Dynamic shapes was not working with serialized model so we are switching
to compile model method
### Motivation and Context
Dynamic shapes was not working with serialized model
- If it fixes an open issue, please link to the issue here. -->
Signed-off-by: MaajidKhan <n.maajid.khan@intel.com>
Co-authored-by: MaajidKhan <n.maajid.khan@intel.com>
### Description
Adds support for the LRN operator to QNN EP.
### Motivation and Context
Enables basic models like googlenet and alexnet to run entirely on QNN
EP.
### Description
<!-- Describe your changes. -->
js/react_native package dependency change to manage ort-extensions for
react-native app.
Enable optional inclusion of ort-ext aar/ ort-ext pods for react-native
extensions apps when specifiy `ortExtensionsEnabled` in user's
package.json file
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: rachguo <rachguo@rachguos-Mac-mini.local>
Co-authored-by: rachguo <rachguo@rachguos-Mini.attlocal.net>
### Description
<!-- Describe your changes. -->
-Add support for loading model from buffer on iOS
-Update OnnxruntimeModuleTest to use updated loadModelFromBuffer
Based on #12676
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Issue: #12500
---------
Co-authored-by: rachguo <rachguo@rachguos-Mini.attlocal.net>
Co-authored-by: rachguo <rachguo@rachguos-Mac-mini.local>
### Description
This PR adds `onnxruntime.transformers.models.whisper` to the wheel.
### Usage
There is a README.md document that shows sample commands. The following
command will show how to use the custom Whisper export script in more
detail.
```
$ python3 -m onnxruntime.transformers.models.whisper.convert_to_onnx --help
```
### Motivation and Context
This fixes an issue with adding the Whisper custom export scripts to the
wheel. The Whisper folder now appears in the wheel.

### Description
Cast optimizer may convert a fp16 node to fp32. This used to be safe as
all fp16 kernels has fp32 implementation. As this assumption is no
longer true, we need to check the validity of the operation
### Motivation and Context
Main work here is to introduce an API to check whether a kernel is
registered. Currently we don't have a way to do that without an operator
node. This needs to be augmented. We need to query whether a kernel is
registered by its property only, so that we can judge whether it is safe
to construct a node long before we actually do so.
…th-ort-leads-to-invalid-node-input-names
### Description
Fix issue where Quantizing DistilBERT models after optimizing with ORT
leads to invalid node input names
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Add infrastructure so it's easy for a user to add the ORT extensions
nuget package and register the custom ops for C# apps.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Need to be able to use extensions on mobile platforms with Xamarin/MAUI
### Description
fix download failure due to buffer change.
WebAssembly buffer may change (growth triggered by memory allocation)
during an async function call.
### Description
<!-- Describe your changes. -->
Add registration for DML reduce functions in opset 18.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Linnea May <linneamay@microsoft.com>
### Description
All our Windows build pipelines already uses cmake 3.26 except one
pipeline: QNN ARM64.
This PR does the same for Linux build pipelines.
### Motivation and Context
This change is related to #15704 .
### Description
This PR changes an EmbedLayerNormalization node's mask index output to
be an optional output if a mask input is not provided.
### Motivation and Context
The documentation for EmbedLayerNormalization states
```
The last input mask is optional. If mask is provided, mask index (that is position of first 0 in mask, or number of words) will be calculated.
```
However, if the mask input is not provided, the mask index output is
still calculated and required.
### Description
Extend the AllGather op to support perform allgather on different axis.
provide the implementation in nccl kernels.
### Motivation and Context
We hit some scenario in distributed inference that we need to support
gather on non-first axis.
---------
Co-authored-by: Cheng Tang <chenta@microsoft.com@orttrainingdev9.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Wei-Sheng Chin <wschin@outlook.com>
### Description
- Update to QNN SDK 2.9.0 for QNN pipelines
- Temporarily disable warnings as errors for QNN Windows x64 pipeline
- Note that this pipeline did not previously run to completion. It also
currently does not run for pull requests.
### Motivation and Context
Need to update and test the latest available version of the QNN SDK.
The PR is to allow custom op of different input types to have same op
name in a graph.
The idea to go over all ops of same name and merge their input/output
types into a type-inference function.
With the enhancement, custom op node inside a graph can have same
op-type given that the input/output types are different.
---------
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
Rename onnxruntime-Linux-CPU-2019 machine pool to
"onnxruntime-Ubuntu2004-AMD-CPU". The old one has an internal error and
stuck there. I cannot make any change to it. It has been like this for
more than 1 week. So I created a new pool with the same setting except
the name is different.
Also, move some android pipelines to
"onnxruntime-Linux-CPU-For-Android-CI" which uses a standard image from
https://github.com/actions/runner-images
### Description
In #8953 I introduced a change in our onnxruntime_mlas.cmake that it
enables "ASM_MASM" cmake language for all Windows build.
```cmake
enable_language(ASM_MASM)
```
Before the change, it is only enabled when onnxruntime_target_platform
equals to x64.
However, cmake 3.26 added a new language: ASM_MARMASM.
According to cmake's manual,
ASM_MASM is for Microsoft Assembler
ASM_MARMASM is for Microsoft ARM Assembler. This one is new in cmake
3.26.
We should choose the right one according to
${onnxruntime_target_platform}.
### Description
* Update TensorRT 8.6 lib dependencies in dockerfile of TRT EP Perf
pipeline
* Avoid using `--allow_running_as_root` and build ORT with non-root user
### Motivation and Context
To fix the build issue on EP perf pipeline
Fixed
[AB#14615]
The follow code shows ROCm EP FusedConv produce incorrect results:
```py
import numpy as np
import onnx
import onnxruntime as ort
X = onnx.helper.make_tensor_value_info("input", onnx.TensorProto.FLOAT, [1, 64, 55, 55])
a = onnx.helper.make_tensor_value_info("tmp", onnx.TensorProto.FLOAT, [1, 64, 55, 55])
Y = onnx.helper.make_tensor_value_info("output", onnx.TensorProto.FLOAT, [1, 64, 55, 55])
weight_data = np.random.random([64, 64, 1, 1]).astype(np.float32)
weight1 = onnx.helper.make_tensor("weight1", onnx.TensorProto.FLOAT, [64, 64, 1, 1], weight_data)
bias_data = np.random.random(64).astype(np.float32)
bias1 = onnx.helper.make_tensor("bias1", onnx.TensorProto.FLOAT, [64], bias_data)
weight_data = np.random.random([64, 64, 1, 1]).astype(np.float32) # <------ comment out
weight2 = onnx.helper.make_tensor("weight2", onnx.TensorProto.FLOAT, [64, 64, 1, 1], weight_data)
bias_data = np.random.random(64).astype(np.float32) # <------ comment out
bias2 = onnx.helper.make_tensor("bias2", onnx.TensorProto.FLOAT, [64], bias_data)
node1 = onnx.helper.make_node("FusedConv", inputs=[X.name, weight1.name, bias1.name], outputs=[a.name], domain="com.microsoft", kernel_shape = [1,1], activation="Relu")
node2 = onnx.helper.make_node("FusedConv", inputs=[a.name, weight2.name, bias2.name], outputs=[Y.name], domain="com.microsoft", kernel_shape = [1,1], activation="Relu")
graph = onnx.helper.make_graph([node1, node2], "Graph", [X], [Y], initializer=[weight1, bias1, weight2, bias2])
model = onnx.helper.make_model(graph, producer_name="tmp", opset_imports=[
onnx.helper.make_opsetid('com.microsoft', 1),
onnx.helper.make_opsetid('ai.onnx.ml', 1),
onnx.helper.make_opsetid('', 14),
])
sess0 = ort.InferenceSession(model.SerializeToString(), providers=["CPUExecutionProvider"])
sess1 = ort.InferenceSession(model.SerializeToString(), providers=["ROCMExecutionProvider"])
ref = sess0.run(["output"], {"input" : 0.05 * np.ones([1, 64, 55, 55], dtype=np.float32)})[0]
our = sess1.run(["output"], {"input" : 0.05 * np.ones([1, 64, 55, 55], dtype=np.float32)})[0]
print(ref - our)
```
The root cause is that fusion args is cached together with fusion plan.
It seems that internal to MIOpen, the `miopenOperatorArgs_t` handle is
copied directly to execution engine, instread of the content of a
`miopenOperatorArgs_t`. If two ORT `OpKernel`s have the same conv kernel
spatial dimension and strides, etc, we then get the same hash for the
fusion plan, thus we also get the same fusion args handle. Then the
second node of `FusedConv` may modify the fusion args on the fly when it
is still pending execution for first node of `FusedConv` internal to
MIOpen. This PR moves the fusion args out of fusion plan cache to avoid
the problem.
### Fold shape related operation at best efforts.
This is a follow up for PR
https://github.com/microsoft/onnxruntime/pull/12561.
Create a specialized shape_optimzer to constant fold shape related
operation.
ShapeOptimizer at the best efforts to constant fold the dim values that
exists from shape inferencing. This is helpful to simplify the graph,
which on the other hand, help other graph transformers to do more.
Transformer that traverses the graph top-down and performs shape
optimizations.
Try the best effort to constant fold the shape related to Shape node
outputs:
1. Shape generates 1D tensor [12, 128, 512] (all dimensions have
concrete dim value), which can be constant folded
to an initializer including 1D tensor values [12, 128, 512]. (Some logic
of ConstantFolding also does the same thing.)
2. Shape generate 1D tensor [batch_size, 128, 512] ->
Slice(start=1,end=3), we can constant fold the Shape->Slice to
an initializer including 1D tensor values [128, 512].
3. Shape generate 1D tensor [batch_size, 128, 512] -> Gather(axes=[0],
index=[2]), we can constant fold the
Shape->Gather to an initializer including 1D tensor values [512].
4. Shape 15 takes input of shape [batch_size, 128, 512], slicing from 1
to 2(exclusive), we can constant fold the
Shape15(start=1,end=2) to an initializer including 1D tensor values
[128].
This would help clean up the graph, combined with ConstantFolding, the
graph would be much more simplified.
### Motivation and Context
One direct motivation to have this is, we have a model subgraph like
this:
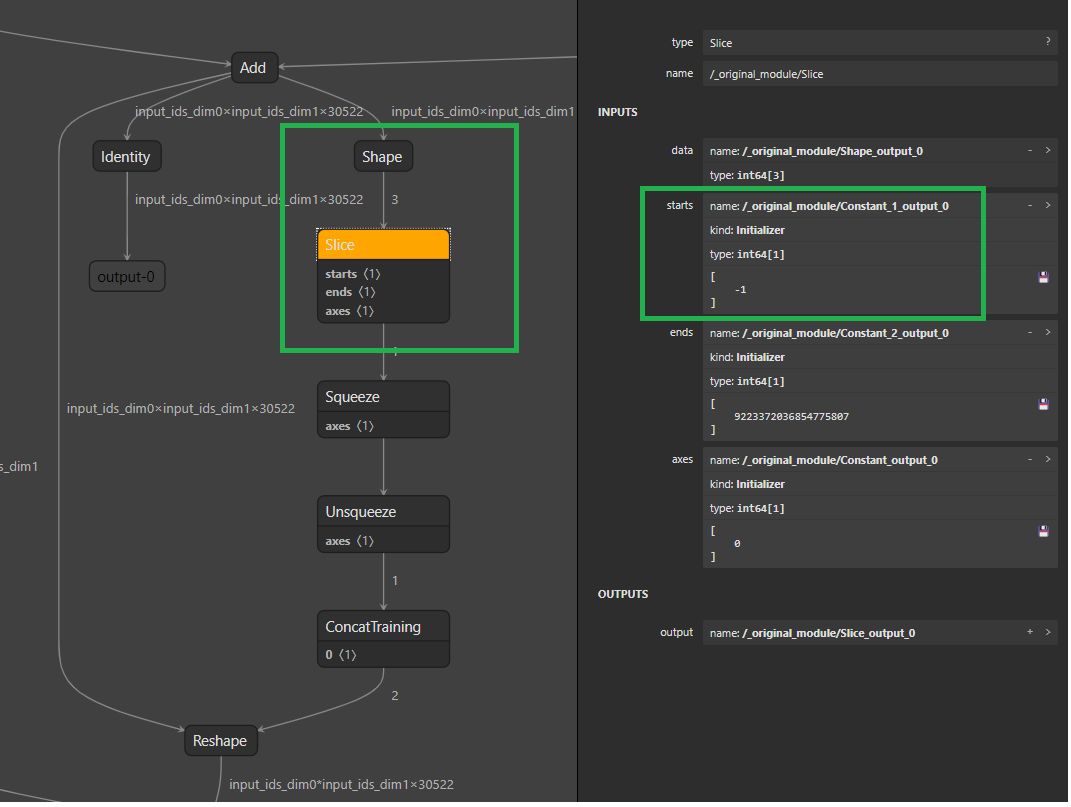
The subgraph in the green rectangle is trying to get the value `30522`,
with the changes in this PR, the subgraph will be constant folded. Plus
ConstantFolding optimizer will further to optimize out the subsquent
`Squeeze`/`Unsqueeze`/`ConcatTraining`, then we will have a clean very
clean Reshape node, with its shape input be an constant `[-1, 20522]`.
Having this simplified graph, our other compute optimizer can help
further optimize the graph by re-ordering gather/reshape nodes.
### Description
Add parameters to make some stages could use other run's intermediate
output.
### Motivation and Context
nuget workflow has 38 stages of 4 layers.
We had to run the whole workflow from begining to test one stage.
It could make life easier to run only one stage for testing.
like
### N.B.
In this PR, Nuget_Test_Linux_CPU, Nuget_Test_LinuxGPU and
Jar_Packaging_GPU are enabled as the first step.
So I can start to move tests from Linux host to container
Adds skip for MIGraphX EP builds for Packed KV and QKV tests in
Multi Head attention. As it is not supported and causes CI failures
when building and testing EPs
---------
Co-authored-by: Ted Themistokleous <tthemist@amd.com>
### Description
The BufferUniquePtrs in the old code doesn't have knowledge of the
allocator where the allocated memory was from, so it cannot free the
memory.
### Description
<!-- Describe your changes. -->
Reland previous reverted changes for loading model from buffer - Android
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
#13903
---------
Co-authored-by: rachguo <rachguo@rachguos-Mac-mini.local>
Co-authored-by: rachguo <rachguo@rachguos-Mini.attlocal.net>
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
DML's MVN metacommand needs all axes except for batch and channel to be
reduced. By adding trailing dimensions of 1's and their corresponding
axes, the operation stays the same but we are now able to call
metacommands.
### Description
In 2021 we restricted onnx node test CI execution in range of opset
14-15 for ORT-TRT, which was the latest opset that TRT EP could support
Update this range to opset 14-17 to improve the ORT-TRT unit test
coverage, as [Nvidia announced that TRT 8.6 supported
opset17](https://github.com/onnx/onnx-tensorrt/blob/main/docs/operators.md)
### Description
This PR adds the Whisper custom export scripts to the wheel.
### Motivation and Context
This enables access to the custom export scripts in the wheel.
### Description
* Reverting default TensorRT version to 8.5 as temporary fix
* Apart from that, this PR temporarily leaves this CI as a place to
validate user behavior that uses TRT 8.5 with latest ORT
### Context
* This CI pool equips 2xTesla M60 GPUs, which are no longer supported by
TensorRT 8.6.
* Currently, other CIs are using single-T4 VM but there's no VM with
2xT4 or other suitable dualGPU in the range.
* Once we decide which VM instance for this CI to migrate to, TRT8.6 can
be enabled on this CI
* According to
[Nvidia](https://docs.nvidia.com/deeplearning/tensorrt/release-notes/index.html):
* TensorRT 8.5.3 was the last release supporting NVIDIA Kepler (SM 3.x)
and NVIDIA Maxwell (SM 5.x) devices. *These devices are no longer
supported in TensorRT 8.6*. NVIDIA Pascal (SM 6.x) devices are
deprecated in TensorRT 8.6.
### Description
This PR resolves a part of non-critical comments from code review
comments in #14579.
- use `USE_JSEP` instead of `USE_JS` in build definition to make it less
ambiguous
- remove unused util functions from util.ts
- fix transpose.h
- other misc fixes
### Description
The PR adds VPU support to OpenVINO Execution Provider
Bug fixes for GPU, CPU.
Changes to OpenVINO Backend in Serialized Model API for faster First
Inference Latency.
Deprecation to HDDL-VADM and MYRIAD, removed code
Support OpenVINO 2023.0
Dynamic Shapes Support for iGPU
### Motivation and Context
- VPU is an upcoming hardware that can provide AI Acceleration for
Client Systems through OpenVINO
- If it fixes an open issue, please link to the issue here. -->
---------
Signed-off-by: MaajidKhan <n.maajid.khan@intel.com>
Co-authored-by: Suryaprakash Shanmugam <suryaprakash.shanmugam@intel.com>
Co-authored-by: MaajidKhan <n.maajid.khan@intel.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}