### Description
Add CUDA kernel.
Support double in CPU kernel and only write Mean and InvStdDev values if the optional outputs exist.
### Motivation and Context
Complete opset 17 support for LayoutNormalization
Attention, Quantize/Dequantize etc.
Update QOrderedMatmul's schema, updated unittest.
Verified test data for QOrdered Attention.
Co-authored-by: Zhang Lei <phill.zhang@gmail.com>
Co-authored-by: Lei Zhang <zhalei@microsoft.com>
1. Update CUDA version from 11.4 to 11.6.
2. Update Manylinux version
3. Upgrade GCC version from 10 to 11 for most x86_64 pipelines. CentOS 7 ARM64 doesn't have GCC 11 yet.
4. Refactor python packaging pipeline:
a. Split Linux GPU build job to two parts, build and test, so that the
build part doesn't need to use a GPU machine
b. Make the Linux GPU build job and Linux CPU build job more similar: share the same bash script and yaml file.
5. Temporarily disable Attention_Mask1D_Fp16_B2_FusedNoPadding because it is causing one of our packaging pipeline to fail. I have created an ADO task for this.
### Description ###
Add opset17 node test data
### Motivation and Context ###
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Some Ops in EP directory instead of contrib_ops directory will
require TunableOp. We will also need to add EP level session tuning
options for it. So move those code all at once.
Also remove duplicated utility functions.
**Description**: LayerNormalization is now part of the ONNX spec as of
opset 17.
We had a LayerNormalization contrib op, which (incorrectly) was
registered in the ONNX domain. Use that implementation for the ONNX
operator.
Update skip_layer_norm_fusion.cc. There are other optimizers that use
LayerNormalization that need updates as well.
**Motivation and Context**
#12916
**Description**: This PR adds Ascend CANN execution provider support.
**Motivation and Context**
- Why is this change required? What problem does it solve?
As the info shown in the issue. CANN is the API layer for Ascend
processor. Add CANN EP can allow user run onnx model on Ascend hardware
via onnxruntime
The detail change:
1. Added CANN EP framework.
2. Added the basic operators to support ResNet and VGG model.
3. Added C/C++、Python API support
- If it fixes an open issue, please link to the issue here.
https://github.com/microsoft/onnxruntime/issues/11477
Author:
lijiawei <lijiawei19@huawei.com>
wangxiyuan <wangxiyuan1007@gmail.com>
Co-authored-by: FFrog <ljw1101.vip@gmail.com>
**Description**:
Use full ORT package for onnxruntime-react-native.
Left the params required for the mobile build in comments so they're
easily discovered if we need to create onnxruntime-react-native-mobile
in the future.
**Motivation and Context**
Remove barrier to using ORT with react native as the mobile package that
was being used supports a limited range of opsets/operators/types, and
requires ORT format models. The full package will run any model.
* `QuantizeBFP` and `DequantizeBFP` schemas - similar to
`QuantizeLinear` and `DeQuantizeLinear`.
* BFP datatype is represented as a `uint8` tensor with shape and stride
metadata. This is preferrable to adding a new datatype for BFP, which is
more disruptive and [discouraged by
PyTorch](https://discuss.pytorch.org/t/training-with-custom-quantized-datatype/152132/2).
Context:
The Microsoft Floating Point (BFP) datatype shares an exponent for every
n numbers called a “bounding box.” Each number still has its own
mantissa and sign bits. BFP has been shown to incur 3-4 less cost
(energy and area) than BFloat16 and INT8 counterparts without reductions
in accuracy for the ImageNet benchmark as described in [Rouhani
2020](https://proceedings.neurips.cc/paper/2020/file/747e32ab0fea7fbd2ad9ec03daa3f840-Paper.pdf).
Requirements:
* There are many variants of BFP (number of mantissa bits, number of
shared exponent bits, size of bounding box, custom bit fields, etc.)
* The size and layout of an BFP variant varies across hardware
* bounding box can be over arbitrary dimensions; for example, for the
channel "C" dimension in a N x C x H x W tensor for convolution
Goals of this PR:
* Add initial versions of QuantizeBFP and DequantizeBFP operators to
enable QDQ-style quantization with BFP. Once the schemas stabilize, we
can consider upstreaming to ONNX.
* Add some basic type and shape inferencing tests; tests that run on an
EP will be a follow-up.
This changes are to align OV 2022.2 Release with ORT . Changes
CPU FP16 Support, dGPU Support, RHEL Dockerfile, Ubuntu 20 Dockerfile
**Motivation and Context**
- This change is required to ensure ORT-OpenVINO Execution Provider is
aligned with latest changes.
- If it fixes an open issue, please link to the issue here.
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: shamaksx <shamax.kshirsagar@intel.com>
Co-authored-by: pratiksha <pratikshax.bapusaheb.vanse@intel.com>
Co-authored-by: pratiksha <mohsinx.mohammad@intel.com>
Co-authored-by: Sahar Fatima <sfatima.3001@gmail.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
Co-authored-by: nmaajidk <n.maajid.khan@intel.com>
Co-authored-by: Mateusz Tabaka <mateusz.tabaka@intel.com>
Co-authored-by: intel <intel@iotgecsp-nuc04.iind.intel.com>
Replace the source of TRT version and fix the build issue happened on
Linux environment
### Description
Replace the source of TRT version from NvInfer.h to NvInferVersion.h
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
On Linux platform, using nvinfer.h in
tensorrt_execution_provider_utils.h would show error when building ORT
unit tests, as ORT unit test show the deprecation warnings as errors.
(Although this error didn't show up on Linux CI pipeline )
### Verification
The new change has been tested under both Linux & Windows environments.
Added a check for tensor validation on the input - this change fixes the
quiet abort WASM takes when processing a non tensor data in
"OrtGetTensorData"
**Motivation and Context**
At the current status when we try to process non-tensor data through
OrtGetTensorData and exception is thrown which results in a quiet abort
from WASM (assuming WASM was built without exception handling).
I added a check in the C API to catch this case and output a meaningful
message to the user
[example_error_github_12622.zip](https://github.com/microsoft/onnxruntime/files/9464328/example_error_github_12622.zip)
**Description**: I added a warning in
https://github.com/microsoft/onnxruntime/pull/10831 a week ago, but it's
noisy for onnxruntime_test_all.exe because very few tests explicitly
specify the providers they use, relying on implicit CPU, which makes it
harder to see actual errors in the output. So reduce this noise (that
is, if no EP's were explicitly provided, display no warning).
Sample output spew:
```
2022-09-20 20:08:50.6299388 [W:onnxruntime:NchwcOptimizerTests, session_state.cc:1030 onnxruntime::VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf.
```
**Motivation and Context**
- *Why is this change required? What problem does it solve?* Test output
noise makes it harder to debug real failures.
- *If it fixes an open issue, please link to the issue here.* NA
**Update engine hash id generator with model name/model
content/metadata**
**Description**:
* Updated engine id generator, which use model name/model inputs &
outputs/env metadata (instead of model path) to generate hash
* New bridged API were introduced in order to enable id generator in the
TRTEP utility
**Motivation and Context**
- Why is this change required? What problem does it solve? To fix this
[issue](https://github.com/triton-inference-server/server/issues/4587)
caused by id generator using model path
How to use:
* Call [TRTGenerateMetaDefId(const GraphViewer& graph_viewer, HashValue&
model_hash)](0fcce74a56/onnxruntime/core/providers/tensorrt/tensorrt_execution_provider.cc (L715))
to generate hash id for TRT engine cache
How to test:
* On WIndows, run:
* .\onnxruntime_test_all.exe
--gtest_filter=TensorrtExecutionProviderTest.TRTMetadefIdGeneratorUsingModelHashing
* .\onnxruntime_test_all.exe
--gtest_filter=TensorrtExecutionProviderTest.TRTSubgraphIdGeneratorUsingModelHashing
**Appendix**
* [Existing engine id generator that uses model
path](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/core/framework/execution_provider.cc#L112-L182)
**Description**: Describe your changes.
As title.
The purpose of this pr is to eliminate as much of repetitive shape
inference code in nnapi ep shaper struct.
For ops (mainly require composed operations) :
-BatchNorm
-Reshape
-Squeeze (in one case of gemm operator)
-BatchMatMul
still contains some shape calculation impl/logic.
Dynamic shape functions are not touched yet.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Clean up redundant code as cpu shape inference impl for NNAPI EP.
Get rid of the shape inference code in NNAPI EP by using the static
shape info in output NodeArg.
1. add node test data to current model tests
2. support opset version to filter tests.
3. remove old filter based on onnx version. To avoid confusion, ONLY
support opset version filter in onnxruntime_test_all
4. support read onnx test data from absolute path on Windows.
**Description**: Describe your changes.
As title.
Added unit test for the case.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Fix issue #12979
Since CUDA EP became a shared library, most of internal functions are
not accessible from `onnxruntime_test_all`, we need a new mechanism to
write CUDA EP-specific tests. To this end, this PR introduces a general
infra and an example test for deferred release in CUDA EP. When adding
this test, we also found the current deferred release will cause error
when pinned CPU buffer is not allocated by BFCArena, and this PR also
makes a small fix (see changes in rocm_execution_provider.cc and
cuda_execution_provider.cc).
This PR also fixes a deferred release bug found by new tests.
# Motivation
Currently, ORT minimal builds use kernel def hashes to map from nodes to
kernels to execute when loading the model. As the kernel def hashes must
be known ahead of time, this works for statically registered kernels.
This works well for the CPU EP.
For this approach to work, the kernel def hashes must also be known at
ORT format model conversion time, which means the EP with statically
registered kernels must also be enabled then. This is not an issue for
the always-available CPU EP. However, we do not want to require that any
EP which statically registers kernels is always available too.
Consequently, we explore another approach to match nodes to kernels that
does not rely on kernel def hashes. An added benefit of this is the
possibility of moving away from kernel def hashes completely, which
would eliminate the maintenance burden of keeping the hashes stable.
# Approach
In a full build, ORT uses some information from the ONNX op schema to
match a node to a kernel. We want to avoid including the ONNX op schema
in a minimal build to reduce binary size. Essentially, we take the
necessary information from the ONNX op schema and make it available in a
minimal build.
We decouple the ONNX op schema from the kernel matching logic. The
kernel matching logic instead relies on per-op information which can
either be obtained from the ONNX op schema or another source.
This per-op information must be available in a minimal build when there
are no ONNX op schemas. We put it in the ORT format model.
Existing uses of kernel def hashes to look up kernels are replaced
with the updated kernel matching logic. We no longer store
kernel def hashes in the ORT format model’s session state and runtime
optimization representations. We no longer keep the logic to
generate and ensure stability of kernel def hashes.
This allow us quickly launch a microbench session by, for example:
```bash
python gemm_test.py T N float16 256 256 65536
```
So that we can quickly see which one is the fastest.
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
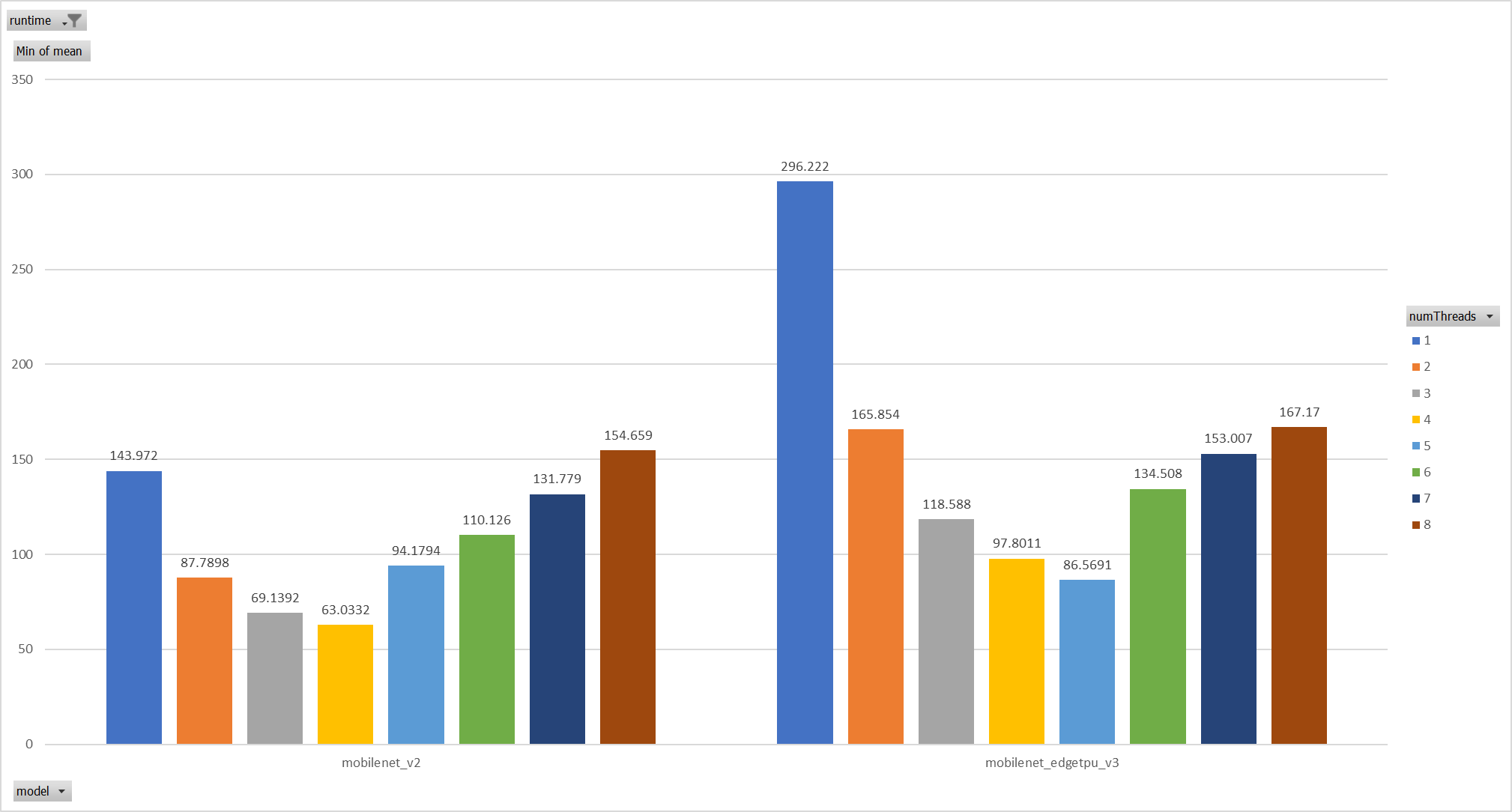
Case 2:
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
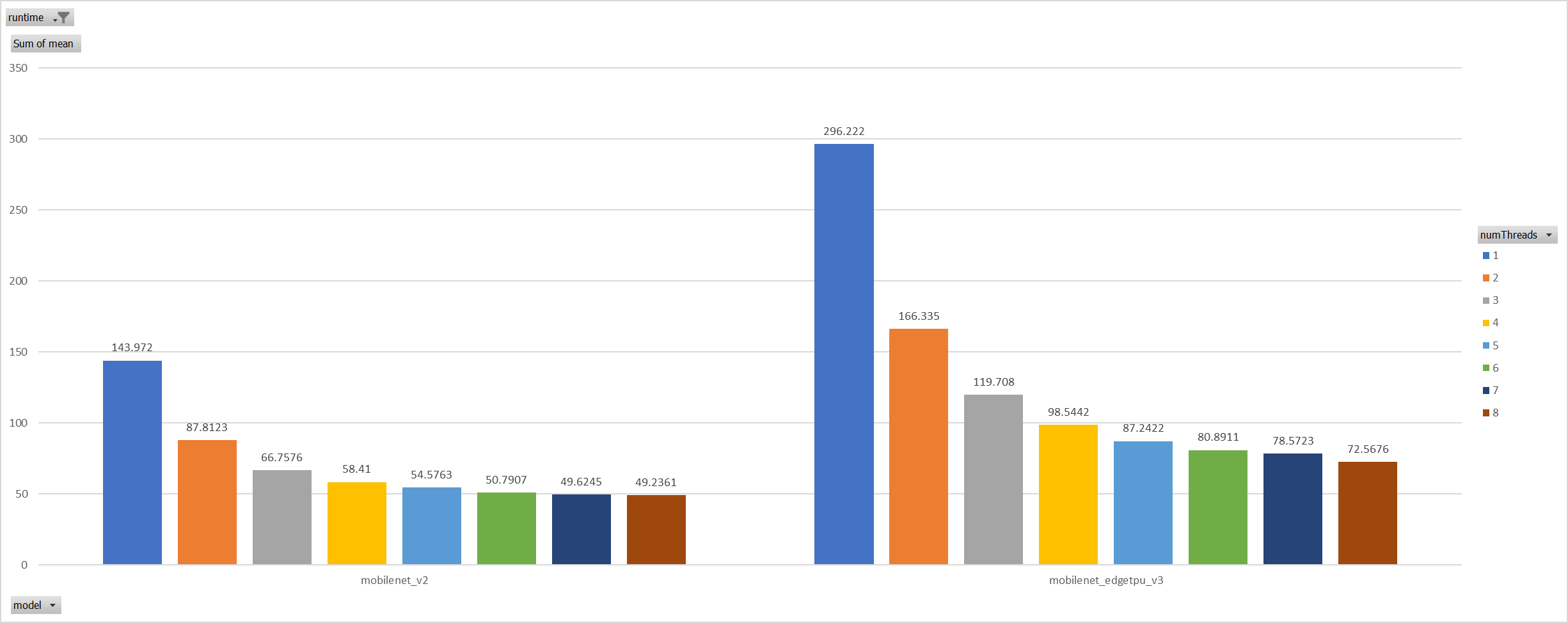
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
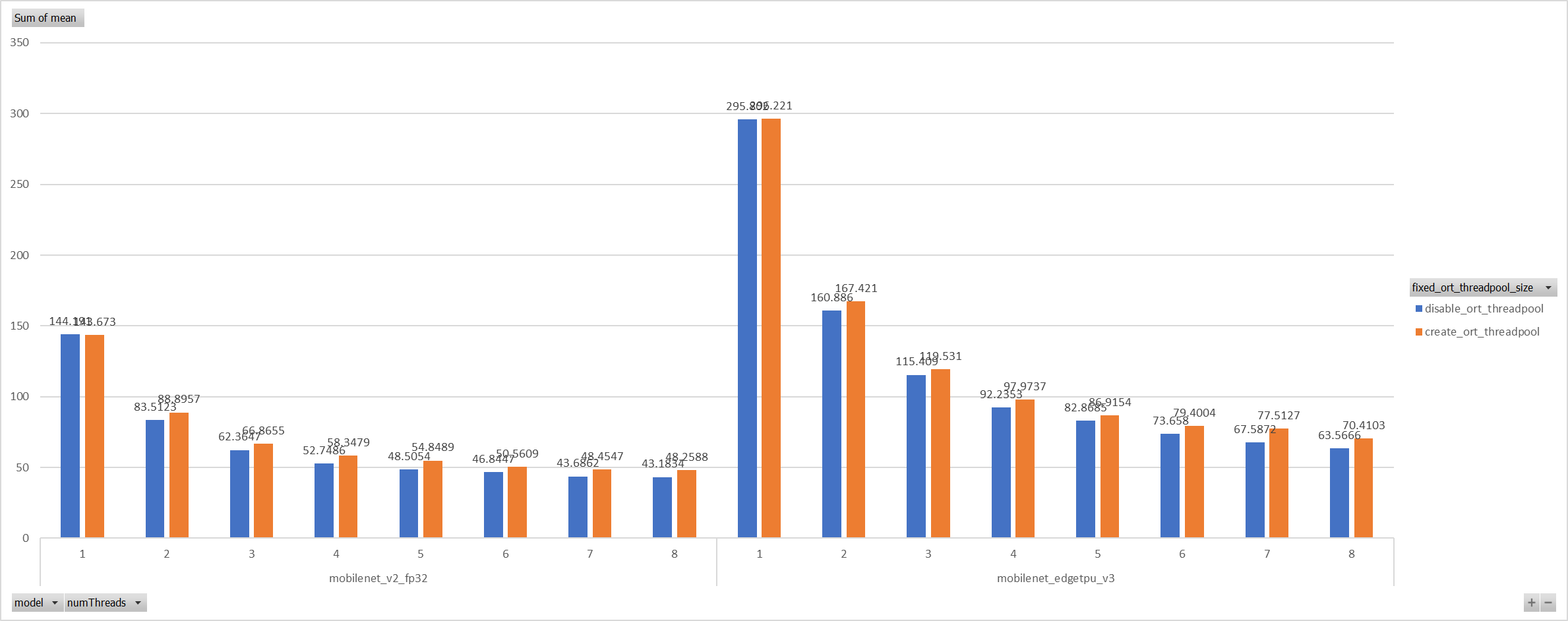
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
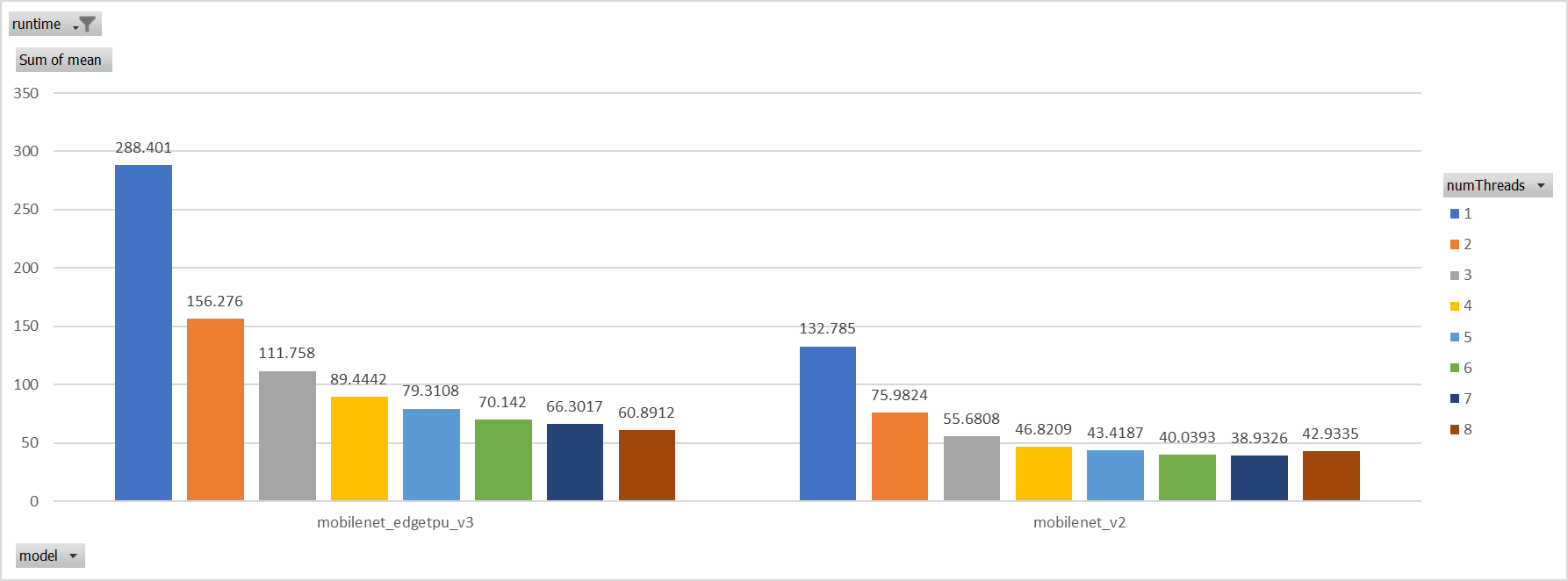
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}