEBUG_INFO(logger, "Slice node can be constant folded." + output_node.Name());
|
||||
UpdateNodeArgToConstant(graph, output_node.MutableOutputDefs()[0], slice_fold_values);
|
||||
nodes_to_remove.push_back(&output_node);
|
||||
continue;
|
||||
}
|
||||
|
||||
int gather_output_rank = 0;
|
||||
TensorShapeVector gather_fold_values;
|
||||
if (graph_utils::IsSupportedOptypeVersionAndDomain(output_node, "Gather", {1, 11, 13}) &&
|
||||
CanGatherNodeBeReplacedWithConstant(graph, output_node, dim_values, gather_fold_values,
|
||||
gather_output_rank)) {
|
||||
SO_LOG_DEBUG_INFO(logger, "Gather node can be constant folded." + output_node.Name());
|
||||
UpdateNodeArgToConstant(graph, output_node.MutableOutputDefs()[0], gather_fold_values, gather_output_rank == 0);
|
||||
nodes_to_remove.push_back(&output_node);
|
||||
continue;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
for (Node* node_to_remove : nodes_to_remove) {
|
||||
// Remove single-output node chain for inputs of the node
|
||||
auto p_ip_node = node_to_remove->InputNodesBegin();
|
||||
const auto p_ip_node_end = node_to_remove->InputNodesEnd();
|
||||
while (p_ip_node != p_ip_node_end) {
|
||||
const auto& input_node = *p_ip_node;
|
||||
// Update the node iterator before removing the corresponding node because removing
|
||||
// the node will invalidate the node iterator
|
||||
++p_ip_node;
|
||||
|
||||
// Remove the node only when there is a single output edge or the node does not produce graph output.
|
||||
if (input_node.GetOutputEdgesCount() > 1 || graph.NodeProducesGraphOutput(input_node)) {
|
||||
SO_LOG_DEBUG_INFO(logger, "Skip removing node: " + input_node.Name() + "(" + input_node.OpType() + ")");
|
||||
continue;
|
||||
}
|
||||
SO_LOG_DEBUG_INFO(logger, "Removing node: " + input_node.Name() + "(" + input_node.OpType() + ")");
|
||||
graph_utils::RemoveNodesWithOneOutputBottomUp(graph, input_node);
|
||||
}
|
||||
|
||||
// Remove the output edges of the constant node and then remove the node itself.
|
||||
graph_utils::RemoveNodeOutputEdges(graph, *node_to_remove);
|
||||
|
||||
SO_LOG_DEBUG_INFO(logger, "Removing trigger node: " + node_to_remove->Name());
|
||||
graph.RemoveNode(node_to_remove->Index());
|
||||
modified = true;
|
||||
}
|
||||
}
|
||||
|
||||
return Status::OK();
|
||||
}
|
||||
|
||||
#undef NEED_SO_LOG_DEBUG_INFO
|
||||
#undef SO_LOG_DEBUG_INFO
|
||||
|
||||
} // namespace onnxruntime
|
||||
42
orttraining/orttraining/core/optimizer/shape_optimizer.h
Normal file
42
orttraining/orttraining/core/optimizer/shape_optimizer.h
Normal file
|
|
@ -0,0 +1,42 @@
|
|||
// Copyright (c) Microsoft Corporation. All rights reserved.
|
||||
// Licensed under the MIT License.
|
||||
|
||||
#pragma once
|
||||
|
||||
#include "core/optimizer/graph_transformer.h"
|
||||
|
||||
namespace onnxruntime {
|
||||
|
||||
/**
|
||||
@class ShapeOptimizer
|
||||
|
||||
Transformer that traverses the graph top-down and performs shape optimizations.
|
||||
|
||||
Try best to constant fold the output of the Shape node:
|
||||
1. Shape generates 1D tensor [12, 128, 512] (all dimensions have concrete dim value), which can be constant folded
|
||||
to an initializer including 1D tensor values [12, 128, 512]. (Some logic of ConstantFolding also does the same thing.)
|
||||
|
||||
2. Shape generates 1D tensor [batch_size, 128, 512] -> Slice(start=1,end=3), we can constant fold the Shape->Slice to
|
||||
an initializer including 1D tensor values [128, 512].
|
||||
|
||||
3. Shape generates 1D tensor [batch_size, 128, 512] -> Gather(axes=[0], index=[2]), we can constant fold the
|
||||
Shape->Gather to an initializer including 1D tensor values [512].
|
||||
|
||||
4. Shape since OPSET 15 takes input of shape [batch_size, 128, 512], slicing from 1 to 2(exclusive),
|
||||
we can constant fold the Shape(start=1,end=2) to an initializer including 1D tensor values [128].
|
||||
|
||||
This would help clean up the graph, and combined with ConstantFolding, the graph would be much more simplified.
|
||||
|
||||
*/
|
||||
class ShapeOptimizer : public GraphTransformer {
|
||||
public:
|
||||
ShapeOptimizer(
|
||||
const InlinedHashSet<std::string_view>& compatible_execution_providers = {}) noexcept
|
||||
: GraphTransformer("ShapeOptimizer", compatible_execution_providers) {
|
||||
}
|
||||
|
||||
private:
|
||||
Status ApplyImpl(Graph& graph, bool& modified, int graph_level, const logging::Logger& logger) const override;
|
||||
};
|
||||
|
||||
} // namespace onnxruntime
|
||||
1043
orttraining/orttraining/test/optimizer/shape_optimizer_test.cc
Normal file
1043
orttraining/orttraining/test/optimizer/shape_optimizer_test.cc
Normal file
File diff suppressed because it is too large
Load diff
Loading…
Reference in a new issue