### Description
* add more configs for `threads_per_block` in SkipLayerNorm, also in
kernel explorer.
* loosen constraints for hidden_size, so that `SkipLayerNormSmallOp` can
be selected for larger hidden sizes.
* add flag for optional output in kernel_explorer
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Support externally-managed output tensors (torch Tensors) for dort.
Add `preallocate_output` option to OrtBackend to rely on
externally-managed output tensors for dort.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
DORT currently allocates and returns output ortvalues and convert them
to torch Tensors. The conversion based on dlpack does not support torch
Tensors for custom Aten backends, and it is not yet possible to transfer
the ownership from ortvalue to external handle (torch Tensor).
To avoid this issue, the PR change provides an option
(`preallocate_output`) to allocate output tensors externally in pytorch,
which creates torch Tensor for an Aten backend, and let dort take
pointers from torch Tensors to construct output ortvalues instead of
allocating them inside InferenceSession.
### Description
A follow up change for
https://github.com/microsoft/onnxruntime/pull/13616.
SoftmaxCrossEntropyLossInternal/SoftmaxCrossEntropyLossInternalGrad
support different type for input and output.
Add SCELoss(SCELossGrad) support half(float) input float(half) output
### Test Note
#### Add tests for variant input and output types. To add such tests,
have to refactor existing testing code for sce loss and scelossinternal
gradient.
Originally,
FP32 input and output, the CPU kernels, runs with CPU kernels the
baseline, CUDA/RCOM then runs with same data, user CompareTester to
compare with CPU run results.
FP16 input and output, the CPU kernels (did not have half kernels), runs
with Cast_to_float->CPU kernel->cast_to_half as the baseline, CUDA/RCOM
then runs with same data but using Half implementation, user
CompareTester to compare with CPU run results.
Now, we want the support run different input and output types. The
proposed change here is, to run CPU kernels always with float input and
output as baseline (because CPU only have float type kernels impl), this
step is the very first thing for every test.
Then, we run CUDA/RCOM kernels using half_input_half_output,
float_input_float_output, half_input_float_output,
float_input_half_output if there is corresponding kernel registered.
Afterwards, compare the CUDA/ROCM run results with CPU float baselines.
Be noted, there is one thing that deserved a special note:
CompareOpTester's result compare can be loose than OpTester's.
Roughly speaking: the former tolerant diff <= atol +
rtol*expected_value, while the later one telerant diff < atol && diff <
rtol*expected_value. When the expected value is super small in many
cases of our tests cases, the former one can pass but the later one
fails. So the refactoring also move the check outside of OpTester,
explicitly check the values using the way CompareOPTester did (to align
the previous behaviour).
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Fixed an exception that is thrown inside `transformers` when trying to
test PyTorch performance:
```
> python convert_generation.py -m gpt2 --output gpt2_greedy_search.onnx --num_beams 1 --num_return_sequences 1 --torch_performance
…GPT_Attention)
Some EPs require that onnxruntime and optimum optimizations are turned
off in order to run correctly. Allowing this option during test runs
allows the EP and library to perform their own optimization and be more
representative of actual use case conditions.
Important for EPs like MIGraphX which require optimizations to be offer
for certain operations
### Description
<!-- Describe your changes. -->
Allow flags to turn off optimizations and add verbose output to confirm
which EP is being used for the inference run and validate fallbacks
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Related to: #14702 & #14700
---------
Signed-off-by: Ted Themistokleous <tthemist@amd.com>
Co-authored-by: Ted Themistokleous <tthemist@amd.com>
### Description
<!-- Describe your changes. -->
I fixed some broken links in the C API documentation, but then did a
quick pass over all of the links I could find and then fixed those.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
I got some 404's when exploring the documentation and wanted to fix it.
### Description
`_infer_Slice()` is a function (arguably the most complex one) in
`symbolic_shape_infer.py` that infers the shape of the output of a
`Slice` node. This commit fixes an edge case in `_infer_Slice()` caused
by a SymPy quirk.
When both the end of the slice (let's call it `e`) and the corresponding
dimension of the sliced tensor (let's call it `dim`) are arbitrary
symbolic expressions, `symbolic_shape_infer.py`
[checks](de7a868d5f/onnxruntime/python/tools/symbolic_shape_infer.py (L1728))
if `e <= dim`. Comparing symbolic expressions is hard in general, so if
the comparison fails, `symbolic_shape_infer.py` [gives
up](de7a868d5f/onnxruntime/python/tools/symbolic_shape_infer.py (L1734))
and assumes that `e` is equal to `dim`.
A failure of this sort currently happens for expressions of the form `Y
- X >= 0` where `Y` contains a `sympy.Min()` (`symbolic_shape_infer.py`
tries to rewrite `X <= Y` comparisons in various ways, and `Y - X >= 0`
is [one of
them](de7a868d5f/onnxruntime/python/tools/symbolic_shape_infer.py (L1664))).
An simple example to illustrate this:
```python
>>> import sympy
>>> X = sympy.Symbol('X', positive=True, integer=True)
>>>
>>> y1 = 9999
>>> Y1 = X + y1 - 5000
>>> bool(Y1 - X >= 0)
True
>>>
>>> y2 = X + 4999
>>> Y2 = X + y2 - 5000
>>> bool(Y2 - X >= 0)
True
>>>
>>> y3 = sympy.Min(y1, y2)
>>> Y3 = X + y3 - 5000
>>> bool(Y3 - X >= 0)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../venv/lib/python3.9/site-packages/sympy/core/relational.py", line 511, in __bool__
raise TypeError("cannot determine truth value of Relational")
TypeError: cannot determine truth value of Relational
```
If you assume that `X` is positive symbol (`symbolic_shape` [does
assume](de7a868d5f/onnxruntime/python/tools/symbolic_shape_infer.py (L2129))
this for graph inputs), then both `Y1 >= X` and `Y2 >= X` holds, and
SymPy can prove this. This means that `Y3 >= X` also holds (since `Y3`
is essentially equal to either `Y1` or `Y2`, depending on the value of
`X`), but this is too hard for SymPy to prove. I confirmed that this is
still the case for the latest SymPy version (`1.11.1`).
This commit tries to fix this edge case by slightly rewriting the
expression containing `sympy.Min()`. I explain the details in the
comments in `symbolic_shape_infer.py`, so I won't duplicate them in the
PR description.
### Motivation and Context
This sounds like a very contrived example, but it actually appeared in
the wild when we tried to infer shapes for an ONNX graph exported from
PyTorch that used relative-position multihead attention from Fairseq.
The problematic line is
[here](7d050ada7d/fairseq/modules/espnet_multihead_attention.py (L192)).
In our codebase, we have something like `matrix_bd = matrix_bd[:, :, :,
: matrix_ac.size(-1)]` before we add `matrix_ac` and `matrix_bd`.
`matrix_bd` is itself a result of another slice, hence its shape
contains `sympy.Min()`, and the SymPy weirdness described above prevents
`symbolic_shape_infer.py` from correctly inferring the final shape of
`matrix_bd`. Then `symbolic_shape_infer.py` explodes when we try to add
`matrix_ac` and `matrix_bd`, because their shapes are not compatible.
I added a small self-contained unit test to illustrate the problem.
*Without* the fix, `slice_out_cropped` has shape `[N + Min(42, N + 21) -
22]`, and `input` has shape `[N]`, and we get this:
```
> python onnxruntime_test_python_symbolic_shape_infer.py
..................Cannot determine if 22 - N < 0
Unable to determine if N <= N + Min(42, N + 21) - 22, treat as equal
E....
======================================================================
ERROR: test_slice_of_min (__main__.TestSymbolicShapeInferenceForSlice)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/dfyz/onnxruntime/onnxruntime/test/python/onnxruntime_test_python_symbolic_shape_infer.py", line 460, in test_slice_of_min
model = SymbolicShapeInference.infer_shapes(onnx.helper.make_model(graph_def))
File "/home/dfyz/onnxruntime/onnxruntime/test/python/../../python/tools/symbolic_shape_infer.py", line 2461, in infer_shapes
raise Exception("Incomplete symbolic shape inference")
Exception: Incomplete symbolic shape inference
----------------------------------------------------------------------
Ran 23 tests in 0.486s
FAILED (errors=1)
```
*With* the fix, both tensors have shape `[N]`, and the test passes.
---------
Co-authored-by: Ivan Komarov <dfyz@yandex-team.ru>
### Description
This PR addresses the case where an optional Gather node is in the
subgraph pattern. The optional node is now fused with the other nodes
matched in the pattern to create an EmbedLayerNormalization node.
### Motivation and Context
The original subgraph pattern is
```
Gather Gather
\ /
Add
|
LayerNormalization
|
Attention
|
...
```
and the new subgraph pattern is
```
Gather Gather
\ /
Gather (optional) Add
\ |
LayerNormalization
|
Attention
|
...
```
Update stable diffusion benchmark script:
(1) Test GPU memory usage
(2) Change diffusers version to 0.13, and add support of PyTorch 2.0
including compile
(3) Add support of xformers
(4) Output result to CSV file
Example to run PyTorch 2.0 with torch.compile:
```
pip3 install numpy --pre torch --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
export TRITON_PTXAS_PATH=/usr/local/cuda-11.7/bin/ptxas
python benchmark.py -e torch -v 1.5 -c 5 -n 1 -b 1 --enable_torch_compile
```
Enable Opset11 Sequence Ops on DirectML, and make the CPU
implementations agnostic to backend EP
Opset 11 introduced the following sequence related operators:
- SequenceAt
- SequenceConstruct
- SequenceEmpty
- SequenceLength
- SequenceErase
- SequenceInsert
- ConcatFromSequence
With the exception of ConcatFromSequence, all of the above operators
were implemented with CPU kernels that a) required all of the contained
tensors to also be on CPU, and b) would clone each tensor into a new
sequence as a side effect of each operator. The implementation of
sequences are backend agnostic, as they dont affect actual tensor layout
or manipulate the contents of the tensors. In addition, with the
exception of SequenceAt, the other operators need not make copies of the
underlying referenced tensors.
Consequently, this change does the following:
1) Sequence* operators (except SequenceAt) no longer copies the contents
of a sequence of tensors on every kernel execution.
2) SequenceAt uses the DataTransferManager to copy tensors agnostic to
backend.
3) The internal container implemented by TensorSeq has changed from
onnxruntime::Tensor to OrtValue. This is because onnxruntime::Tensor
does not support copy or assignment construction, so it must have a
singular owner. However, is same tensor participates in multiple
containers it would have multiple container "owners" and this would not
be possible.
4) Other code that accessed values from TensorSeq have associated
changes to extract Tensors from OrtValues now.
In addition, DirectML execution was very slow when the above Sequence
operators were added to a graph, as this caused MemcpyToHost and
MemcpyFromHost kernels to be inserted between the graph and the sequence
operators. To optimize DirectML,
1) The CPU implementations for the Sequence* ops were registered as DML
implementations. Since the above changes also includes making the CPU
kernel implementations EP agnostic, the CPU kernels can be added as is.
2) The ConcatFromSequence operator needed to be implemented on DirectML.
However, there was little DirectML EP operator framework support for
operators that accept/output sequences of tensors. This change has
modified the internal COM interfaces to include new apis to interrogate
for sequence shapes, and extract the needed tensors from TensorSeq.
---------
Co-authored-by: Patrice Vignola <vignola.patrice@gmail.com>
There is accuracy regression in GPT-2 model. Top1 match rate (vs PyTorch
model) drops about 1%. The cause is the fused causal attention uses fp16
accumulation. Disable it by default and add an environment variable
ORT_ENABLE_FUSED_CAUSAL_ATTENTION=1 to turn on it manually.
It also updated the GPT-2 parity test script to generate left side
padding to reflect the actual usage.
To test:
```
python -m onnxruntime.transformers.models.gpt2.convert_to_onnx -m gpt2 --output gpt2.onnx -o -p fp16 --use_gpu
```
The top1-match-rate in the output is on-par with ORT 1.13.1.
Add a fusion to remove transpose in subgraph like
```
--> Gemm --> Unsqueeze(axes=[2]) --> Unsqueeze(axes=[3]) --> Add --> Transpose([0,2,3,1]) --> GroupNorm
```
With this fusion, we can remove 22 Transpose nodes in UNet, and reduce
latency by 0.1 second per image in T4.
1. Add Softmax warpwise_forward into SoftmaxTunableOp.
2. Set Softmax op use tunableOp as optional and use original
implementation by default.
3. There are some other operators use `dispatch_warpwise_softmax_forward
/dispatch_warpwise_softmax_forward/ SoftMaxComputeHelper ` directly. But
they only have files under cuda directory, adding `RocmTuningContext `
for these files requires copying and modifying hipified files. Now only
set RocmTuningContext as nullptr by default and not hipified other
operators.
Related PR: https://github.com/microsoft/onnxruntime/pull/14541
---------
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
(1) Support packed QKV format in MultiHeadAttention. This format could
avoid add bias transpose when TRT fused kernel is used.
(2) Add cache for cumulated sequence length computation. For SD, it only
need computed once since sequence length is fixed.
(3) Do not allocate qkv workspace to save memory for packed KV or QKV.
(4) Add unit tests for packed kv and packed qkv format in
MultiHeadAttention
(5) Mark some fusion options for SD only
Performance tests show slight improvement in T4. Average latency reduced
0.15 seconds (from 5.25s to 5.10s) for 512x512 in 50 steps for SD 1.5
models. Memory usage drops from 5.1GB to 4.8GB.
When inferencing real gpt2-based model, found some gaps between CUDA and
ROCm codebase.
The fixes include:
1. minimum code change to fix tensor shape on Attention Op
2. Support optional output tensor with SkipLayerNorm
3. fix a build error found on MI200
---------
Co-authored-by: Ubuntu <ettao@ettao-amd-dev1.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
Add the ability to get and set tuning results of an inference session.
Also add tool to manipulate onnx file to embed the results into the
model file and automatically load it on session initialization.
The third part for stable diffusion CUDA optimizations
(1) Add BiasAdd operator to replace two Add (bias and residual); Add
fusion for BiasAdd
(2) Add Attention fusion for VAE decoder.
(3) Update float16 conversion to handle Resize and GroupNorm. This could
reduce two Cast nodes for each Resize op in fp16 model.
(4) Force inputs and outputs to be float16 to avoid data casts in the
pipeline.
(5) Add options --force_fp32_ops, --inspect etc in optimize script so that
user could force some operator to run in float32 to potentially get
better image quality (with cost of performance).
Performance tests show slight improvement in T4. Average latency reduced
0.1 seconds (from 5.35s to 5.25s) for 512x512 in 50 steps.
### Description
<!-- Describe your changes. -->
1. fuse rel_pos_bias in T5.
2. remove extended masks in T5 decoder and decoder_init since they
generate all zeros
3. fix a bug in onnx_model.py
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
### Description
Remove torch package from requirements to unblock nuget windowsai
pipeline which does not allow --extra-index-url
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
This is exposing the already existent interface of asynchronous work of
all CUDA base EP's (CUDA + TensorRT).
### Motivation and Context
This is something requested in #12216. It will enable users to build an
efficient data pipeline with ONNXRuntime and CUDA pre-/post-processing.
PCI traffic to the CUDA device can be run during inference as soon as
the postprocessing consumed the input buffer and it can be overwritten.
To do this work has to be submitted async to the device. Please see
below screenshots showing the illustration of this using NSight Systems.
Async:
<img width="1401" alt="image"
src="https://user-images.githubusercontent.com/44298237/209894303-706460ed-cbdb-4be2-a2e4-0c111ec875dd.png">
Synchronous:
<img width="1302" alt="image"
src="https://user-images.githubusercontent.com/44298237/209894630-1ce40925-bbd5-470d-b888-46553ab75fb9.png">
Note the gap in between the 2 inference runs due to issuing PCI traffic
in between and to the CPU overhead the active synchronization has.
---------
Co-authored-by: Chi Lo <chi.lo@microsoft.com>
### Description
<!-- Describe your changes. -->
1. fix a bug in relative position bias kernel where seq_len > 32
2. rename extra_add_qk to relative_position_bias
3. support relative_position_bias in multihead attention (B, N, S, S*)
4. gru_gate support by Lei
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
Co-authored-by: Lei Zhang <zhang.huanning@hotmail.com>
### Description
This is a follow-up of
https://github.com/microsoft/onnxruntime/pull/14428 for Stable Diffusion
CUDA optimizations:
(1) use NchwConv to replace Conv in onnx graph and add Tranpose nodes
accordingly
(2) reduce sequential Transpose nodes to at most one.
(3) symbolic shape infer of NchwConv
(4) fix add bias transpose which causes CUDA error (launching more than
1024 threads per block) in inferencing fp32 model.
(5) add models (bert, bart, stable_diffusion subdirectories) to package;
(6) remove option --disable_channels_last
Note that
(1) We can add a few graph transformations to reduce Transpose nodes
further. It is not done in this PR due to time limit.
(2) Stable diffusion 2.1 model outputs black images. It seems that
forcing Attention to float32 could avoid the issue. However it is much
slow to use float32 Attention.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
### Description
Add stable diffusion CUDA kernel optimizations.
The following are included:
(1) GroupNorm operator. This kernel is from TensorRT 8.5.
(2) BiasSplitGelu operator. This kernel is modified from SplitGelu of
TensorRT 8.5. We added bias to the SplitGelu.
(3) NhwcConv operator. This adds support of NHWC format (ONNX Conv
operator uses NCHW format).
(3) Update MultiHeadAttention (packed kv and no bias) for cross
attention. This could avoid transpose of kv for TRT fused cross
attention kernel.
(4) Optimization and benchmark script
Not included:
(1) Script to convert Conv to NhwcConv in onnx graph.
(2) Update symbolic shape inference for NhwcConv.
(3) Add SeqLen2Spatial operator
(4) Documents
Limitations: GroupNorm, BiasSplitGelu and NhwcConv kernels are
implemented based on stable diffusion usage. They might not be
applicable to any input size or dimensions. For example, BiasSplitGelu
requires hidden size to be 2560 | 5120 | 10240, and NhwcConv assumes 4D
input/weight.
There is minor increasement of binary size. For SM=75 only, python
package wheel size adds (33757K - 33640K) = 117 KB. It is possible to
move NHWC from template parameter to constructor to reduce binary size
(with slight cost of performance).
Note: for RTX 4090/4080/4070 Ti, need build with CUDA 11.8 and latest
cuDNN to get best performance.
* Added the OrtDnnlProviderOptions structure to expose configuration
options to the user
* The number of threads can be defined by the user with the -i flag on
the perftest
* Number of threads can also be configured via the OMP_NUM_THREADS
environment variable
* The number of threads defined in the OrtDnnlProviderOptions is
prioritized over the environment variable
### Description
Avoids thread oversubscription caused by OpenMP allocating the maximum
number of threads possible for oneDNN EP. Added support for the
OrtDnnlProviderOptions, this will allow for more EP customization
capabilities, and allows for user defined number of threads.
### Motivation and Context
- Improves performances and allows for user to fine tune the number of
threads
### Description
Introduce cache_dir CLI for graph serialisation.
Replace existing use_compile_network and blob_dump_path cli options for
openvino with a single command line option "cache_dir" specifying the
path that needs to be passed for blob dump/load improving the developer
experience.
### Motivation and Context?
We were having two values to set cache dir which was unnecessary
Co-authored-by: Preetha <preetha.veeramalai@intel.com>
Add script to fuse nodes to optimized operators in stable diffusion 1.5
models, and a script to convert fp32 models to fp16 models. Tested with
stable diffusion 1.5.
Note that the optimized model needs onnxruntime-gpu v1.14 (release candidate
will be available soon).
Note: We will update the script to work with latest diffusers and stable
diffusion v2 and v2.1 models.
### Description
This PR adds PyTorch 2.0 as an option when running the ORT transformer
benchmarking script.
### Motivation and Context
PyTorch released [PyTorch
2.0](https://pytorch.org/get-started/pytorch-2.0/) in the nightly
binaries and a stable release of PyTorch 2.0 is expected in March 2023.
### Description
Add memory efficient attention from CUTLASS.
TODO (in next pull request):
(1) Need performance tests on different GPUs, then add a sequence length
threshold (only activate it for long sequence length).
(2) Merge changes from https://github.com/NVIDIA/cutlass/pull/773 when
it is in cutlass master.
### Description
Adds the below C APIs to support custom ops that wrap an entire model to
be inferenced with an external runtime. The current SNPE EP is an
example of an EP that could be ported to use a custom op wrapper. Ex:
The custom op stores the serialized SNPE DLC binary as a string
attribute. The SNPE model is built when the kernel is created. The model
is inferenced with SNPE APIs on call to the kernel's compute method.
#### C APIs
| API | Description | Why |
| --- | --- | --- |
| `KernelInfo_GetInputCount` | Gets number of inputs from
`OrtKernelInfo`. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfo_GetOutputCount` | Gets number of outputs from
`OrtKernelInfo`. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfo_GetInputName` | Gets an input's name. | Query I/O
characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetOutputName` | Gets an output's name. | Query I/O
characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetInputTypeInfo` | Gets the type/shape information for an
input. | Query I/O characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetOutputTypeInfo` | Gets the type/shape information for
an output. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfoGetAttribute_tensor` | Get a OrtValue tensor stored as an
attribute in the graph node | Extract serialized models, weights, etc. |
| `GetSessionConfigEntry` | Get a session configuration value | Need to
be able to get session-time configurations from within custom op |
| `HasSessionConfigEntry` | Check if session configuration entry exists.
| Need to be able to get session-time configurations from within custom
op |
#### Why so many KernelInfo APIs?<sup>1</sup>
Similar APIs currently exist for `OrtKernelContext`, but not
`OrtKernelInfo`. Note that `OrtKernelContext` is passed to the custom op
on call to its kernel's compute() function. However, `OrtKernelInfo` is
available on kernel creation, which occurs when the session is created.
Having these APIs available from `OrtKernelInfo` allows an operator to
trade-off computation time for session-creation time, and vice versa.
Operators that must build expensive state may prefer to do it during
session creation time instead of compute-time.
SNPE is an example of an EP that needs to be able to query `KernelInfo`
for the name, type, and shape of inputs and outputs in order to build
the model from the serialized DLC data. This is an expensive operation.
Other providers (e.g., OpenVINO) are able to query i/o info from the
serialized model, so they do not strictly need these APIs. However, the
APIs can still be used to validate the expected I/O characteristics.
Additionally, several of our CPU contrib ops currently use the same
internal version of these KernelInfo APIs (Ex:
[qlinear_softmax](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/contrib_ops/cpu/quantization/qlinear_softmax.cc#L71)).
If custom ops are also meant to be a test bed for future ops, then all
custom ops (not just runtime wrappers) would benefit from the addition
of these public KernelInfo APIs (IMO).
#### Example of usage in a custom OP
From
`onnxruntime/test/testdata/custom_op_openvino_wrapper_library/openvino_wrapper.h`
```c++
struct CustomOpOpenVINO : Ort::CustomOpBase<CustomOpOpenVINO, KernelOpenVINO> {
explicit CustomOpOpenVINO(Ort::ConstSessionOptions session_options);
CustomOpOpenVINO(const CustomOpOpenVINO&) = delete;
CustomOpOpenVINO& operator=(const CustomOpOpenVINO&) = delete;
void* CreateKernel(const OrtApi& api, const OrtKernelInfo* info) const;
constexpr const char* GetName() const noexcept {
return "OpenVINO_Wrapper";
}
constexpr const char* GetExecutionProviderType() const noexcept {
return "CPUExecutionProvider";
}
// IMPORTANT: In order to wrap a generic runtime-specific model, the custom operator
// must have a non-homogeneous variadic input and output.
constexpr size_t GetInputTypeCount() const noexcept {
return 1;
}
constexpr size_t GetOutputTypeCount() const noexcept {
return 1;
}
constexpr ONNXTensorElementDataType GetInputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr ONNXTensorElementDataType GetOutputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr OrtCustomOpInputOutputCharacteristic GetInputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr OrtCustomOpInputOutputCharacteristic GetOutputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr bool GetVariadicInputHomogeneity() const noexcept {
return false; // heterogenous
}
constexpr bool GetVariadicOutputHomogeneity() const noexcept {
return false; // heterogeneous
}
std::vector<std::string> GetSessionConfigKeys() const { return {"device_type"}; }
private:
std::unordered_map<std::string, std::string> session_configs_;
};
```
#### How to create a session:
```c++
Ort::Env env;
Ort::SessionOptions session_opts;
Ort::CustomOpConfigs custom_op_configs;
// Create local session config entries for the custom op.
custom_op_configs.AddConfig("OpenVINO_Wrapper", "device_type", "CPU");
// Register custom op library and pass in the custom op configs (optional).
session_opts.RegisterCustomOpsLibrary(lib_name, custom_op_configs);
Ort::Session session(env, model_path.data(), session_opts);
```
### Motivation and Context
Allows creation of simple "wrapper" EPs outside of the main ORT code
base.
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
https://github.com/microsoft/onnxruntime/issues/12843
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
### Description
<!-- Describe your changes. -->
Bug fixed: Quantized models cannot be loaded into ort.InferenceSession
when DedicatedQDQPair is True in extra_options of QDQQuantizer.
Solutions: Add postfix to node names of dedicated QDQ pairs similar to
tensor names of them.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Loading quantized model fails when setting `DedicatedQDQPair` to `True`
in `extra_options` and raise an error as below:
```
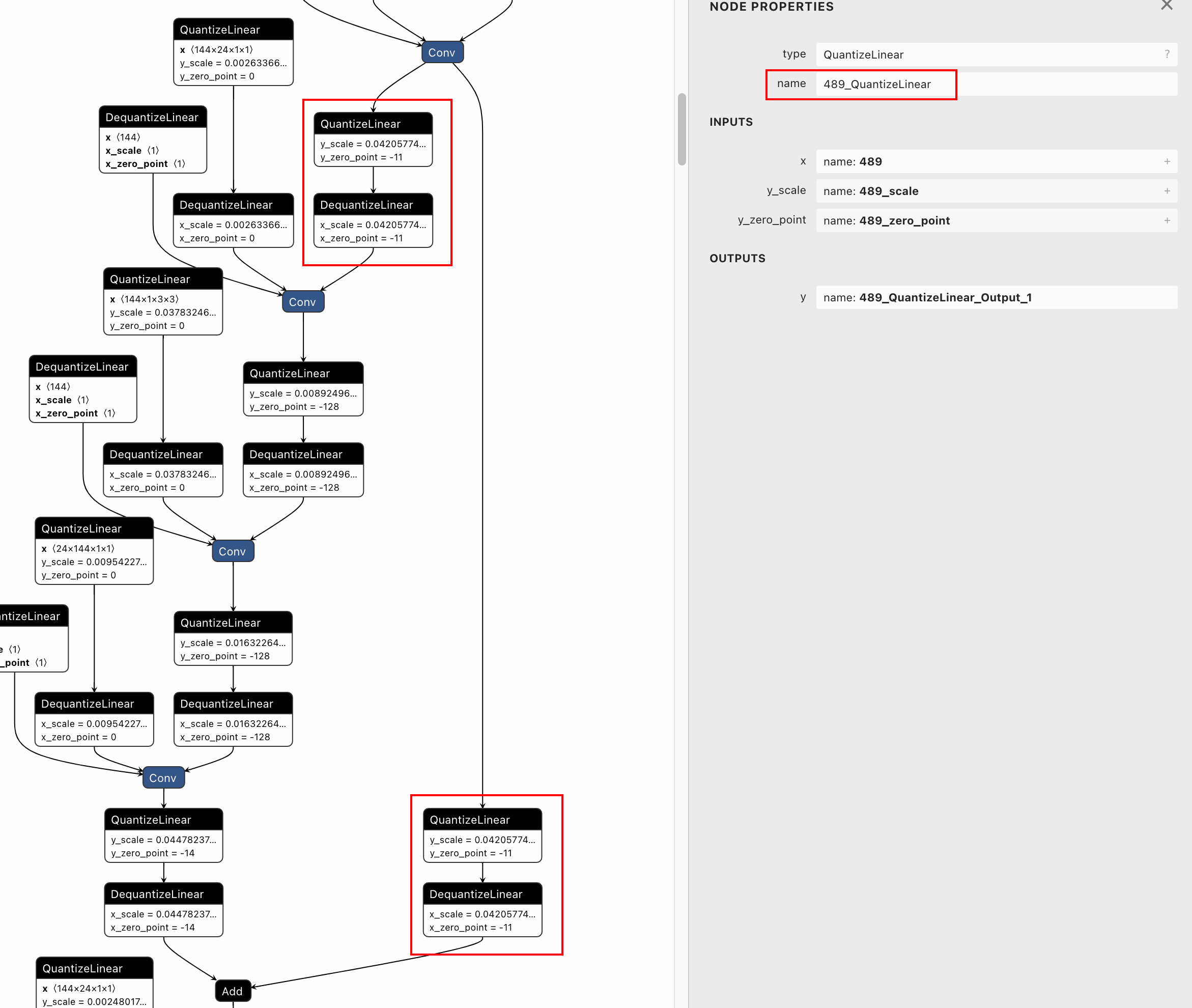
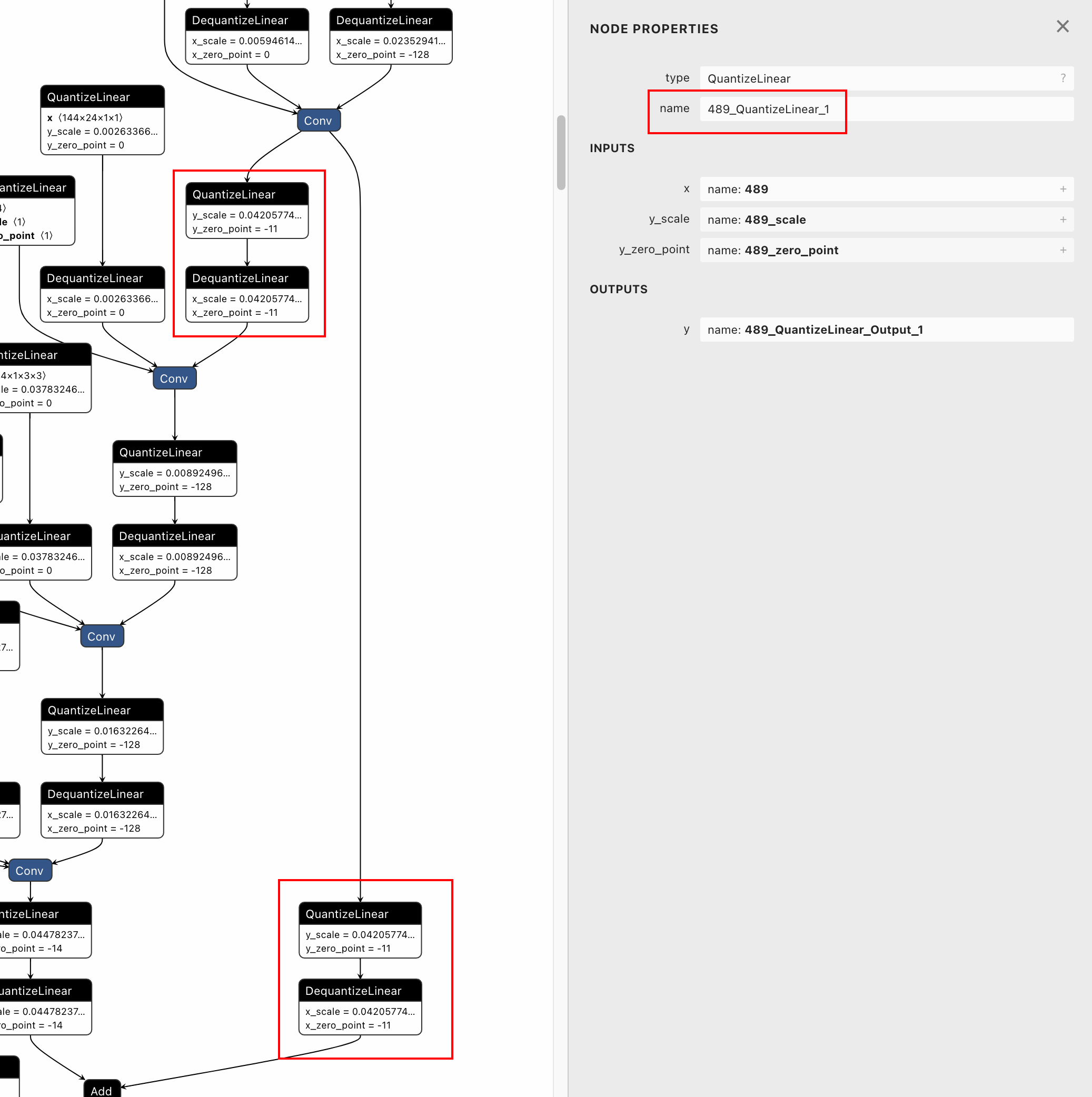
Fail: [ONNXRuntimeError] : 1 : FAIL : Load model from mobilenetv2-opset10-quantized-dedicated.onnx failed:This is an invalid model. Error: two nodes with same node name (489_QuantizeLinear).
```
After visualizing the quantized model using netron, we can find that
both the dedicated QDQ pairs for tensor 489 have the same node names of
"489_QuantizeLinear". So I found that in QDQQuantizer, there is no
unique postfix for the node names of dedicated QDQ pairs.
<img width="1171" alt="image"
src="https://user-images.githubusercontent.com/12782861/212010296-f8cc05ce-c20e-4189-a692-aaf4bbac3a29.png">
Therefore, I add postfix to node names of QDQ pairs similar to doing so
to tensor names. After this modification, the quantized model can be
loaded successfully and dedicated QDQ pairs have different node names.👌🏻
<img width="1037" alt="image"
src="https://user-images.githubusercontent.com/12782861/212010594-78eba39d-eab6-4d77-9ecd-b55f5303bcf4.png">
### Description
<!-- Describe your changes. -->
1. add an optional input to pass in seed
2. two UTs. one for top_p=0.5, another for top_p=0.01(create greedy
search result, in convert_generation.py)
3. fix a bug in cpu kernel
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
Add an option --use_multi_head_attention to fuse model with
MultiHeadAttention operator instead of Attention operator for testing
purpose.
Note that MultiHeadAttention can be used in self-attention and
cross-attention, while Attention operator is used for self-attention
only. In Attention operator, there is packed Q/K/V weights for input
projection, but that MatMul of input projection is excluded from
MultiHeadAttention.
Fix https://github.com/microsoft/onnxruntime/issues/14017.
Before: shape_value = np.asarray([0, 0, np.array([4]), np.array([8])],
dtype=np.int64) raise Error in numpy 1.24.
After: shape_value = np.asarray([0, 0, 4, 8)], dtype=np.int64) is good
in numpy 1.24.
Update test environment to use numpy 1.24.
### Description
<!-- Describe your changes. -->
rename the CrossAttention to MultiheadAttention since this op can also
be used as self attention
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
Move separated Q, K and V (without input projection) from Attention to a
new operator CrossAttention.
The Attention operator is hard to maintain when we need support with and
without input projection in one class. Add a new operator according to
feedback.
Some change might need in the future, but not in this PR:
(1) bias could be optional (We will not proceed that route unless
experiments show that fusing Add bias with MatMul instead of this op
could improve performance).
(2) support packed KV. There are two ways to support it: when key and
value are same Tensor, they are packed; or we can make value as
optional, and use packed mode when value is empty and the key has packed
K/V.
(3) support cached key and value, and other (like relative position
bias), or more attention mask format. They can be added easily without
breaking backward compatible.
(4) ROCm/CPU implementation of this op.
### Description
1. The graph pattern search introduced in
https://github.com/microsoft/onnxruntime/pull/13914/ needs to be
enhanced so that SkipLayerNormalization is supported
2. Fix fp32 parity for GPT-2 while using `SkipLayerNormalization`
fusion. The optional output of SLN needs to also include the bias (if
present) and the added output should be a sum of `input + skip + (bias)`
### Motivation and Context
Fix some breaking tests
### Description
<!-- Describe your changes. -->
Add GemmFastGelu CK implementation.
TODO
1. The performance of CK GemmFastGelu in ORT is not good as using CK
directly, still need to investigate the reason and improve the CK in
ORT.
`GemmFastGeluUnfused float16 NN m=49152 n=3072 k=768 2298.8064 us 100.89
tflops`
`withbias DeviceGemmMultipleD_Xdl_CShuffle<256, 256, 128, 32, 8, 8,
Default> LoopScheduler: Default, PipelineVersion: v1 float16 NN m=49152
n=3072 k=768 2401.9799 us 96.56 tflops`
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
- Adds a new C API `OrtApi::RegisterCustomOpsLibrary_V2` that manages
the lifetime of dynamic library handles (i.e., calls `dlclose` or
`FreeLibrary`).
- Deprecates C API `OrtApi::RegisterCustomOpsLibrary`.
- Adds C++ API wrapper for convenient registering of custom op
libraries.
- `PySessionOptions` is now an alias of `OrtSessionOptions`
### Motivation and Context
The current API for registering custom op libraries loads dynamic
libraries but requires users to handle the release of the corresponding
library handles. Additionally, the user has to make sure to release the
library handle _after_ the session has been destroyed (or the program
segfaults).
The new API automatically cleans up the library and allows the user to
write more straightforward code.
### Description
T5 uses a layer_norm which only scales and doesn't shift, which is also
known as Root Mean Square Layer Normalization.
ORT already have the simplified_layer_norm which is the RMS layer_norm.
This PR extends this T5 layer_norm with support of skip/bias and the
residual output.
This new op is named SkipSimplifiedLayerNorm and has similar interface
as SkipLayerNorm but removes the beta as input
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
### Description
<!-- Describe your changes. -->
when custom decoder onnx model passes in, user can specify eos/pad token
id instead of populating from torch config.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
1. SkipLayerNormalization has a new output
(https://github.com/microsoft/onnxruntime/pull/13988) and the symbolic
shape inference script needs corresponding updates
2. The greedy sampling op
(https://github.com/microsoft/onnxruntime/pull/13426) shouldn't re-use
the logits buffer as its corresponding kernel doesn't seem to support it
yet.
### Motivation and Context
Fix some transformer issues
Implement CloudEP for hybrid inferencing.
The PR introduces zero new API, customers could configure session and
run options to do inferencing with Azure [triton
endpoint.](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-deploy-with-triton?tabs=azure-cli%2Cendpoint)
Sample configuration in python be like:
```
sess_opt.add_session_config_entry('cloud.endpoint_type', 'triton');
sess_opt.add_session_config_entry('cloud.uri', 'https://cloud.com');
sess_opt.add_session_config_entry('cloud.model_name', 'detection2');
sess_opt.add_session_config_entry('cloud.model_version', '7'); // optional, default 1
sess_opt.add_session_config_entry('cloud.verbose', '1'); // optional, default '0', meaning no verbose
...
run_opt.add_run_config_entry('use_cloud', '1') # 0 for local inferencing, 1 for cloud endpoint.
run_opt.add_run_config_entry('cloud.auth_key', '...')
...
sess.run(None, {'input':input_}, run_opt)
```
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
Deprecate one step beam search since it lacks maintenance (some tests
failed) and its performance is not optimal.
For users who still need this feature, please use older version
(<=1.13.1) of onnxruntime to export one step beam search model, and the
model can run in latest onnxruntime.
It is recommend to use
[convert_generation.py](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/python/tools/transformers/convert_generation.py)
to generate beam search onnx model for better performance.
### Description
<!-- Describe your changes. -->
Sampling op for cpu and cuda
support huggingface case and custom case
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
`numpy.bool` has been removed as from 1.24.0.
It was before an alias for python's `bool`.
Fixes https://github.com/huggingface/optimum/issues/610
### Motivation and Context
Numpy 1.24.0 breaks for example IO binding helpers.
### Description
Add support of ONNX conversion of GPT-2 for two stages:
* Stage 1 is the initial stage that has empty past state.
* Stage 2 has non-empty past state and sequence_length is 1.
Add a parameter --stage to specify such stage. For stage 1, we will
enable mask_index for Attention so that we can use fused attention in
CUDA.
Other changes:
(1) use int32 inputs as default (otherwise, there is error in inference)
(2) update gpt2_parity to include SkipLayerNormalization (see
https://github.com/microsoft/onnxruntime/pull/13988) and
EmbedLayerNormalization
(3) get all environment variables that might impact GPT-2 latency in
benchmark_gpt2
### Motivation and Context
To test fused attention for GPT-2 model for
https://github.com/microsoft/onnxruntime/pull/13953.
Allows the user to select from supported backends for gpt2/convert_to_onnx.py. Default behavior is preserved if no provider is selected. This allows the ROCm EP to be selected.
Implement reuse kv_cache past and present tensor in Attention Ops.
Unit test for abover feature.
Utilize the reuse kv_cache for past and present tensor in Greedy Search.
Correctness test for it.
Co-authored-by: Zhang Lei <phill.zhang@gmail.com>
**Description**: This PR including following works:
1. provide stream and related synchronization abstractions in
onnxruntime.
2. enhance onnxruntime's execution planner / executor / memory arena to
support execute multiple streams in parallel.
3. deprecate the parallel executor for cpu.
4. deprecate the Fence mechanism.
5. update the cuda / tensorrt EP to support the stream mechanism,
support running different request in different cuda stream.
**Motivation and Context**
- Why is this change required?
currently, the execution plan is just a linear list of those primitives,
ort will execute them step by step. For any given graph, ORT will
serialize it to a fixed execution order. This sequential execution
design simplifies most scenarios, but it has the following limitations:
1. it is difficult to enable inter-node parallelization, we have a
half-baked parallel executor but it is very difficult to make it work
with GPU.
2. The fence mechanism can work with single gpu stream + cpu thread
case, but when extend to multiple stream, it is difficult to manage the
cross GPU stream synchronizations.
3. our cuda EP rely on the BFCArena to make the memory management work
with the GPU async kernels, but current BFCArena is not aware of the
streams, so it doesn't behavior correctly when run with multiple
streams.
This PR enhance our existing execution plan and executor to support
multiple stream execution. we use an unified algorithm to mange both
single stream and multiple stream scenarios.
This PR mainly focus on the infrastructure support for multiple stream
execution, that is said, given a valid stream assignment, onnxruntime
can execute it correctly. How to generate a good stream assignment for a
given model will be in the future PR.
Co-authored-by: Cheng Tang <chenta@microsoft.com@orttrainingdev9.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Cheng Tang <chenta@microsoft.com>
Co-authored-by: RandySheriffH <48490400+RandySheriffH@users.noreply.github.com>
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
Co-authored-by: cao lei <jslhcl@gmail.com>
Co-authored-by: Lei Cao <leca@microsoft.com>
### Description
Allow Tensor to be scalar if it is not per channel.
### Motivation and Context
[<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
-->](https://github.com/microsoft/onnxruntime/issues/13915)
### Description
<!-- Describe your changes. -->
Sort kernel explorer profile result, the instance is sorted according to
the performance.
1. Set sort kernel as an optional config when we pass parameters through
commandline.
`python gemm_test.py N N float16 M N K` disable sort by default, add
`--sort` to enable sort.
2. 'python gemm_test.py' enable sort by default.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
To pass session_options to Xnnpack EP via
`XnnpackProviderFactoryCreator` for Initializing xnnpack's threadpool.
If you want to use different threadpool size or even disable xnnpack's
threadpool, just setting intra_threadpool to 1 by xnnpack EP's
provider_options.
### Motivation and Context
Co-authored-by: Guangyun Han <guangyunhan@microsoft.com>
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
### Description
- Adds a dockerfile for Ubuntu with TensorRT 8.5.1.1.
- Adds option to run EP Perf pipeline with TensorRT 8.5
### Motivation and Context
Necessary to benchmark models with TensorRT 8.5
### Description
Add cuda support to the on device training python bindings.
### Motivation and Context
Now users can set the execution provider (cpu or cuda) when using python
bindings for on device training apis.
### Description
<!-- Describe your changes. -->
1. Update FastGelu conditions for supported parameters, avoid redundant
configurations participating in tuning。
2. Add kernel explorer test for FastGeluStaticSelection
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
Add DML support to the transformers benchmark.py script
### Motivation and Context
Before this change, running the `benchmark.py` script when the
`onnxruntime-directml` package is installed resulted in an error because
it expects a CUDA or ROCM framework.
Accuracy loss is observed when transformer models such as BERT, DeBERTa,
ViT are running in TRT FP16 mode. The cause is that overflow happens at
Pow op in layer norm.
This PR provides the option to force Pow to run in TRT FP32 precision if
overflow occurs.
Co-authored-by: Ubuntu <azureuser@orteplinuxdev.bxgbzpva45kedp3rhbsbit4phb.jx.internal.cloudapp.net>
(1) Embed layer fusion to work with --use_mask_index.
(2) Parse num_heads and hidden_size from a pattern of Concat shape node.
(3) Fix a typo (CUDAExcecutionProvider=> CUDAExecutionProvider) in eval_squad.py
(4) Update example comments in eval_squad.py to use optimized fp16 model.
(5) Update tests in test_optimizer.py
### Description
This is the first PR of adding remaining Ops for XNPACK EP,
I am gonna add:
- [x] ConvTranspose f32 qu8 q s8
- [x] ~~UnMaxpool f32 qu8 qs8~~
- [x] Resize f32 qu8 q s8
- [ ] GEMM see https://github.com/microsoft/onnxruntime/pull/13126
The remains operation support would be seperated into another PR.
### Motivation and Context
Allows MIGraphX EP to run the following additional tests. Also adds support to get MIGraphX to run eval_squad.py
Reference to the Rocm EP changes: https://github.com/microsoft/onnxruntime/pull/13306
Co-authored-by: Joseph Groenenboom <joseph.groenenboom@amd.com>
Co-authored-by: Ted Themistokleous <tthemist@amd.com>
Need this for benchmarks to function correctly with older containers
This fixes import errors when attempting to run eval_squad.py to
evaluate bert distilled models
Adds a change to the previously merged #12947 which fails when using
Python version < 3.8 to run this script.
Co-authored-by: Ted Themistokleous <tthemist@amd.com>
### Description
<!-- Describe your changes. -->
1. Update the rules for GemmFastGelu fusion, MatMul input x should >=
two dimension, input weight should == two dimension.
2. Add GemmFastGelu fusion test.
3. Add GemmFastGelu TunableOp, only contains the original
implementation(Gemm + FastGelu).
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
Improve the profile explorer by enabling shape sensitivity for GPU
kernels.
### Motivation and Context
Due to problems with the ROCM profiler, it was previously challenging to
retrieve the shapes corresponding to a GPU kernel event. [PR
13546](https://github.com/microsoft/onnxruntime/pull/13549) addresses
these problems, so it's now possible to retrieve shapes from the ORT
ROCM/CUDA profilers. This PR leverages [PR
13546](https://github.com/microsoft/onnxruntime/pull/13549) to enable
shape-sensitive GPU kernel ranking.
Co-authored-by: Abhishek Udupa <abhishek.udupa@microsoft.com>
### Description
Properly cleans up all temporary resources created while running
benchmarks.
Details:
- Dump all temporary artifacts (TRT engines, TRT profiles, inference
profiles, fp16 models) into a temp directory in `/tmp/`. Each model/EP
combination has its own temp directory that is deleted after validation
and benchmarking.
- Allow running both validation and benchmarking in one invocation of
the benchmark.py script. This is necessary to allow the benchmarking
step to reuse artifacts (e.g., TRT engines) created during validation.
Before this PR, we ran validation on all model/EP combinations before
running benchmarks on all combinations again. This required us to keep
all temporary artifacts for all model/EP combinations throughout the
entire run (expensive).
- Create individual functions for validation and benchmarking (split-up
large function that did it all)
### Motivation and Context
The EP Perf pipeline failed to run because the script generated too much
output and the VM ran out of disk space.
This PR enables ORT to execute graphs captured by TorchDynamo. Major compilation code is in `OrtBackend.compile` in ort_backend.py. `register_backend.py` is for plugging `OrtBackend` into TorchDynamo as a compiler.
### Description
<!-- Describe your changes. -->
Fix the input shape of FastGelu
Minor improvement for the documentation of kernel explorer
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Fix the input shape of FastGelu
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Implements a Python script for quick analysis of a generated JSON
profile from ORT.
### Motivation and Context
This PR implements a script that lists kernels that take up the most
time in a JSON profile, from both the CPU and GPU points-of-view. The
script also supports various options for CSV output, grouping of kernels
wrt shape of input tensors and wrt kernel dimensions.
Co-authored-by: Abhishek Udupa <abhishek.udupa@microsoft.com>
**Description**: Describe your changes.
fuse MatMul + FastGelu -> GemmFastGelu
prepare for AMD optimized fused operator GemmFastGelu
usage:
python benchmark.py -g -m bert-base-cased --sequence_length 384
--batch_sizes 128 --provider=rocm -p fp16 --disable_embed_layer_norm
--enable_gemm_fast_gelu
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
### Description
The documentation pipeline does not require an actual GPU, and running
on GPU-capable agents costs more. So to enable running on CPU-only
devices and to potentially consolidate future pipelines, and since the
tests are not actually executed on this device anyway (it just needs to
initialize the EP for the sake of operator kernel enumeration), add an
initialization flag to skip the software device check - this is only an
internal overload not exposed in the public API. See
https://github.com/microsoft/onnxruntime/pull/13308.
### Motivation and Context
- *If it fixes an open issue, please link to the issue here.* NA
Add script to evaluate accuracy of BERT/DistilBERT/Roberta models on question-answering task.
By default, pretrained model
`bert-large-uncased-whole-word-masking-finetuned-squad` will be used if
model name is not specified. If onnx path is not specified, optimum will
be used to export an ONNX model for testing.
Example usage:
* Evaluate with CPU execution provider:
`python eval_squad.py`
* Evaluate with CUDA execution provider:
`python eval_squad.py --use_gpu`
* Evaluate an optimized onnx model for
'distilbert-base-cased-distilled-squad' with sequence lengths
128/192/256/384 on first 100 samples:
`python eval_squad.py -m distilbert-base-cased-distilled-squad --use_gpu
-s 128 192 256 384 --onnx_path ./optimized_fp16.onnx -t 100`
### Description
<!-- Describe your changes. -->
Wrap SkipLayerNormoriginal implementation as a function.
Use it as part of SkipLayerNormTunableOp.
Use it in Kernel explorer to compare the gap between TunableOp and
Original implementation.
the profile output like below:
`float16 8 512 768 <class
'_kernel_explorer.SkipLayerNorm_half_Original'> 23.48 us 804.04 GB/s
float16 8 512 768 <class '_kernel_explorer.SkipLayerNorm_half_Tunable'>
20.41 us 925.00 GB/s
...`
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
<!-- Describe your changes. -->
Fix a bug in GreedySearch Op when batch > 1
Support custom attention mask in GreedySearch and BeamSearch with GPT2
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
Fix bug for percentile calibration module.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Updates EP perf benchmarking scripts to upload new data with an improved table schema. In order to preserve compatibility with the current benchmarking pipeline, we still upload data that uses the old schema as well. These changes are required in order to improve data filtering capabilities and general UX in dashboards that visualize this data.
Details:
- EP names no longer hardcoded as columns for tables that store inference latency, session creation times, memory usage, and model/EP status.
- Add explicit branch, commit ID, and commit date columns to all tables
- Improvements to the docker image building scripts (simplify docker image build; support installing binary TensorRT packages)
- Remove use of deprecated DataFrame.append in favor of pandas.concat.
### Description
Fix Bug where zero point isn't correct under entropy calibration
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
**Description**:
1. Share scalar constant for same data type, value and shape.
2. Fix the order of Graph resolve context clear and
CleanUnusedInitializersAndNodeArgs().
**Share initializer for those who hold same value in same type and
shape, currently only handle scalar value or 1-D single value array.**
The transformation itself did not bring much impact on memory/perf,
instead is helpful to simplify the graph, making it easier for common
subexpression eliminations (CSE). Imagine graphs like this:

Add is NOT shared as inputs of Clip after CSE transformation because,
all Add's second constant input are different NodeArg*, so if we change
all constant initializer share the same NodeArg*, then only one Add will
be preserved after CSE transformation. There are few other similar cases
in one of 1P deberta models.
E2E measurement on 1P DEBERTA model, we see an increase from
SamplesPerSec=562.041593991271 to 568.0106130440271, 1.07% gains.
**Fix the order of Graph resolve context clear and
CleanUnusedInitializersAndNodeArgs().**
Graph resolve context will be cleared every time by end of
Graph.Resolve(), one of the thing to be cleared is the
"inputs_and_initializers" who hold string_view of all initializers.
While CleanUnusedInitializersAndNodeArgs removed some initializers, so
some strings that is referenced by string_view in
"inputs_and_initializers" remain to be there BUT in an invalid state.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Add BART into transformer support, specificalyy for
`BartForConditionalGeneration`
**Motivation and Context**
- fixes#11210
Currently, the custom op beam search is not working in nightly, this PR
should be run with a [custom
commit](10f3d46d92)
Update for ROCm CI before reland tunable GEMM #12853. This PR also update
composable kernel to use CMakes's HIP language support so that we can
mix C/C++ compiler with HIP compiler instead of locking to hip-clang
**Description**: Describe your changes.
This allow us quickly launch a microbench session by, for example:
`python skip_layer_norm_test.py 8 128 128 float32 `
**Description**: Describe your changes.
add SkipLayerNorm vectorize regular case
1. when hidden size <= 1024, SkipLayerNormTunable op can use both small
case and regular case
2. when hidden size > 1024, SkipLayerNormTunable op can only use regular
case.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Some Ops in EP directory instead of contrib_ops directory will
require TunableOp. We will also need to add EP level session tuning
options for it. So move those code all at once.
Also remove duplicated utility functions.
**Description**: This PR adds Ascend CANN execution provider support.
**Motivation and Context**
- Why is this change required? What problem does it solve?
As the info shown in the issue. CANN is the API layer for Ascend
processor. Add CANN EP can allow user run onnx model on Ascend hardware
via onnxruntime
The detail change:
1. Added CANN EP framework.
2. Added the basic operators to support ResNet and VGG model.
3. Added C/C++、Python API support
- If it fixes an open issue, please link to the issue here.
https://github.com/microsoft/onnxruntime/issues/11477
Author:
lijiawei <lijiawei19@huawei.com>
wangxiyuan <wangxiyuan1007@gmail.com>
Co-authored-by: FFrog <ljw1101.vip@gmail.com>
This changes are to align OV 2022.2 Release with ORT . Changes
CPU FP16 Support, dGPU Support, RHEL Dockerfile, Ubuntu 20 Dockerfile
**Motivation and Context**
- This change is required to ensure ORT-OpenVINO Execution Provider is
aligned with latest changes.
- If it fixes an open issue, please link to the issue here.
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: shamaksx <shamax.kshirsagar@intel.com>
Co-authored-by: pratiksha <pratikshax.bapusaheb.vanse@intel.com>
Co-authored-by: pratiksha <mohsinx.mohammad@intel.com>
Co-authored-by: Sahar Fatima <sfatima.3001@gmail.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
Co-authored-by: nmaajidk <n.maajid.khan@intel.com>
Co-authored-by: Mateusz Tabaka <mateusz.tabaka@intel.com>
Co-authored-by: intel <intel@iotgecsp-nuc04.iind.intel.com>
This allow us quickly launch a microbench session by, for example:
```bash
python gemm_test.py T N float16 256 256 65536
```
So that we can quickly see which one is the fastest.
* Fix bug in pybind get_all_operator_schema due to premature reference dropping
* Add updated operator kernels markdown table
* Update build.py to include documentation generation for DML operators too
* Update GPU pipeline to include DML in the build to so operators can be generated.
* Use a separate pipeline stage, feedback from Changming and Scott
* Appease annoying Python linter
* Add onnxruntime_BUILD_UNIT_TESTS=OFF and remove stale --use_dml in cuda stage
* drop nuphar code and configs
* refactor test case
* format python
* remove nuphar from training test
* remove commented nuphar logics
* restore llvm setting
* drop nuphar ci
* fix compile err
* fix compile err
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
* Add support for initial_growth_chunk_size_bytes setting in OrtArenaCfg pybind
* Add overloaded constructor for KVP, UT still in progress
* Fix class member access in pybind, fix unit test
* Resolve linter warnings
* Improve formatting
* Simplify UT
* Fix linter formatting
Co-authored-by: Peter Mcaughan <petermca@microsoft.com>
Fix a few obvious issues:
(1) bert_perf_test.py create session without provider in line 65.
(2) compare_bert_results.py miss a parameter in create_session in line 37
(3) onnx_exporter.py returns value mismatch in lines 667, 690.
(4) remove some imports not used in the scripts.
(5) fusion_utils need not print "Removed 0 cast nodes" or "Removed 0 Identity nodes"...
(6) update requirements for numpy version since gpt2 parity tool use equal_nan in numpy v1.19+
Shape Inference and Model Optimization before Quantization
Model quantization with QDQ format, i.e. inserting QuantizeLinear/DeQuantizeLinear on
the tensor, requires tensor shape information to perform its best. Currently, shape inferencing
works best with optimized model. As a result, it is highly recommended to run quantization
on optimized model with shape information.
This change adds code for model optimization and shape inferencing of the following three steps:
1. Symbolic shape inference.
2. Model optimization
3. ONNX shape inference
At the same time we should recommend model optimization should be turned off during quantization.
As the optimization might change the computation graph, making it harder for the QDQ debugger
to locate matching tensors between original and the quantized models.
* Make ORT as Pytorch JIT backend
LORT likely doesn't work with aten fallback so we only test LORT in its own CI.
* Revert changes to enable external CUDA allocator. Will add it later.
Revert "Revert changes to enable external CUDA allocator. Will add it later."
This reverts commit d5487f2e193014c805505afae8fb577c53667658.
Fix external allocator
* Relax tolerance and remove commented code
* Print more information in CI
* Fix pointer
* Address comments.
1. Reuse ORT-eager mode's environment.
2. Remove unused ctor.
* Use Pytorch master branch as all PRs are merged
Fix
* Refine based on cpplint feedbacks
* Revert changes to allow custom CUDA allocator in public APIs
* Use torch.testing.assert_close
* Use unittest framework
* Switch docker repo
* Rename *.cpp to *.cc
* Address comments
* Add comment
* Use same pipeline file for eager and lort pipelines
* Address comments
* Add yaml comment
* Fix cmake files
* Address comments
* Rename flags, remove printing code, remove dead comment
QDQ loss debug - Weights Matching
Part 2 of QDQ loss debugging tool: given a float model and its qdq model, return the matching of all weight tensors and their corresponding dequantized weights from the qdq model.
* add AddBiasTranspose kernel, new format of weights
* Use compact global_q in GEMM
* sequence_index from BxS to S; new stream for copy
* merge input and output pointers in scratch2
* update default benchmark tests
* add new format 0 for weight and bias
* avoid integer overflow
* check gpu memory
* output summary in benchmark
* add logging
* update unit tests with non empty bias value
* add rocblasGemmHelper and rocblasGemmStridedBatchedHelper for Rocm
Debugger for QDQ loss - activation matching
This is the first part of the QDQ debugger tool: activation matching, where we identify and match corresponding activations from the float model and the qdq model. The idea is that during quantization, we have an original float model and a qdq model. The debugger can run the two models side by side using the same input data. By comparing intermediate activations, we can help the model author figure out where the values differ, and take steps to reduce precision loss.
Fix minor bug in qdq quantization tool
Motivation and Context
Relu node is removed in qdq quantization tool if it can be merged to its input node. When performing the removal, we forgot to check whether the input is actually the graph input
Python module for dumping activation tensors when running an ONNX model
This is the first step towards a quantization debugging tool. We dump the activation tensors. Next step would be to compare them: original model vs quantized model (running with same input) to see where the difference becomes significant.
* adding conditional variable again
* Adding split test cases in python
* Adding python cases for split
* Enable s8s8 split
* Optimize input
* Revert "Remove git and python packages from the docker images used by Zip-Nuget-Java-Nodejs Packaging Pipeline (#11651)"
This reverts commit d5e34acb
* Revert "Revert "Remove git and python packages from the docker images used by Zip-Nuget-Java-Nodejs Packaging Pipeline (#11651)""
This reverts commit 3c1a330dd3afeb55aa7eabb8ebea39b6deb37bad.
* format file
* Update c-api-linux-cpu.yml
* Update c-api-linux-cpu.yml
* Update c-api-linux-cpu.yml
* Reformat file
* Reformat file
* format file
* Optimize input
* Remove unused import
* Remove useless init
* Format split.py with black
* set zero point to 0 if all value are 0.0
* fix bug: lower version of numpy.finfo doesn't have smallest_subnormal
* check scale to make sure it is not subnormal
* Split GemmBase RocBlasGemm
* Add composable kernel GEMM baseline
* Make linter happy
* Address review comment
* Update bert cases with batchsize
* Adjust includes to fix IWYU lint
* Only builds and links used ck kernels to improve building time
* Remove warmup run on SelectImpl
* Add comment to utility function
* Mute cpplint
* Make RocBlasGemm<T>::SelectImpl semantically correct
* Add reduced basic test cases for ck gemm
* More robust gemm testing
* Fix warnings
* Fix grammar
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}