**Description**: Describe your changes. XNNPACK takes pthreadpool as its internal threadpool implemtation, it couples calculation and parallelization. Thus it's impossible to leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled pthreadpool in XNNPACK EP in this PR. Case 1: Pthreadpool coexist with ORT-threadpool simply Expriments setup hardware:RedMi8A with 8 cores, ARMv7 The two threadpool has the same pool size form 1 to 8. Two models: mobilenet_v2 and mobilenet_egetppu. we can see the picture below and draw a conclusion, latency are even higher from 5 threads or more. 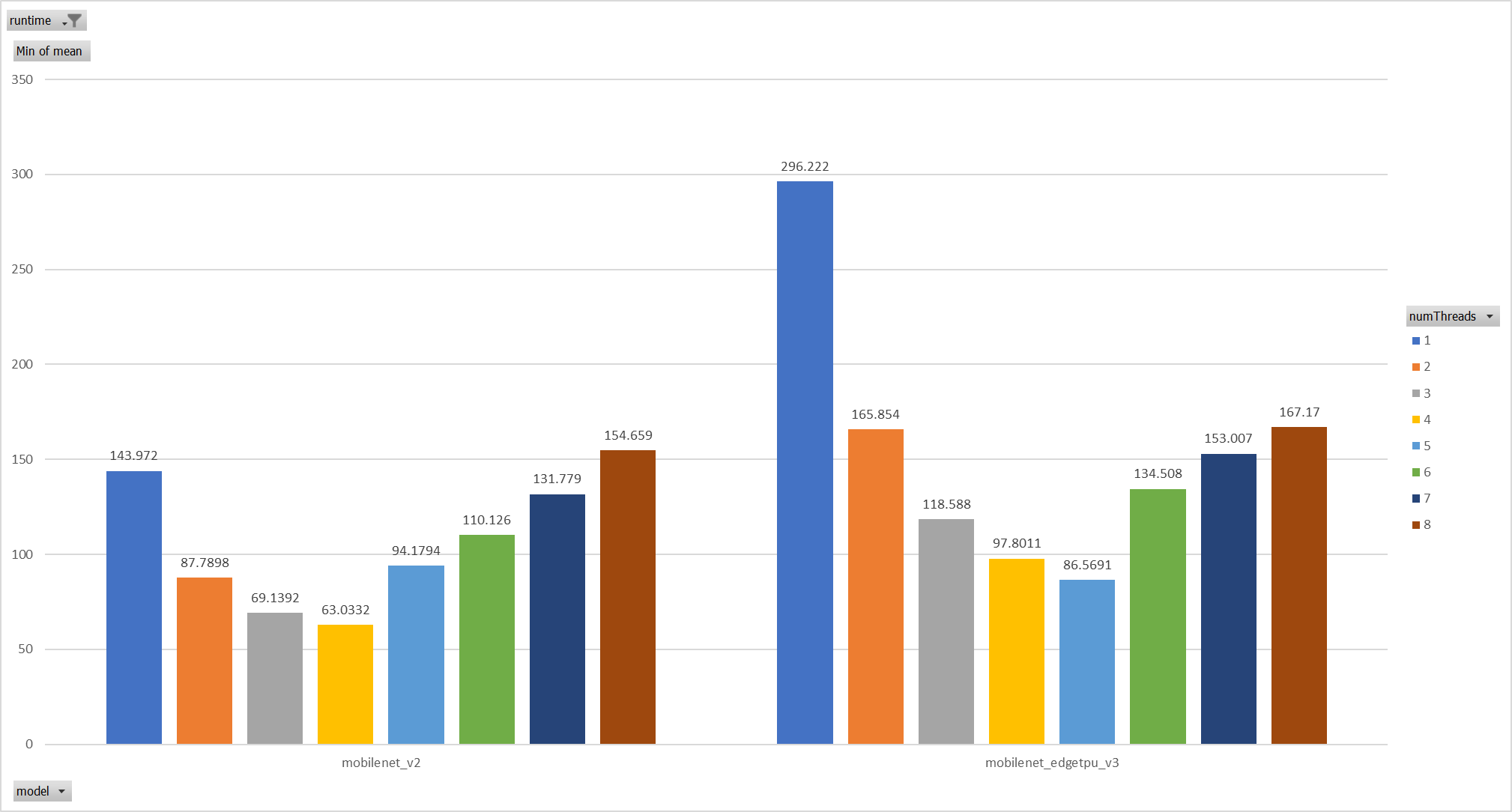 Case 2: For the reason of performance regression with 5 more threads, ORT-threads are spinning on CPU and diddn't realease it after computation finished. It's equivalent of creating 5x2 threads for parallelization while we have only 8 cpu cores. So I mannuly disabled spinning after ort-threadpool finished and enabled it when enter ort-threadpool. The result is quite normal now. 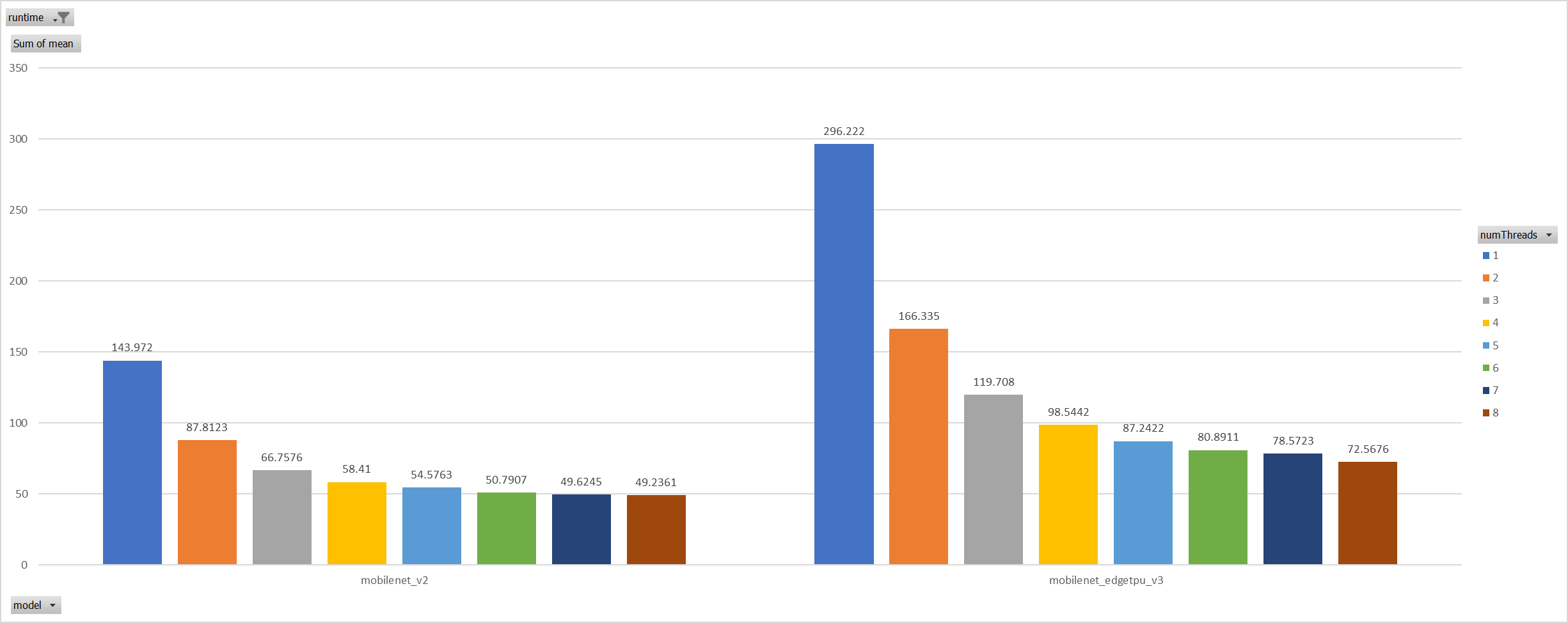 Case 3: Even we achieved a reasonable results with disabling spinning, Will ORT-threadpool still impact performance of pthreadpool? we have expriment setting up as: Setting ORT-threadpool size (intra_thread_num) as 1, and only pthreadpool created. Attention that, almost a third of ops are running by CPU EP. we are surprisingly find that disabling ort-threadpool is even better in performance than creating two threadpool. 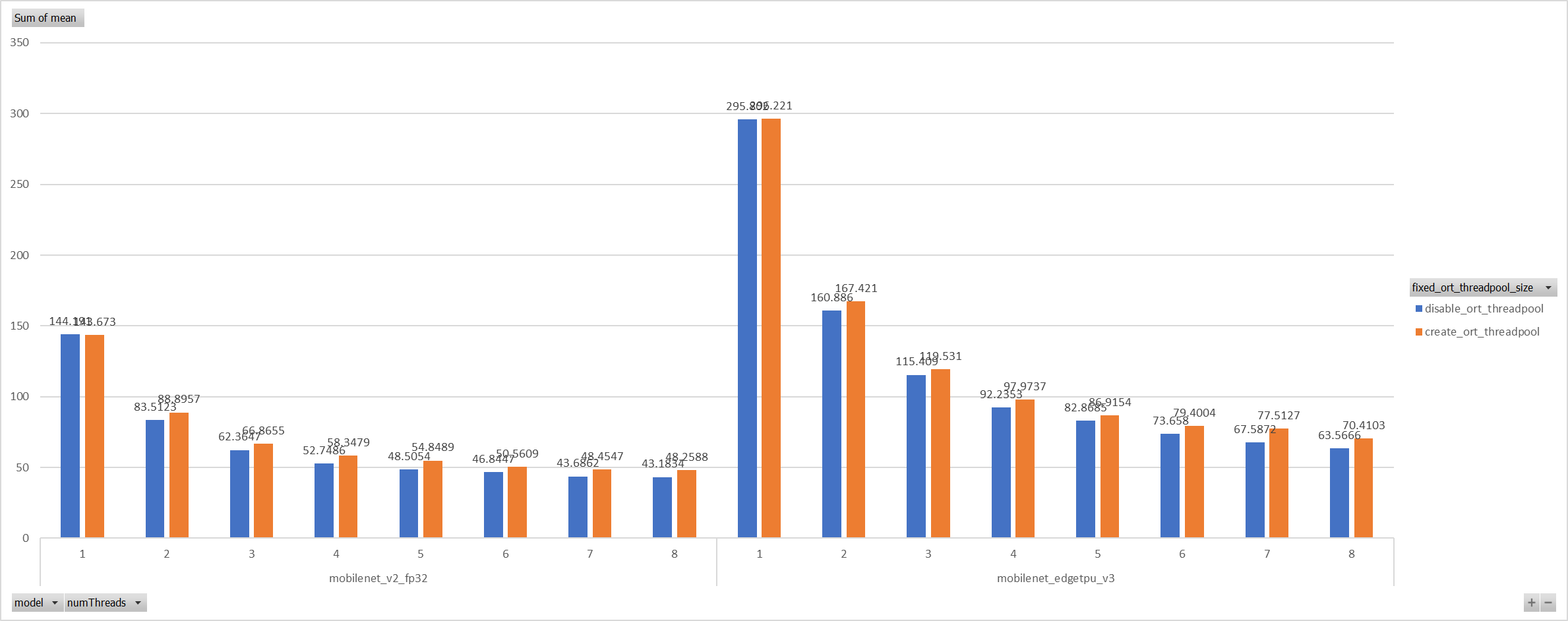 Case 4: Use a unified threadpool between CPU ep and XNNPACK ep. It's the fastest among all. But if we take the similar workload partition strategy as ORT-threadpool, it could be faster. 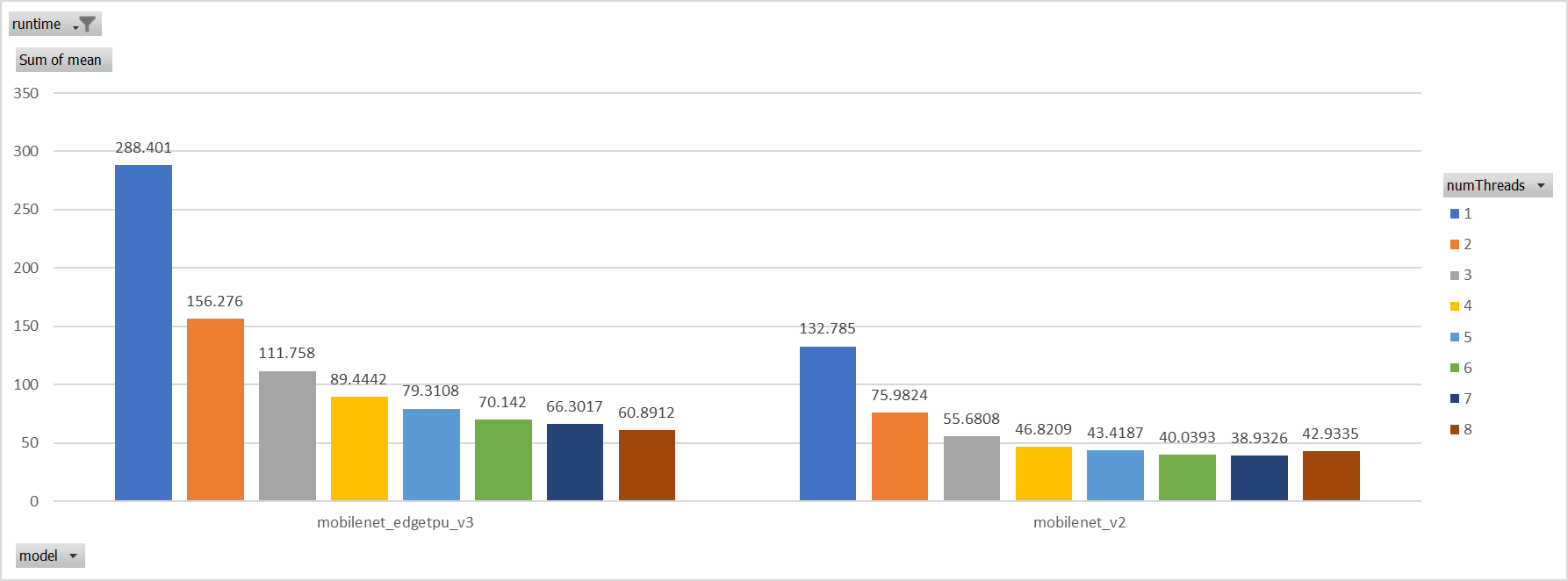 **Motivation and Context** - Why is this change required? What problem does it solve? - If it fixes an open issue, please link to the issue here. Co-authored-by: Jicheng Wen <jicwen@microsoft.com> |
||
|---|---|---|
| .config | ||
| .devcontainer | ||
| .gdn | ||
| .github | ||
| .pipelines | ||
| .vscode | ||
| cgmanifests | ||
| cmake | ||
| csharp | ||
| dockerfiles | ||
| docs | ||
| include/onnxruntime/core | ||
| java | ||
| js | ||
| objectivec | ||
| onnxruntime | ||
| orttraining | ||
| package/rpm | ||
| samples | ||
| tools | ||
| winml | ||
| .clang-format | ||
| .clang-tidy | ||
| .dockerignore | ||
| .flake8 | ||
| .gitattributes | ||
| .gitignore | ||
| .gitmodules | ||
| build.amd64.1411.bat | ||
| build.bat | ||
| build.sh | ||
| CITATION.cff | ||
| CODEOWNERS | ||
| CONTRIBUTING.md | ||
| lgtm.yml | ||
| LICENSE | ||
| NuGet.config | ||
| ort.wprp | ||
| ORT_icon_for_light_bg.png | ||
| packages.config | ||
| pyproject.toml | ||
| README.md | ||
| requirements-dev.txt | ||
| requirements-doc.txt | ||
| requirements-training.txt | ||
| requirements.txt.in | ||
| SECURITY.md | ||
| setup.py | ||
| ThirdPartyNotices.txt | ||
| VERSION_NUMBER | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![]()
ONNX Runtime is a cross-platform inference and training machine-learning accelerator.
ONNX Runtime inference can enable faster customer experiences and lower costs, supporting models from deep learning frameworks such as PyTorch and TensorFlow/Keras as well as classical machine learning libraries such as scikit-learn, LightGBM, XGBoost, etc. ONNX Runtime is compatible with different hardware, drivers, and operating systems, and provides optimal performance by leveraging hardware accelerators where applicable alongside graph optimizations and transforms. Learn more →
ONNX Runtime training can accelerate the model training time on multi-node NVIDIA GPUs for transformer models with a one-line addition for existing PyTorch training scripts. Learn more →
Get Started
General Information: onnxruntime.ai
Usage documention and tutorials: onnxruntime.ai/docs
Companion sample repositories:
- ONNX Runtime Inferencing: microsoft/onnxruntime-inference-examples
- ONNX Runtime Training: microsoft/onnxruntime-training-examples
Build Pipeline Status
| System | CPU | GPU | EPs |
|---|---|---|---|
| Windows | |||
| Linux | |||
| Mac | |||
| Android | |||
| iOS | |||
| WebAssembly |
Data/Telemetry
Windows distributions of this project may collect usage data and send it to Microsoft to help improve our products and services. See the privacy statement for more details.
Contributions and Feedback
We welcome contributions! Please see the contribution guidelines.
For feature requests or bug reports, please file a GitHub Issue.
For general discussion or questions, please use GitHub Discussions.
Code of Conduct
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
License
This project is licensed under the MIT License.