### Description
1. Move it to a separated pool that use the same image as [the public
hosted
pool](https://learn.microsoft.com/en-us/azure/devops/pipelines/agents/hosted?view=azure-devops&tabs=yaml).
Also, create a beta pool which contains the next version image of the
hosted pool, and add jobs in our post merge pipeline to test if the next
version image will break our CI. So, usually we will have at least one
week to prepare.
2. Change the cmake generator in use in our pipelines from "Ninja" to
"MingW Makefile", because the latest version of cmake doesn't work with
the latest version of Ninja. People who prefer Ninja could still use
ninja in their local build by passing "--cmake_generator ninja" to
[build.py](https://github.com/microsoft/onnxruntime/blob/main/tools/ci_build/build.py).
3. Delete eager mode CI pipeline.
### Motivation and Context
I need to update the software we have in our CI build machines, and I
need to resolve this incompatibility issue. In more detail, the build
error I hit was:
em++: error:
CMakeFilesonnxruntime_mlas_test.dirC_a_work1sonnxruntimetestmlasunittesttest_activation.cpp.o:
No such file or directory
("CMakeFilesonnxruntime_mlas_test.dirC_a_work1sonnxruntimetestmlasunittesttest_activation.cpp.o"
was expected to be an input file, based on the commandline arguments
provided)
After this PR we will deprecate python 3.7 support. The eager mode CI
pipeline is the last one that still use python 3.7. Then we can rework
the PR #10953 made by [fs-eire](https://github.com/fs-eire) last year.
Fixed
[AB#14435](https://aiinfra.visualstudio.com/6a833879-cd9b-44a4-a9de-adc2d818f13c/_workitems/edit/14435)
### Description
Adds VIT model type to the benchmark
Also adds Swin (v1) model type
### Motivation and Context
Image models are important and we should verify these work as expected
at the performance we expect.
**Description**: Register an implementation for BatchNormInternal and
add a CPU kernel for BatchNormGradient. This is the third in a series of
PRs to implement BN training on CPU (first was #6946, second was #7539).
**Motivation and Context**
Support training networks with BatchNorm (e.g. convnets). Also note that
there exists a CUDA kernel for BN (forward training & backwards) but
it's currently disabled due to flaky failures; someone more familiar
with those parts can register the implementation for BNInternal on CUDA
(gradient kernel doesn't have to change).
---------
Co-authored-by: Simon Zirui Guo <simonguozirui@berkeley.edu>
Co-authored-by: mindest <linminuser@gmail.com>
Co-authored-by: mindest <30493312+mindest@users.noreply.github.com>
### Description
<!-- Describe your changes. -->
Update the support deepspeed to 0.8.3 as it's the latest version
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This will fix the error of `Skip modifying optimizer because of
unsupported DeepSpeed version`
Co-authored-by: ruiren <ruiren@microsoft.com>
Add workflow to update Objective-C API docs. Remove the Objective-C API doc generation step from the packaging pipeline.
There are similar workflows for automatically updating other language API docs. This change enables this for Objective-C too.
Ensure that we build with a known version of NDK and are not surprised when the default version on the build machine changes.
A similar change was made for other Android build pipelines previously, but this one was missed.
### Description
Fix onnxruntime_mlas build failure with cmake 3.26. Updated CMAKE
generator expression to make sure certain complier flags only apply for
C/CXX compiler.
### Motivation and Context
CMake changed the behavior of ASM_MASM in version 3.26. See
https://gitlab.kitware.com/cmake/cmake/-/issues/24639.
This also fixed the issue of #15101
### Description
Adds support for the AveragePool operator to QNN EP.
### Motivation and Context
This is needed to enable more models to run with QNN EP.
### Description
Adding 'Add' functionality to FP16 Conv operator. It takes a tensor that
has the same shape of the output tensor, and add it to the result
tensor.
### Motivation and Context
Needed to run Resnet 50
### Description
Fix issue in LeakyRelu Opbuilder for HTP backend.
Qnn Prelu(Onnx LeakyRelu) requires alpha data as the 2nd input while
Onnx set it as attribute. HTP backend requires input to be quantized. It
caused Qnn Op validation failed by setting the 2ns input as float32 data
type.
Fix:
Need to set the 2nd input as quantized input for HTP backend. Calculate
the quantization parameter and quantize the alpha data into uint8.
### Motivation and Context
Unblock models with the LeakyRelu execution on QualComm HTP backend.
### Introduce shrunken gather operator
Exist Gather operator schema won't guarantee output element count will
be smaller than input element count.
Actually, it is possible output element count >, =, or < input element
count.
For some cases we know for sure output element count MUST be <= input
element count, we will upstream those Gather operators to reduce compute
flops.
So this PR introduces an ShrunkenGather which explicitly guarantee
output count will be smaller than input count. The operator add
additional restriction on inputs, but still re-use existing Gather's
implementations plus input check during runtime.
This is a requirement for subsequent optimization (Draft PR:
https://github.com/microsoft/onnxruntime/pull/15401) we will do for
label sparsity and embedding sparsity.
### Description
- Now uses QNN's Resize operator for quantized models
- Still uses QNN's ResizeBilinear or ResizeNearestNeighbor for
non-quantized models.
### Motivation and Context
This update is necessary to support more models on QNN HTP backend.
Specifically, we need to support Resize's `pytorch_half_pixel`
coordinate transformation mode on HTP.
### Description
1. The protoc package on nuget.org contains binaries for
Windows_x86/Windows_x64/Linux_x86/Linux_x64/MacOS_x64, which can cover
most use cases. Though it doesn't have binaries for AMR64, they are only
needed when we cross-compile for Intel CPUs on ARM CPUs. It is rare.
When you have such a need, you always can build protoc from source by
yourself and pass it to build.py as "--path_to_protoc_exe". Or if you
have security concerns that you don't want to use prebuilt binaries from
outside, you can do the same thing.
2. Remove GoogleTestAdapter related thing. That part of code is out of
maintain.
### Motivation and Context
As a follow-up of PR #15190.
### Description
Apply `get_shared_initializers()` to the encoder and decoder subgraphs
of Whisper before chaining and exporting the full, final model.
### Motivation and Context
The Whisper export process has some overlap between the encoder and
decoder subgraphs due to the format of the BeamSearch contrib op.
Consequently, there is some shared model data that is duplicated in the
final exported product, which can result in a file size increase of
~40%. This PR takes the methods in `convert_generation.py` and applies
them during the whisper export process.
---------
Co-authored-by: Peter McAughan <petermca@microsoft.com>
### Description
Update mimalloc dependency.
### Motivation and Context
The latest release contains important fixes including memory leaks and
used by customers.
### Description
The current ONNX export of Whisper utilizes hard-coded values for
token_ids when configuring the BeamSearch node. This PR removes these
literals and instead takes these values straight from the WhisperConfig.
### Motivation and Context
Hard-coding these values can cause some parity issues when comparing to
default PyTorch behavior - this change to take from WhisperConfig
resolves these.
Co-authored-by: Peter McAughan <petermca@microsoft.com>
WindowsAI build failing due to deprecated .NET5 SDK missing in build
image
.NET5 was deprecated last year, and recently the build machine images
have been updated to not include this SDK.
Unblock failing builds by force insalling .NET5 SDK as part of the build
pipeline.
### Description
XNNPack: allow users to choose whether enable CPU MEM arena or not.
Right now it is hardcoded to true and it is not impacted by the on/off
switch in SessionOption. We should make it work.
### Motivation and Context
As we have such a switch in SessionOption, it should work as expected.
Split `IsTunbaleOpEnable` semantics into **enable tunable op for using**
and **enable tunable op for tuning**.
They remain disabled in general for safety purpose. But
- if session is created with onnx model with tuning results embeded
- the embedded tuning results is set to the EP without error `Status`
then we automatically enable the using, tuning remains disabled.
The planned options will be
- `tunable_op_enable`: The top-level switch of `TunableOp`, indicate if we will run into `TunableOp` related logic. **NOTE:** most of our impls have a bottom impl that is acting as a fallback and is set as the default. In this case, we still call into the `TunableOp`, but no kernel selection, no kernel tuning and caching is involved. This reduced our maintainance burden of a duplicate code path.
- `tunable_op_tuning_enable`: The secondary switch of `TunableOp`, indicate if we will run into the tuning related logic of `TunableOp`
Then for the possible future options:
- `tunable_op_tuning_max_iteration`: blahblah
- `tunable_op_tuning_max_duration_ms`: blahblah
- `tunable_op_flash_attention_enable`: blahblah, for example only, we will not have this.
For developer oriented envvar, it is for developers' convenience to inspect the performance impact of tuning. So there is only `ORT_ROCM_TUNABLE_OP_ENABLE`, `ORT_ROCM_TUNABLE_OP_TUNING_ENABLE` to take the fine-grind control of combinations.
### Description
Upgrade remainding python to 3.11 removing 3.7
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Allows the creation of zero length tensors via the buffer path (the
array path with zero length arrays still throws as the validation logic
to check it's not ragged would require more intrusive revision), and
allows the `tensor.getValue()` method to return a Java multidimensional
array with a zero dimension. Also added a test for the creation and
extraction behaviour.
### Motivation and Context
The Python interface can return zero length tensors (e.g. if object
detection doesn't find any objects), and before this PR in Java calling
`tensor.getValue()` throws an exception with a confusing error message.
Fixes#7270 & #15107.
### Description
<!-- Describe your changes. -->
Add clog back to onnxruntime_EXTERNAL_LIBRARIES.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Fix iOS packaging pipeline build failure.
### Description
Register Resize op into nhwc schema for Qnn EP.
### Motivation and Context
Resize op is identified as layout sensitive op for Qnn EP, need to
register it into nhwc schema
Change the default behavior to link against the nvonnxparser library
(onnx-tensorrt parser) that is included with the TensorRT package.
Previously, the default behavior was to build and statically link
against the OSS onnx-tensorrt parser.
Historically, we wanted to incorporate the latest commits/fixes from OSS
parser.
These days the OSS parser is not significantly different from the
included parser library so there is less reason to build against it by
default.
By linking with parser shared library from TensorRT library, the major
benefit is it's much easier to
build/link against a minor version update of TensorRT. And OnnxRuntime
can be updated with a new TensorRT minor version by simply replacing
TensorRT libraries with the newer version. (because the parser is no
longer statically linked into onnxruntime)
Added --use_tensorrt_oss_parser to build.py to support the previous
default behavior. (build + static link OSS parser)
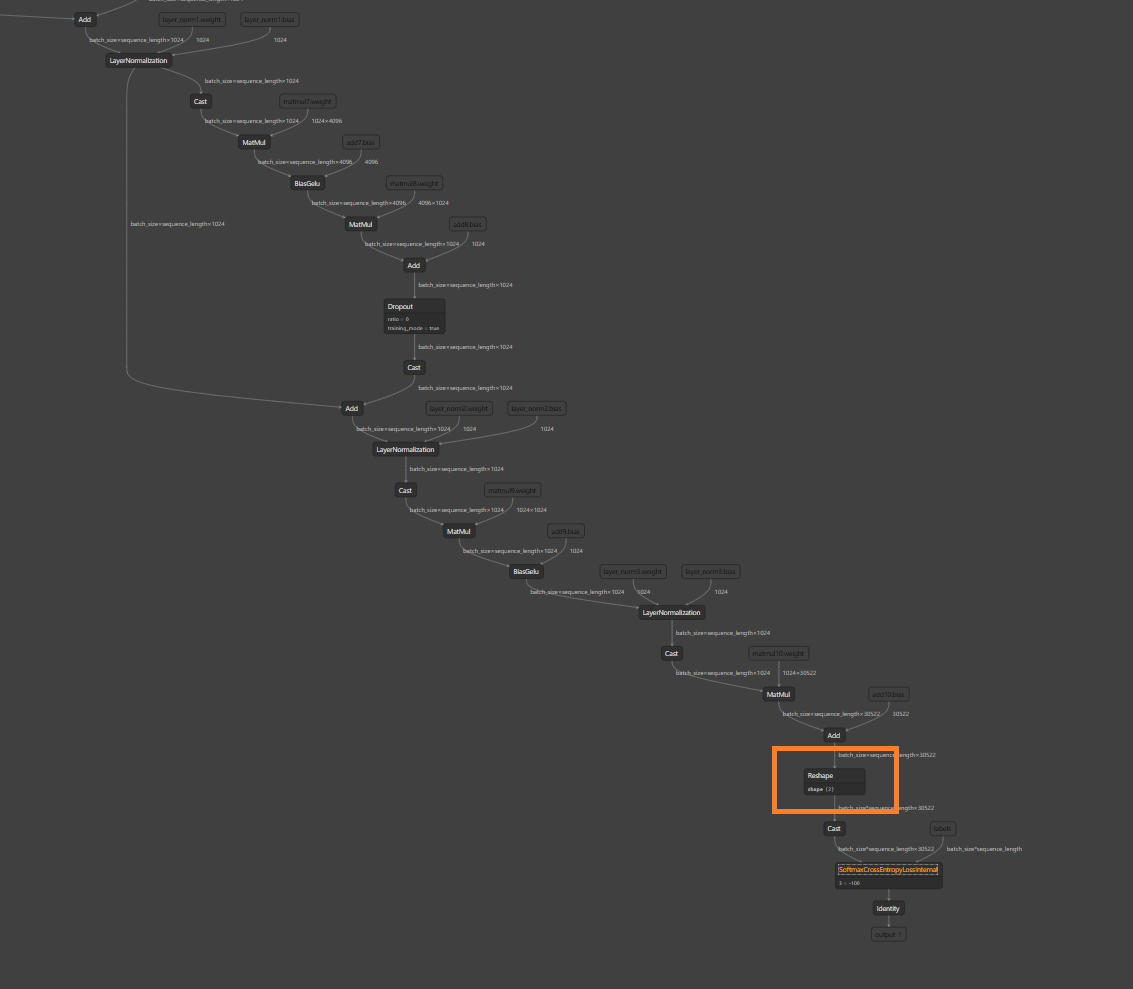
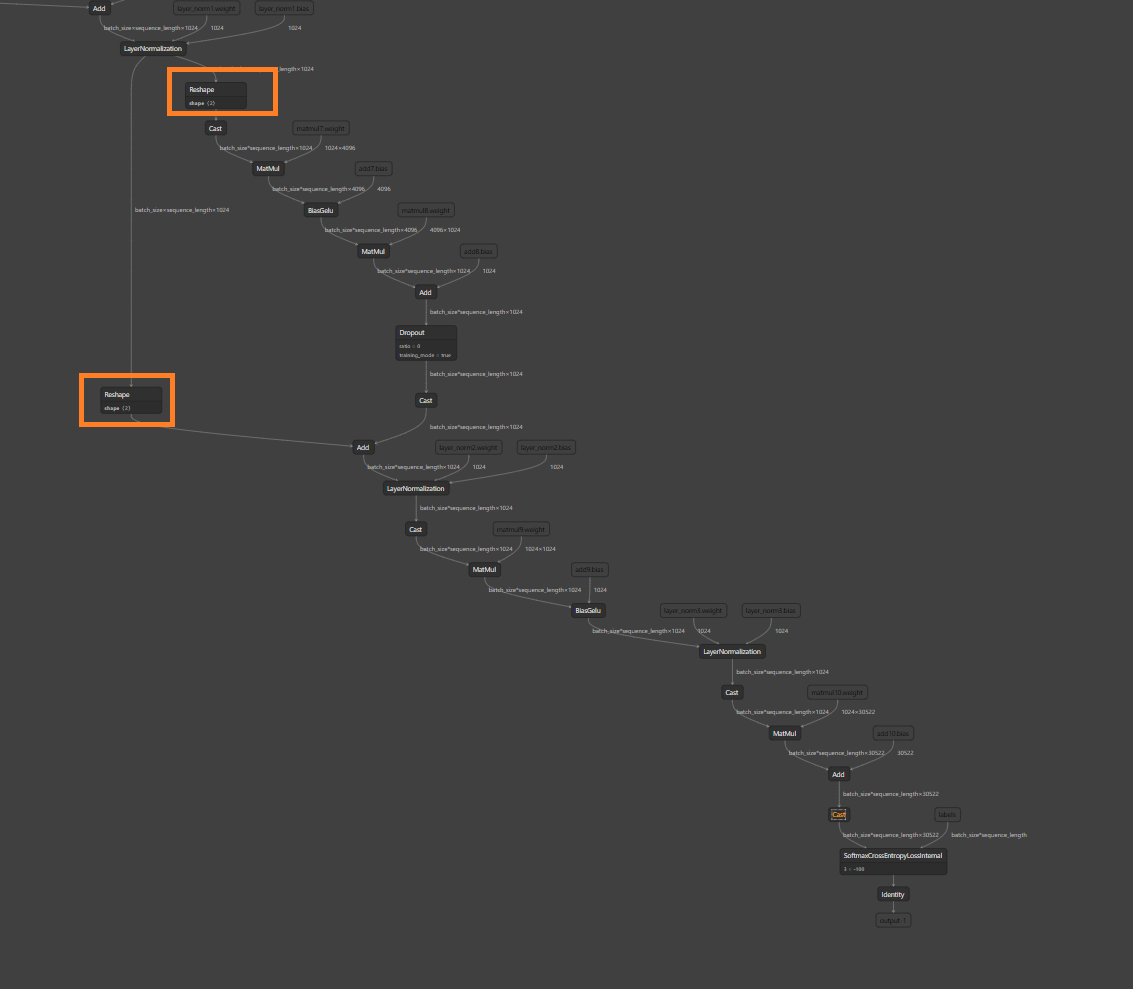
Add support for ViT optimization in optimizer.py
As ViT architecture follows BERT rather closely, we can easily reuse
BERT fusions for ViT. The only difference is that ViT does not have
attention mask, which means there is no Add node in qk paths.
Make the necessary changes in onnx_exporter.py to be able to cover
optimizations with test.
{kind=link}
{kind=link}