### Description
Fix bugs of Layernorm Fusion.
More checks on ReduceMean axes
separate out layernorm transform_test
### Motivation and Context
Our layernorm fusion pattern works only for axis=-1 currently.
- For training senario: The pattern produced error results directly as
they didn't handle "axes" and only assumed it's the default vaue.
- For Inference:
~~We lost some oppotunities to fuse layernrom. ~~
ReduceMean has default axes 0 which means reduce on all dimensions
**Description**:
This PR intends to enable WebNN EP in ONNX Runtime Web. It translates
the ONNX nodes by [WebNN
API](https://webmachinelearning.github.io/webnn/), which is implemented
in C++ and uses Emscripten [Embind
API](https://emscripten.org/docs/porting/connecting_cpp_and_javascript/embind.html#).
Temporarily using preferred layout **NHWC** for WebNN graph partitions
since the restriction in WebNN XNNPack backend implementation and the
ongoing
[discussion](https://github.com/webmachinelearning/webnn/issues/324) in
WebNN spec that whether WebNN should support both 'NHWC' and 'NCHW'
layouts. No WebNN native EP, only for Web.
**Motivation and Context**:
Allow ONNXRuntime Web developers to access WebNN API to benefit from
hardware acceleration.
**WebNN API Implementation Status in Chromium**:
- Tracked in Chromium issue:
[#1273291](https://bugs.chromium.org/p/chromium/issues/detail?id=1273291)
- **CPU device**: based on XNNPack backend, and had been available on
Chrome Canary M112 behind "#enable-experimental-web-platform-features"
flag for Windows and Linux platforms. Further implementation for more
ops is ongoing.
- **GPU device**: based on DML, implementation is ongoing.
**Open**:
- GitHub CI: WebNN currently is only available on Chrome Canary/Dev with
XNNPack backend for Linux and Windows. This is an open to reviewers to
help identify which GitHub CI should involved the WebNN EP and guide me
to enable it. Thanks!
### Description
Fp16 FusedConv and NhwcFusedConv. Fused Add operator should be performed
BEFORE the activation operator.
### Motivation and Context
Previous understanding of fused conv is incorrect.
### Add CPU allocation test for non-CPU devices distributed run
When CUDA EP is enabled in distributed training, CPU memory is still
used for some node output. Early we have distributed run test coverage,
but don't cover the case when some of the node are using CPU devices for
storing tensor output. As a result, I recalled we hit regression twice
in the passing months:
- https://github.com/microsoft/onnxruntime/pull/14050
- https://github.com/microsoft/onnxruntime/pull/15823
So adding this test to avoid future regressions.
The test graph looks like this:
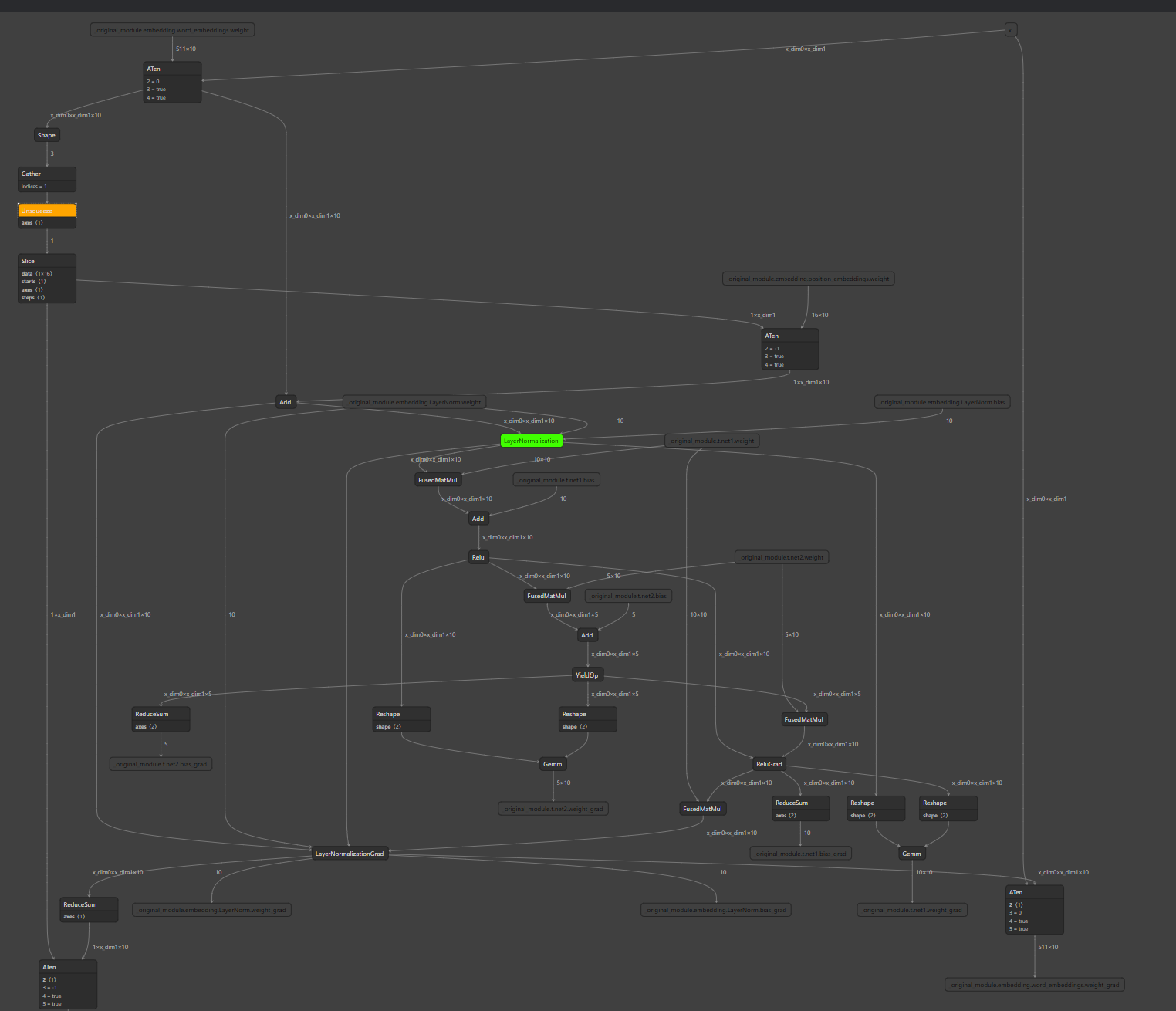
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Identified the cause for a `redefinition compilation error` happened in
a react native expo app with ort-extensions enabled when running the ios
side. Fix the include path now, so we can remove the temporary forward
declaration in OnnxruntimeModule.mm file.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Fix implementation detail.
---------
Co-authored-by: rachguo <rachguo@rachguos-Mini.attlocal.net>
### Description
When node output is optional, symbolic shape infer might add an empty
value_info item. Add some checking to avoid this.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
-
Stable diffusion optimized model reported invalid data type 0 during
inference.
### Description
Fix the bug in #15693
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Added changes to MIGraphX EP to suppoert stable diffusion
1. Added parameterized input dimensions to not trigger a precompile to
set input parameters in the EP
2. Removed input checking for Resize operator in EP as MIGraphX already
performs these checks
3. Add support to benchmark script to use the MIGraphX execution
provider
4. Add support for an odd valued batch size (3) that was seen on other
benchmarks we were performing comparison on.
### Motivation and Context
These changes are required to get stable diffusion mdoels to run on
MIGraphX through the EP. Without these changes we see the following
incorrect behavior.
1. Resize operators are pushed onto the CPU EP instead of MIGraphX,
causing a significant slowdown during runs
2. Precompile operations incorrectly parse input_ids parameter for our
text model, with a 1, which breaks during MIGraphX Compile of onnx. This
in turn throws an error and stops any setup before inference.
3. Selecting the correct EP in the benchmark script which was previously
missing the MIGraphX option
5. Suppressed an error we keep seeing with pthread_set_affinity - this
is a quality of life change when using the MIGraphX EP
This was testing with the benchmark.py script using stable diffusion v2
located in
onnxruntime/onnxruntime/python/tools/transformers/models/stable_diffusion/
---------
Co-authored-by: Ted Themistokleous <tthemist@amd.com>
### Fix segfault for multiple GPU run
https://github.com/microsoft/onnxruntime/pull/15618 introduced
`GetOrtDeviceByMemType`. The intention should be: handle CPU device
differently in the if branch, while might by mistakenly passing the
unique default non-cpu device id.
```
OrtDevice CUDAExecutionProvider::GetOrtDeviceByMemType(OrtMemType mem_type) const {
if (mem_type == OrtMemTypeCPUInput || mem_type == OrtMemTypeCPUOutput) {
return OrtDevice(OrtDevice::CPU, OrtDevice::MemType::CUDA_PINNED, default_device_.Id());
}
return default_device_;
}
```
We observed a segement fault thrown when running multiple GPU training
`
CUDA_LAUNCH_BLOCKING=1 python -m torch.distributed.launch
--nproc_per_node=2
examples/onnxruntime/training/language-modeling/run_mlm.py
--model_name_or_path distilbert-base-uncased --dataset_name wikitext
--dataset_config_name wikitext-2-raw-v1 --num_train_epochs 10
--per_device_train_batch_size 8 --per_device_eval_batch_size 8
--do_train --do_eval --overwrite_output_dir --output_dir ./outputs222/
--seed 1137 --fp16 --report_to none --optim adamw_ort_fused --max_steps
400 --logging_steps 1
`
It is found GPU0 works fine, GPU1 throw segement fault. Looking further,
a Shape node trying to allocate it's output tensor, trying to fetch
corresponding allocator with ORTDevice(Device:[DeviceType:0 MemoryType:1
DeviceId:1]), while CPU device did not have device id = 1, so a no
allocator returned. When we try to call `AsStreamBasedAllocator` for the
allocator, segement happens as no null check was done there.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
- Updates the default QNN SDK for CI pipelines to version 2.10.0.
- Disables convolution op tests that run on the QNN CPU backend due to a
potential bug with QNN SDK 2.10.0.
### Motivation and Context
Allows us to test the latest QNN SDK in default CI pipeline runs.
### Description
<!-- Describe your changes. -->
Various fixes to the CSharp setup
- fix warnings
- fix invalid tests
- update test sdk nuget package
- enables testing on linux
- fixes issue with some unit tests not running in CI
- run unit tests in linux pipeline using dotnet
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Unit tests weren't breaking in CIs for both Windows and Linux builds and
should have been.
### Description
Fix two errors that is only encountered on windows
### Motivation and Context
For onnxruntime::VitisAIProviderFactoryCreator::Create, it would cause
the compile error.
For if (it == provider_options_map.end()), it would cause an error but
execute as normal
Co-authored-by: Zhang <yueqingz@amd.com>
Bumps [engine.io](https://github.com/socketio/engine.io) from 6.4.1 to
6.4.2.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/socketio/engine.io/releases">engine.io's
releases</a>.</em></p>
<blockquote>
<h2>6.4.2</h2>
<p>⚠️ This release contains an important security fix
⚠️</p>
<p>A malicious client could send a specially crafted HTTP request,
triggering an uncaught exception and killing the Node.js process:</p>
<pre><code>TypeError: Cannot read properties of undefined (reading
'handlesUpgrades')
at Server.onWebSocket (build/server.js:515:67)
</code></pre>
<p>Please upgrade as soon as possible.</p>
<h3>Bug Fixes</h3>
<ul>
<li>include error handling for Express middlewares (<a
href="https://redirect.github.com/socketio/engine.io/issues/674">#674</a>)
(<a
href="93957828be">9395782</a>)</li>
<li>prevent crash when provided with an invalid query param (<a
href="fc480b4f30">fc480b4</a>)</li>
<li><strong>typings:</strong> make clientsCount public (<a
href="https://redirect.github.com/socketio/engine.io/issues/675">#675</a>)
(<a
href="bd6d4713b0">bd6d471</a>)</li>
<li><strong>uws:</strong> prevent crash when using with middlewares (<a
href="8b22162903">8b22162</a>)</li>
</ul>
<h3>Credits</h3>
<p>Huge thanks to <a
href="https://github.com/tyilo"><code>@tyilo</code></a> and <a
href="https://github.com/cieldeville"><code>@cieldeville</code></a> for
helping!</p>
<h4>Links</h4>
<ul>
<li>Diff: <a
href="https://github.com/socketio/engine.io/compare/6.4.1...6.4.2">https://github.com/socketio/engine.io/compare/6.4.1...6.4.2</a></li>
<li>Client release: -</li>
<li>ws version: <a
href="https://github.com/websockets/ws/releases/tag/8.11.0">~8.11.0</a>
(no change)</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/socketio/engine.io/blob/main/CHANGELOG.md">engine.io's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/socketio/engine.io/compare/6.4.1...6.4.2">6.4.2</a>
(2023-05-02)</h2>
<p>⚠️ This release contains an important security fix
⚠️</p>
<p>A malicious client could send a specially crafted HTTP request,
triggering an uncaught exception and killing the Node.js process:</p>
<pre><code>TypeError: Cannot read properties of undefined (reading
'handlesUpgrades')
at Server.onWebSocket (build/server.js:515:67)
</code></pre>
<p>Please upgrade as soon as possible.</p>
<h3>Bug Fixes</h3>
<ul>
<li>include error handling for Express middlewares (<a
href="https://redirect.github.com/socketio/engine.io/issues/674">#674</a>)
(<a
href="93957828be">9395782</a>)</li>
<li>prevent crash when provided with an invalid query param (<a
href="fc480b4f30">fc480b4</a>)</li>
<li><strong>typings:</strong> make clientsCount public (<a
href="https://redirect.github.com/socketio/engine.io/issues/675">#675</a>)
(<a
href="bd6d4713b0">bd6d471</a>)</li>
<li><strong>uws:</strong> prevent crash when using with middlewares (<a
href="8b22162903">8b22162</a>)</li>
</ul>
<h3>Credits</h3>
<p>Huge thanks to <a
href="https://github.com/tyilo"><code>@tyilo</code></a> and <a
href="https://github.com/cieldeville"><code>@cieldeville</code></a> for
helping!</p>
<h3>Dependencies</h3>
<ul>
<li><a
href="https://github.com/websockets/ws/releases/tag/8.11.0"><code>ws@~8.11.0</code></a>
(no change)</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="95e215387c"><code>95e2153</code></a>
chore(release): 6.4.2</li>
<li><a
href="fc480b4f30"><code>fc480b4</code></a>
fix: prevent crash when provided with an invalid query param</li>
<li><a
href="0141951185"><code>0141951</code></a>
refactor(types): ensure compatibility with Express middlewares</li>
<li><a
href="8b22162903"><code>8b22162</code></a>
fix(uws): prevent crash when using with middlewares</li>
<li><a
href="93957828be"><code>9395782</code></a>
fix: include error handling for Express middlewares (<a
href="https://redirect.github.com/socketio/engine.io/issues/674">#674</a>)</li>
<li><a
href="911d0e3575"><code>911d0e3</code></a>
refactor: return HTTP 400 upon invalid request overlap</li>
<li><a
href="bd6d4713b0"><code>bd6d471</code></a>
fix(typings): make clientsCount public (<a
href="https://redirect.github.com/socketio/engine.io/issues/675">#675</a>)</li>
<li>See full diff in <a
href="https://github.com/socketio/engine.io/compare/6.4.1...6.4.2">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/microsoft/onnxruntime/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
### Description
add target ort.webgpu.min.js
WebGPU is experimental feature, so I don't want to put webgpu into the
ort.min.js file. This change adds 2 ways for users to access ort-web
with webgpu:
- using script tag: by URL
`https://cdn.jsdelivr.net/npm/onnxruntime-web@1.15.0/dist/ort.webgpu.min.js`
( this URL is not ready yet )
- using `import()`: use `import { Tensor, InferenceSession } from
'onnxruntime-web/webgpu';` - 'onnxruntime-web/webgpu' instead of
'onnxruntime-web'
Implement a set of new APIs for lightweight custom ops registration, to
save efforts from schema-composing.
A few highlights:
- Support build-time type inference;
- Support function-as-op for "stateless" ops;
- Support structure-as-op for "stateful" ops;
- Support varied input/output forms such as span, scalar, and tensors,
either optional or non-optional.
---------
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
latest emsdk generated multi-thread version sometimes crash with unknown
reason ( error: memory access out of bounds ).
we don't want to break existing ort-web users, so revert emsdk back to
3.1.19 (same to what ort v1.14.0 uses)
### Description
Adding support for conv fp16 fusion with Conv-Add and Conv-Add-act.
Specifically tested on on Resnet50v1
### Motivation and Context
Adding support for conv fp16 fusion with Conv-Add and Conv-Add-act.
Specifically tested on on Resnet50v1
### Description
1. Update VERSION_NUMBER for preparing the upcoming release. This PR's
commit will not be included in the 1.15 release branch
2. Delete package/rpm/onnxruntime.spec since it was not used in past
years.
### Motivation and Context
Preparing the release.
Fixed
[AB#15311](https://aiinfra.visualstudio.com/6a833879-cd9b-44a4-a9de-adc2d818f13c/_workitems/edit/15311)
### Description
They were missed in #15707 , because they are not in common places for Dockerfiles.
Though this commit updated tools/ci_build/github/pai/rocm-ci-pipeline-env.Dockerfile, it won't automatically take effect. The image needs to be manually generated and pushed to a place, and before doing that our CMakeLists.txt also needs to be tweaked a little bit.
### Description
This is the first part to create a webassembly artifacts for ort-web
webgpu EP (wasm build).
there will be following steps to consume the artifacts in web build
### Description
Download protoc from Github Release instead of Nuget to avoid having
dependency on nuget.exe on Linux
### Motivation and Context
To avoid having dependency on nuget.exe on Linux. Many users' build
environment do not have nuget or dotnet.
### Description
Parallelize fp16 pooling operators
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Currently compiling with clang + cuda leads to:
```
/code/build/_deps/onnxruntime-src/include/onnxruntime/core/common/make_string.h:33:6: error: call to function 'operator<<' that is neither visible in the template definition nor found by argument-dependent lookup
ss << t;
^
/code/build/_deps/onnxruntime-src/include/onnxruntime/core/common/make_string.h:39:3: note: in instantiation of function template specialization 'onnxruntime::detail::MakeStringImpl<gsl::span<const long, 18446744073709551615>>' requested here
MakeStringImpl(ss, args...);
^
/code/build/_deps/onnxruntime-src/include/onnxruntime/core/common/make_string.h:46:3: note: in instantiation of function template specialization 'onnxruntime::detail::MakeStringImpl<const char *, gsl::span<const long, 18446744073709551615>>' requested here
MakeStringImpl(ss, args...);
^
/code/build/_deps/onnxruntime-src/include/onnxruntime/core/common/make_string.h:93:18: note: in instantiation of function template specialization 'onnxruntime::detail::MakeStringImpl<const char *, gsl::span<const long, 18446744073709551615>>' requested here
return detail::MakeStringImpl(detail::if_char_array_make_ptr_t<Args const&>(args)...);
^
/code/build/_deps/onnxruntime-src/onnxruntime/contrib_ops/cuda/quantization/qordered_ops/qordered_qdq.cc:73:12: note: in instantiation of function template specialization 'onnxruntime::MakeString<char[39], gsl::span<const long, 18446744073709551615>>' requested here
return ORT_MAKE_STATUS(ONNXRUNTIME, INVALID_ARGUMENT, "Shape not meet clean tile requirement!", dims);
^
/code/build/_deps/onnxruntime-src/include/onnxruntime/core/common/common.h:188:48: note: expanded from macro 'ORT_MAKE_STATUS'
::onnxruntime::MakeString(__VA_ARGS__))
^
/code/build/_deps/onnxruntime-src/include/onnxruntime/core/framework/tensor_shape.h:201:15: note: 'operator<<' should be declared prior to the call site or in namespace 'gsl'
std::ostream& operator<<(std::ostream& out, const TensorShape& shape);
^
1 error generated.
```
### Description
Adds an option to load local state dictionary for whisper model export.
### Motivation and Context
This is useful to demonstrate workflow of using ORT Training to get
model weights, downloading said weights onto a local gpu-enabled device,
exporting the custom model using `convert_to_onnx.py`, and then nicely
feeding the .onnx file into ORT InferenceSession.
{kind=link}