This allow us quickly launch a microbench session by, for example:
```bash
python gemm_test.py T N float16 256 256 65536
```
So that we can quickly see which one is the fastest.
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
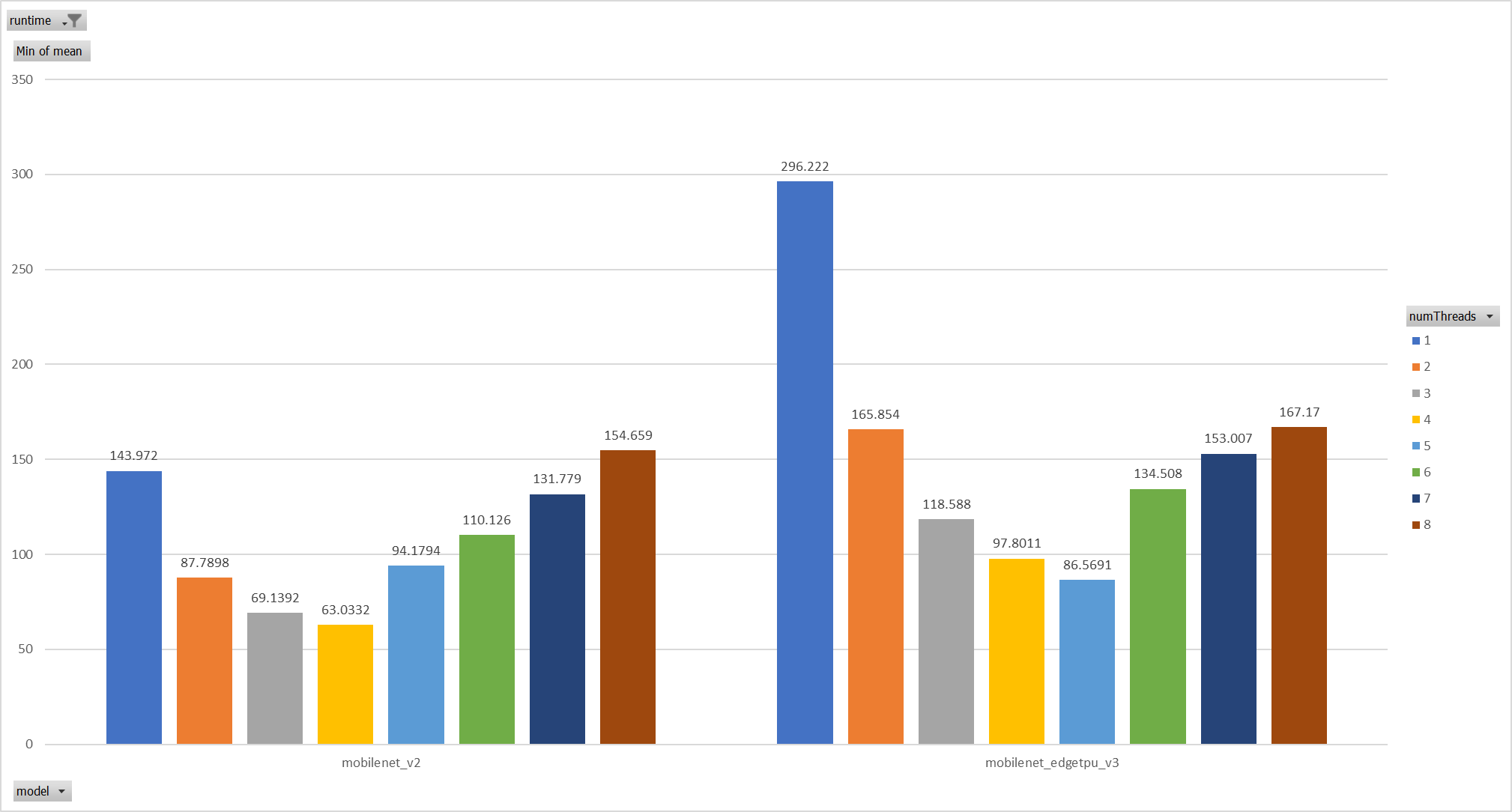
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
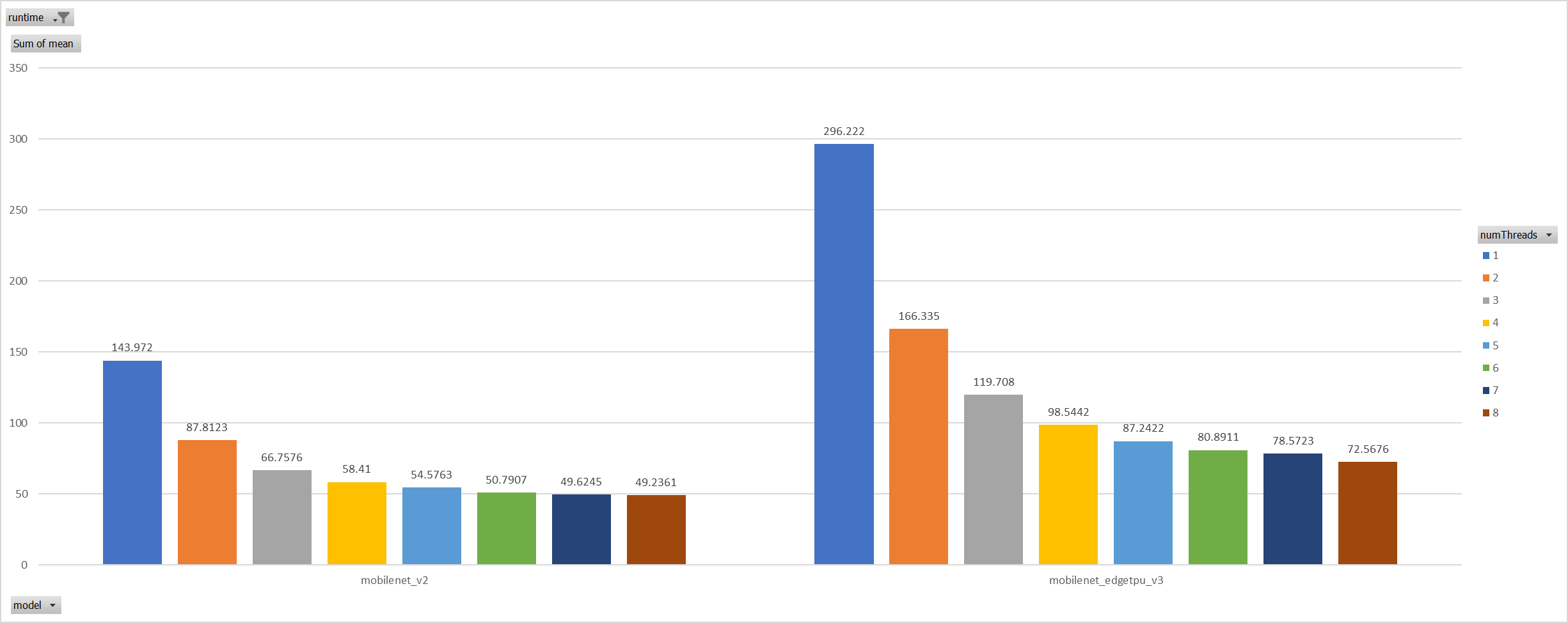
Case 2:
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
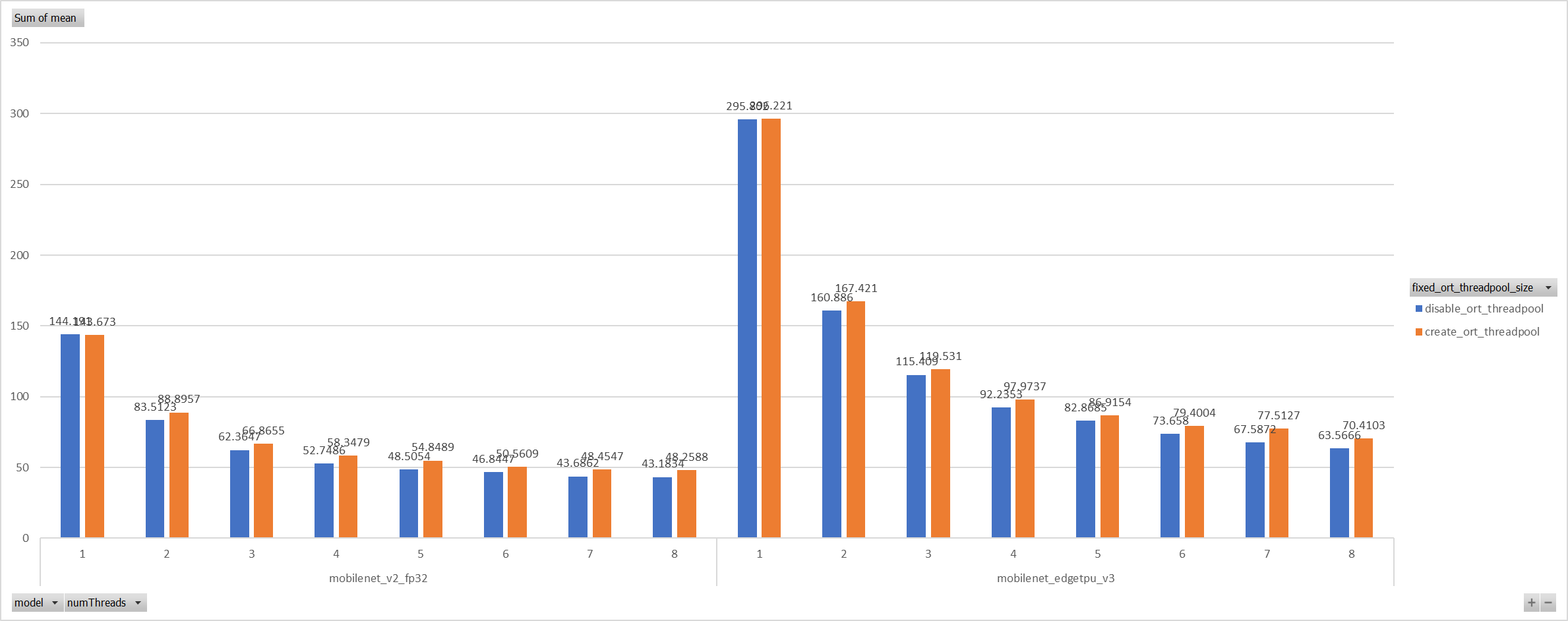
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
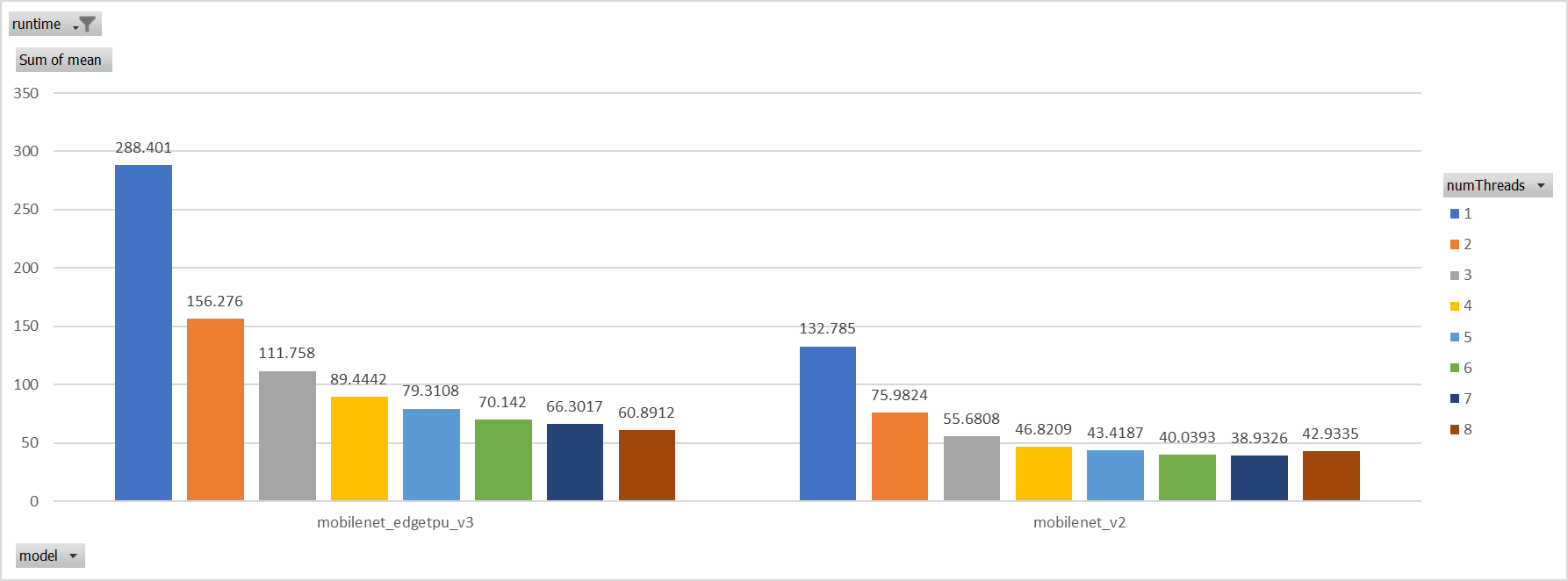
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
**Description**: Remove the `settings.json` line in gitignore.
**Motivation and Context**
Having `settings.json` tracked in git has created annoying diffs when it
is modified locally. This PR removes the entry in gitignore but
maintains the `settings.json` in the repo so that we have a good
default.
Recent change in CUDA EP #12814 makes hipify extremely slow and breaks the building. This PR fixes it by c
The onnxruntime/contrib_ops/rocm/bert/attention.h is checkout-ed from the version before #12814 and manually hipify-ed.
Slightly extend amd_hipify.py to allow wildcard file match and exclude all `tensorrt_fused_multihead_attention/*` files from hipify
Fix two warnings:
1. Warning: Avoid calling new and delete explicitly, use
std::make_unique<T> instead (r.11).
Fix: new is replaced by creating unique_ptr and unique_ptr.release
delete is replaced by unique_ptr.reset and unique_ptr's destructor.
2. Warning: Buffer overrun while writing to 'cpu_buffers_info->buffers':
the writable size is 'buffers.public: unsigned __int64 __cdecl
std::vector<void \*,class std::allocator<void\*> >::size(void)const ()
\* 8' bytes, but '16' bytes might be written.
Fix: Replace void* with cudaStream_t and void** with
std::vector<cudaStream_t>.
**Description**: **Python API Bindings for on device training. **
**Motivation and Context**
- This PR contains api bindings so python users can perform a whole
training loop.
Co-authored-by: Adam Louly <adamlouly@microsoft.com@orttrainingdev7.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Baiju Meswani <bmeswani@microsoft.com>
QLinearConv does not work with DML EP because this optimizer intended for CPU EP is wrongfully applied to it.
Limit NHWC optimizer to nodes assigned to the CPU EP
* consume ONNX 1.12.1 to prevent vulnerability issue while loading external tensors
* update ONNX 1.12.1
* test updated PR
* use official rel-1.12.1 commit
* Warn on node EP fallback from preferred provider
* Clarify with comment
* Update to ORT's weird coding style for ragged parameter wrap
* Android build error: unused parameter ‘providers’
* Update logic to be more robust
* Updates from Pranav's feedback about messaging to rerun with verbose and respecting explicit vs implicit EP addition. Also merge from main.
* brace style patch up
* Update with feedback from Pranav and Scott McKay
* Restore node_placement_set after realizing it only applies when is_verbose is true
* Fix build warning on Android
* Renamed to node_placement_provider_set per Pranav's suggestion
1. Move the Linux ARM64 part of python packaging pipeline to a real ARM64 machine pool
2. Refactor the Linux CPU build jobs of python packaging pipeline to two parts: build and test. The test part will be exempted from Cyber EO compliance requirements as it won't affect the final bits we publish. This refactoring is to reduce dependencies in the build part. For example, this PR remove pytorch from the build dependencies.
3. Combine DML nuget packaging pipeline with "Zip-Nuget-Java-Nodejs Packaging Pipeline" as they all produce ORT nuget packages. Also, publish DML nuget packages and ORT GPU nuget packages to https://aiinfra.visualstudio.com/PublicPackages/_artifacts/feed/ORT-Nightly feed.
* Changes for AIX compilation to get CPU of running thread. hz is internal variable in AIX, hence changing to hz1 in window_functions.cc so that all OS shall work
Co-authored-by: madurais <root@telesto10.in.ibm.com>
Co-authored-by: tvkai <vamshikrishna@in.ibm.com>
* Template datatype for SoftmaxWithRawMaskSmallKernel in ROCm EP
* Remove valid_items usage from SoftmaxWithRawMaskSmallKernel for ROCm EP
The kernel already masks off invalid items and this gives a much
faster implementation in hipCUB.
* Update accumulator type in ROCm EP for SoftmaxWithRawMaskSmallKernel
Hard code accumulator to fp32 for hipCUB in indicated kernel.
* Reset casting to old behavior
* Document steps to optimize SoftMax kernel on ROCm EP
Usage of the hipCUB valid_items interface on reduction operations
has a significant performance impact. Masking all thread data to
avoid need to use the valid_items interface to hipCUB.
{kind=link}
{kind=link}
{kind=link}
{kind=link}