Summary:
The Flake8 job has been passing on `master` despite giving warnings for [over a month](https://github.com/pytorch/pytorch/runs/1716124347). This is because it has been using a regex that doesn't recognize error codes starting with multiple letters, such as those used by [flake8-executable](https://pypi.org/project/flake8-executable/). This PR corrects the regex, and also adds another step at the end of the job which asserts that Flake8 actually gave no error output, in case similar regex issues appear in the future.
Tagging the following people to ask what to do to fix these `EXE002` warnings:
- https://github.com/pytorch/pytorch/issues/50629 authored by jaglinux, approved by rohan-varma
- `test/distributed/test_c10d.py`
- https://github.com/pytorch/pytorch/issues/51262 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/__init__.py`
- `torch/utils/data/datapipes/iter/loadfilesfromdisk.py`
- `torch/utils/data/datapipes/iter/listdirfiles.py`
- `torch/utils/data/datapipes/iter/__init__.py`
- `torch/utils/data/datapipes/utils/__init__.py`
- `torch/utils/data/datapipes/utils/common.py`
- https://github.com/pytorch/pytorch/issues/51398 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/readfilesfromtar.py`
- https://github.com/pytorch/pytorch/issues/51599 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/readfilesfromzip.py`
- https://github.com/pytorch/pytorch/issues/51704 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/routeddecoder.py`
- `torch/utils/data/datapipes/utils/decoder.py`
- https://github.com/pytorch/pytorch/issues/51709 authored by glaringlee, approved by ejguan
- `torch/utils/data/datapipes/iter/groupbykey.py`
Specifically, the question is: for each of those files, should we remove the execute permissions, or should we add a shebang? And if the latter, which shebang?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52750
Test Plan:
The **Lint / flake8-py3** job in GitHub Actions:
- [this run](https://github.com/pytorch/pytorch/runs/1972039886) failed, showing that the new regex catches these warnings properly
- [this run](https://github.com/pytorch/pytorch/runs/1972393293) succeeded and gave no output in the "Run flake8" step, showing that this PR fixed all Flake8 warnings
- [this run](https://github.com/pytorch/pytorch/pull/52755/checks?check_run_id=1972414849) (in https://github.com/pytorch/pytorch/issues/52755) failed, showing that the new last step of the job successfully catches Flake8 warnings even without the regex fix
Reviewed By: walterddr, janeyx99
Differential Revision: D26637307
Pulled By: samestep
fbshipit-source-id: 572af6a3bbe57f5e9bd47f19f37c39db90f7b804
Summary:
The GitHub-hosted runner has maximum 14 GB disk space, which is not enough to host the nightly Docker build.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52148
Test Plan: CI workflow
Reviewed By: samestep
Differential Revision: D26406295
Pulled By: xuzhao9
fbshipit-source-id: 18a0dff45613649d6c15b8e1e9ca85042f648afd
Summary:
Set CUDA_VERSION to 11.2.0 since Nvidia name their docker image on Ubuntu 18.04 to be nvidia/cuda:11.2.0-cudnn8-devel-ubuntu18.04.
Note that cudatoolkit 11.2.0 is not yet on [conda](https://repo.anaconda.com/pkgs/main/linux-64/), and we need to wait for that before merging this PR.
- https://hub.docker.com/r/nvidia/cuda/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51990
Reviewed By: samestep
Differential Revision: D26371193
Pulled By: xuzhao9
fbshipit-source-id: 76915490dc30ddb03ceeeadb3c45a6c02b60401e
Summary:
Currently PyTorch repository provides Dockerfile to build Docker with nightly builds, but it doesn't have CI to actually build those Dockers.
This PR adds a GitHub action workflow to create PyTorch nightly build Docker and publish them to GitHub Container Registry.
Also, add "--always" option to the `git describe --tags` command that generates the Docker image tag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51755
Test Plan: Manually trigger the workflow build in the GitHub Actions web UI.
Reviewed By: seemethere
Differential Revision: D26320180
Pulled By: xuzhao9
fbshipit-source-id: e00b472df14f5913cab9b06a41e837014e87f1c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51500
I'm going to add some new Target types shortly, so having tighter
types for the individual unions will make it clearer which ones
are valid.
This is also the first use of typing_extensions in the codegen,
and I want to make sure it works.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D26187854
Pulled By: ezyang
fbshipit-source-id: 6a9842f19b3f243b90b210597934db902b816c21
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51365
We have a pretty big backlog of PRs when it comes to checking for stale and the action only supports processing 30 PRs at a given time.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26153785
Pulled By: seemethere
fbshipit-source-id: 585b36068683e04cf4e2cc59013482f143ec30a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51306
Title wasn't rendering correctly so let's just remove it altogether, it
shouldn't matter that much in the long run
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: samestep
Differential Revision: D26134907
Pulled By: seemethere
fbshipit-source-id: 54485cb66fb57f549255f9e7bcfb39b51fe69776
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51298
newlines weren't being respected so just add them through the `<br>` html
tag.
Also changes the wording for open source ones to designate that a
maintainer may be needed to unstale a particular PR.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: janeyx99
Differential Revision: D26131126
Pulled By: seemethere
fbshipit-source-id: 465bfc0ba4dc16a7a90e0c03c33d551184e35f5b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51237
Stales pull requests at 150 days and then will close them at 180 days
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: stonks
Reviewed By: yns88
Differential Revision: D26112086
Pulled By: seemethere
fbshipit-source-id: c6b3865aa5cde3415b6dd6622c308895a16e805f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51124
Original commit changeset: 1c7133627da2
Test Plan: Test locally with interpreter_test and on CI
Reviewed By: suo
Differential Revision: D26077905
fbshipit-source-id: fae83bf9822d79e9a9b5641bc5191a7f3fdea78d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50458
libinterpreter.so contains a frozen python distribution including
torch-python bindings.
Freezing refers to serializing bytecode of python standard library modules as
well as the torch python library and embedding them in the library code. This
library can then be dlopened multiple times in one process context, each
interpreter having its own python state and GIL. In addition, each python
environment is sealed off from the filesystem and can only import the frozen
modules included in the distribution.
This change relies on newly added frozenpython, a cpython 3.8.6 fork built for this purpose. Frozenpython provides libpython3.8-frozen.a which
contains frozen bytecode and object code for the python standard library.
Building on top of frozen python, the frozen torch-python bindings are added in
this diff, providing each embedded interpreter with a copy of the torch
bindings. Each interpreter is intended to share one instance of libtorch and
the underlying tensor libraries.
Known issues
- Autograd is not expected to work with the embedded interpreter currently, as it manages
its own python interactions and needs to coordinate with the duplicated python
states in each of the interpreters.
- Distributed and cuda stuff is disabled in libinterpreter.so build, needs to be revisited
- __file__ is not supported in the context of embedded python since there are no
files for the underlying library modules.
using __file__
- __version__ is not properly supported in the embedded torch-python, just a
workaround for now
Test Plan: tested locally and on CI with cmake and buck builds running torch::deploy interpreter_test
Reviewed By: ailzhang
Differential Revision: D25850783
fbshipit-source-id: a4656377caff25b73913daae7ae2f88bcab8fd88
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50162
Adds an option to not run the build workflow when the `run_build`
parameter is set to false
Should reduce the amount of double workflows that are run by
pytorch-probot
Uses functionality introduced in https://github.com/pytorch/pytorch-probot/pull/18
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Test Plan: Imported from OSS
Reviewed By: yns88
Differential Revision: D25812971
Pulled By: seemethere
fbshipit-source-id: 4832170f6abcabe3f385f47a663d148b0cfe2a28
Summary:
It is now running for forks, and generates a lot of failure message to owner of forks.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49934
Reviewed By: mruberry
Differential Revision: D25739552
Pulled By: seemethere
fbshipit-source-id: 0f9cc430316c0a5e9972de3cdd06d225528c81c2
Summary:
This PR moves the list of Flake8 requirements/versions out of `.github/workflows/lint.yml` and into its own file `requirements-flake8.txt`. After (if) this PR is merged, I'll modify the Flake8 installation instructions on [the "Lint as you type" wiki page](https://github.com/pytorch/pytorch/wiki/Lint-as-you-type) (and its internal counterpart) to just say to install from that new file, rather than linking to the GitHub Actions YAML file and/or giving a command with a set of packages to install that keeps becoming out-of-date.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/49032
Test Plan:
Either look at CI, or run locally using [act](https://github.com/nektos/act):
```sh
act -P ubuntu-latest=nektos/act-environments-ubuntu:18.04 -j flake8-py3
```
Reviewed By: janeyx99
Differential Revision: D25404037
Pulled By: samestep
fbshipit-source-id: ba4d1e17172a7808435df06cba8298b2b91bb27c
Summary:
Convert the NVFUSER's runtime CUDA sources (under `.../jit/codegen/cuda/runtime`) to string literals, then include the headers with the generated literals.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48283
Reviewed By: mrshenli
Differential Revision: D25163362
Pulled By: ngimel
fbshipit-source-id: 4e6c181688ddea78ce6f3c754fee62fa6df16641
Summary:
Currently ([example](https://github.com/pytorch/pytorch/runs/1381883195)), ShellCheck is run on `*.sh` files in `.jenkins/pytorch`, but it uses a three-and-a-half-year-old version, and doesn't fail the lint job despite yielding many warnings. This PR does the following:
- update ShellCheck to v0.7.1 (and generally make it always use the latest `"stable"` release), to get more warnings and also enable the directory-wide directives that were introduced in v0.7.0 (see the next bullet)
- move the rule exclusions list from a variable in `.jenkins/run-shellcheck.sh` to a [declarative file](https://github.com/koalaman/shellcheck/issues/725#issuecomment-469102071) `.jenkins/pytorch/.shellcheckrc`, so now editor integrations such as [vscode-shellcheck](https://github.com/timonwong/vscode-shellcheck) give the same warnings as the CLI script
- fix all ShellCheck warnings in `.jenkins/pytorch`
- remove the suppression of ShellCheck's return value, so now it will fail the lint job if new warnings are introduced
---
While working on this, I was confused because I was getting fairly different results from running ShellCheck locally versus what I saw in the CI logs, and also different results among the laptop and devservers I was using. Part of this was due to different versions of ShellCheck, but there were even differences within the same version. For instance, this command should reproduce the results in CI by using (almost) exactly the same environment:
```bash
act -P ubuntu-latest=nektos/act-environments-ubuntu:18.04 -j quick-checks \
| sed '1,/Run Shellcheck Jenkins scripts/d;/Success - Shellcheck Jenkins scripts/,$d' \
| cut -c25-
```
But the various warnings were being displayed in different orders, so it was hard to tell at a glance whether I was getting the same result set or not. However, piping the results into this ShellCheck-output-sorting Python script showed that they were in fact the same:
```python
import fileinput
items = ''.join(fileinput.input()).split('\n\n')
print(''.join(sorted(f'\n{item.strip()}\n\n' for item in items)), end='')
```
Note that while the above little script worked for the old version (v0.4.6) that was previously being used in CI, it is a bit brittle, and will not give great results in more recent ShellCheck versions (since they give more different kinds of output besides just a list of warnings).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47786
Reviewed By: seemethere
Differential Revision: D24900522
Pulled By: samestep
fbshipit-source-id: 92d66e1d5d28a77de5a4274411598cdd28b7d436
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46985.
Can someone comment on whether the "Run flake8" step should fail if `flake8` produces errors? This PR makes sure the errors are still shown, but [the job linked from the issue](https://github.com/pytorch/pytorch/runs/1320258832) also shows that the failure of that step seems to have caused the "Add annotations" step not to run.
Is this what we want, or should I instead revert back to the `--exit-zero` behavior (in this case by just removing the `-o pipefail` from this PR) that we had before https://github.com/pytorch/pytorch/issues/46740? And if the latter, then (how) should I modify this `flake8-py3` job to make sure it fails when `flake8` fails (assuming it didn't already do that?)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46990
Reviewed By: VitalyFedyunin
Differential Revision: D24593573
Pulled By: samestep
fbshipit-source-id: 361392846de9fadda1c87d2046cf8d26861524ca
Summary:
Caffe2 and Torch currently does not have a consistent mechanism for determining if a kernel has launched successfully. The result is difficult-to-detect or silent errors. This diff provides functionality to fix that. Subsequent diffs on the stack fix the identified issues.
Kernel launch errors may arise if invalid launch parameters (number of blocks, number of threads, shared memory, or stream id) are specified incorrectly for the hardware or for other reasons. Interestingly, unless these launch errors are specifically checked for CUDA will silently fail and return garbage answers which can affect downstream computation. Therefore, catching launch errors is important.
Launches are currently checked by placing
```
AT_CUDA_CHECK(cudaGetLastError());
```
somewhere below the kernel launch. This is bad for two reasons.
1. The check may be performed at a site distant to the kernel launch, making debugging difficult.
2. The separation of the launch from the check means that it is difficult for humans and static analyzers to determine whether the check has taken place.
This diff defines a macro:
```
#define TORCH_CUDA_KERNEL_LAUNCH_CHECK() AT_CUDA_CHECK(cudaGetLastError())
```
which clearly indicates the check.
This diff also introduces a new test which analyzes code to identify kernel launches and determines whether the line immediately following the launch contains `TORCH_CUDA_KERNEL_LAUNCH_CHECK();`.
A search of the Caffe2 codebase identifies 104 instances of `AT_CUDA_CHECK(cudaGetLastError());` while the foregoing test identifies 1,467 launches which are not paired with a check. Visual inspection indicates that few of these are false positives, highlighting the need for some sort of static analysis system.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46474
Test Plan:
The new test is run with:
```
buck test //caffe2/test:kernel_launch_checks -- --print-passing-details
```
And should be launched automatically with the other land tests. (TODO: Is it?)
The test is currently set up only to provide warnings but can later be adjusted to require checks.
Otherwise, I rely on the existing test frameworks to ensure that changes resulting from reorganizing existing launch checks don't cause regressions.
Reviewed By: ngimel
Differential Revision: D24309971
Pulled By: r-barnes
fbshipit-source-id: 0dc97984a408138ad06ff2bca86ad17ef2fdf0b6
Summary:
[Previously](https://github.com/pytorch/pytorch/runs/1293724033) Flake8 was run using `flake8-mypy`, which didn't change the actual lint output, and undesirably resulted in this noisy message being printed many times:
```
/opt/hostedtoolcache/Python/3.9.0/x64/lib/python3.9/site-packages is in the MYPYPATH. Please remove it.
See https://mypy.readthedocs.io/en/latest/running_mypy.html#how-mypy-handles-imports for more info
```
Since `mypy` is already run in other test scripts, this PR simply removes it from the Flake8 setup. This PR also removes the `--exit-zero` flag from Flake8, because currently Flake8 gives no error output, so it would be valuable to know if it ever does happen to return error output.
(This doesn't strike me as a perfect solution since now it's a bit harder to reproduce the Flake8 behavior when running locally with `flake8-mypy` installed, but it's the easiest way to fix it in CI specifically.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46740
Reviewed By: janeyx99
Differential Revision: D24487904
Pulled By: samestep
fbshipit-source-id: d534fdeb18e32d3bc61406462c1cf955080a688f
Summary:
I got confused while locally running some of the `quick-checks` lints (still confused by `.jenkins/run-shellcheck.sh` but that's a separate matter) so I'm adding a comment to the "Ensure C++ source files are not executable" step in case someone in the future tries it and gets confused like I did.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46698
Reviewed By: walterddr
Differential Revision: D24470718
Pulled By: samestep
fbshipit-source-id: baacd8f414aa41b9b7b7aac765d938f21085eac5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46244
- What does the generated binding code do?
The Python binding codegen produces code that takes the input list of
PyObjects, finds the matching ATen C++ function using PythonArgParser,
converts the PyObjects into C++ types and calls the ATen C++ function:
```
+--------+ parsing +------------------------+ binding +-----------------------+
| PyObjs | ---------> | PythonArgParser Output | ---------> | Cpp Function Dispatch |
+--------+ +------------------------+ +-----------------------+
```
- Are Python arguments 1-1 mapped to C++ arguments?
Python arguments might be reordered, packed, unpacked when binding to
C++ arguments, as illustrated below:
```
// Binding - Reorder & Packing
// aten::empty.names(int[] size, *, Dimname[]? names, ScalarType? dtype=None, Layout? layout=None,
Device? device=None, bool? pin_memory=None, MemoryFormat? memory_format=None) -> Tensor
Python Args Cpp Args
-----------------------------------------------------------
0: size size
1: names names
2: memory_format -------+
3: dtype -----+-|--> options
4: layout / |
5: device / +--> memory_format
6: pin_memory /
7: requires_grad -+
// Binding - Unpacking
// aten::max.names_dim(Tensor self, Dimname dim, bool keepdim=False) -> (Tensor values, Tensor indices)
Python Args Cpp Args
-----------------------------------------------------------
+----> max
/-----> max_values
0: input / self
1: dim / dim
2: keepdim / keepdim
3: out -----+
```
- Why do we want to rewrite the python binding codegen?
The old codegen takes Declarations.yaml as input. It doesn't distinguish
between Python arguments and C++ arguments - they are all mixed together
as a bag of non-typed dict objects. Different methods process these arg
objects and add new attributes for various different purposes. It's not so
obvious to figure out the semantics of these attributes. The complicated
binding logic happens implicitly and scatteredly.
```
+--------------------+
| Native Functions |
+--------------------+
|
|
v
+--------------------+
| Cpp Signatures |
+--------------------+
|
|
v
+--------------------+
| Declarations.yaml |
+--------------------+
| +-------------------------------------+
| +-------> | PythonArgParser Schema |
| | +-------------------------------------+
| | .
| | .
v | .
+--------------------+ +-------------------------------------+
| NonTyped Args Objs | --> | PythonArgParser -> Cpp Args Binding |
+--------------------+ +-------------------------------------+
| .
| .
| .
| +-------------------------------------+
+-------> | Cpp Function Dispatch |
+-------------------------------------+
```
This PR leverages the new immutable data models introduced in the new
aten codegen. It introduces dedicated data models for python schema.
This way, we can not only avoid subtle Declaration.yaml conversions but
also decouple the generation of python schema, python to c++ binding and
c++ function call.
The ultimate state will be like the following diagram:
```
+-------------------+ +-------------------------------------+
+-------> | Python Signatures | --> | PythonArgParser Schema |
| +-------------------+ +-------------------------------------+
| | .
| | .
| | .
+------------------+ | +-------------------------------------+
| Native Functions | +-------> | PythonArgParser -> Cpp Args Binding |
+------------------+ | +-------------------------------------+
| | .
| | .
| | .
| +-------------------+ +-------------------------------------+
+-------> | Cpp Signatures | --> | Cpp Function Dispatch |
+-------------------+ +-------------------------------------+
```
This PR has migrated the core binding logic from
tools/autograd/gen_python_functions.py to tools/codegen/api/python.py.
It produces the byte-for-byte same results (tested with #46243).
Will migrate the rest of gen_python_functions.py in subsequent PRs.
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D24388874
Pulled By: ljk53
fbshipit-source-id: f88b6df4e917cf90d868a2bbae2d5ffb680d1841
Summary:
Those files are never directly built, only included in other files.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46335
Reviewed By: albanD
Differential Revision: D24316737
Pulled By: gchanan
fbshipit-source-id: 67bb95e7f4450e3bbd0cd54f15fde9b6ff177479
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46043
As title, this is necessary for some internal linter thing
Test Plan: Imported from OSS
Reviewed By: malfet
Differential Revision: D24197316
Pulled By: suo
fbshipit-source-id: 07e69fd6ce1937a0caa5838d6995eeed1be5162d
Summary:
This commit updates `.github/workflows/jit_triage.yml` to use the new `oncall: jit` tag instead of the old `jit` tag.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45613
Reviewed By: izdeby
Differential Revision: D24032388
Pulled By: SplitInfinity
fbshipit-source-id: 6631a596b2f80bdb322caa74adaf0dc2cb146350
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43711
this makes them available in forward if needed
No change to the file content, just a copy-paste.
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23454146
Pulled By: albanD
fbshipit-source-id: 6269a4aaf02ed53870fadf8b769ac960e49af195
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/42629
How to approach reviewing this diff:
- The new codegen itself lives in `tools/codegen`. Start with `gen.py`, then read `model.py` and them the `api/` folder. The comments at the top of the files describe what is going on. The CLI interface of the new codegen is similar to the old one, but (1) it is no longer necessary to explicitly specify cwrap inputs (and now we will error if you do so) and (2) the default settings for source and install dir are much better; to the extent that if you run the codegen from the root source directory as just `python -m tools.codegen.gen`, something reasonable will happen.
- The old codegen is (nearly) entirely deleted; every Python file in `aten/src/ATen` was deleted except for `common_with_cwrap.py`, which now permanently finds its home in `tools/shared/cwrap_common.py` (previously cmake copied the file there), and `code_template.py`, which now lives in `tools/codegen/code_template.py`. We remove the copying logic for `common_with_cwrap.py`.
- All of the inputs to the old codegen are deleted.
- Build rules now have to be adjusted to not refer to files that no longer exist, and to abide by the (slightly modified) CLI.
- LegacyTHFunctions files have been generated and checked in. We expect these to be deleted as these final functions get ported to ATen. The deletion process is straightforward; just delete the functions of the ones you are porting. There are 39 more functions left to port.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Reviewed By: bhosmer
Differential Revision: D23183978
Pulled By: ezyang
fbshipit-source-id: 6073ba432ad182c7284a97147b05f0574a02f763
Summary:
It is often that the conversion from torch operator to onnx operator requires input rank/dtype/shape to be known. Previously, the conversion depends on tracer to provide these info, leaving a gap in conversion of scripted modules.
We are extending the export with support from onnx shape inference. If enabled, onnx shape inference will be called whenever an onnx node is created. This is the first PR introducing the initial look of the feature. More and more cases will be supported following this PR.
* Added pass to run onnx shape inference on a given node. The node has to have namespace `onnx`.
* Moved helper functions from `export.cpp` to a common place for re-use.
* This feature is currently experimental, and can be turned on through flag `onnx_shape_inference` in internal api `torch.onnx._export`.
* Currently skipping ONNX Sequence ops, If/Loop and ConstantOfShape due to limitations. Support will be added in the future.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40628
Reviewed By: mrshenli
Differential Revision: D22709746
Pulled By: bzinodev
fbshipit-source-id: b52aeeae00667e66e0b0c1144022f7af9a8b2948
Summary:
**Summary**
This commit updates the repository's pull request template to remind contributors to tag the issue that their pull request addresses.
**Fixes**
This commit fixes https://github.com/pytorch/pytorch/issues/35319.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41812
Reviewed By: gmagogsfm
Differential Revision: D22667902
Pulled By: SplitInfinity
fbshipit-source-id: cda5ff7cbbbfeb89c589fd0dfd378bf73a59d77b
Summary:
**Summary**
This commit fixes the JIT triage workflow based on testing done in my
own fork.
**Test Plan**
This commit has been tested against my own fork. This commit is
currently at the tip of my master branch, and if you open an issue in my
fork and label it JIT, it will be added to the Triage Review project in
that fork under the Needs triage column.
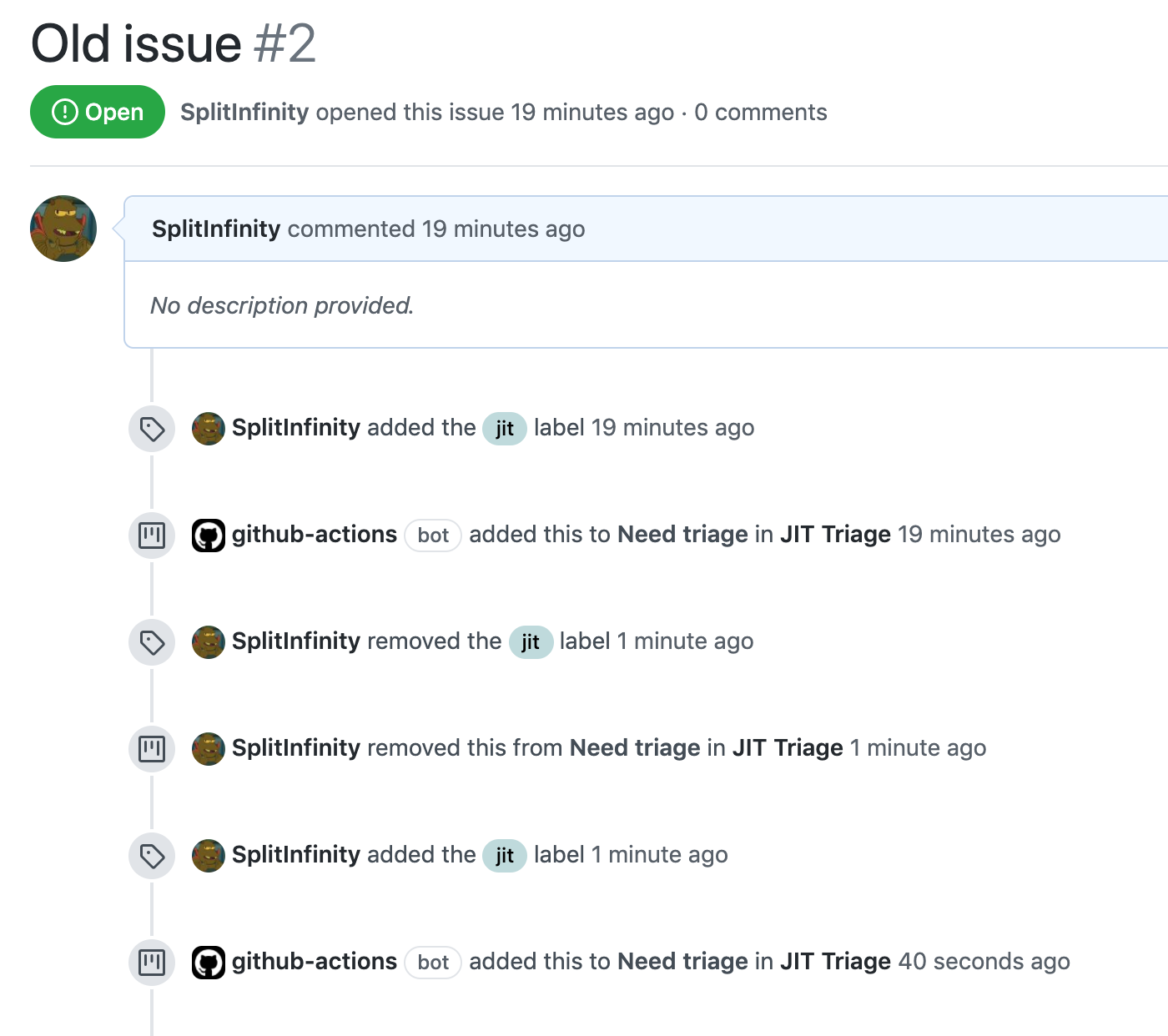
*Old issue that is labelled JIT later*
<img width="700" alt="Captura de Pantalla 2020-07-08 a la(s) 6 59 42 p m" src="https://user-images.githubusercontent.com/4392003/86988551-5b805100-c14d-11ea-9de3-072916211f24.png">
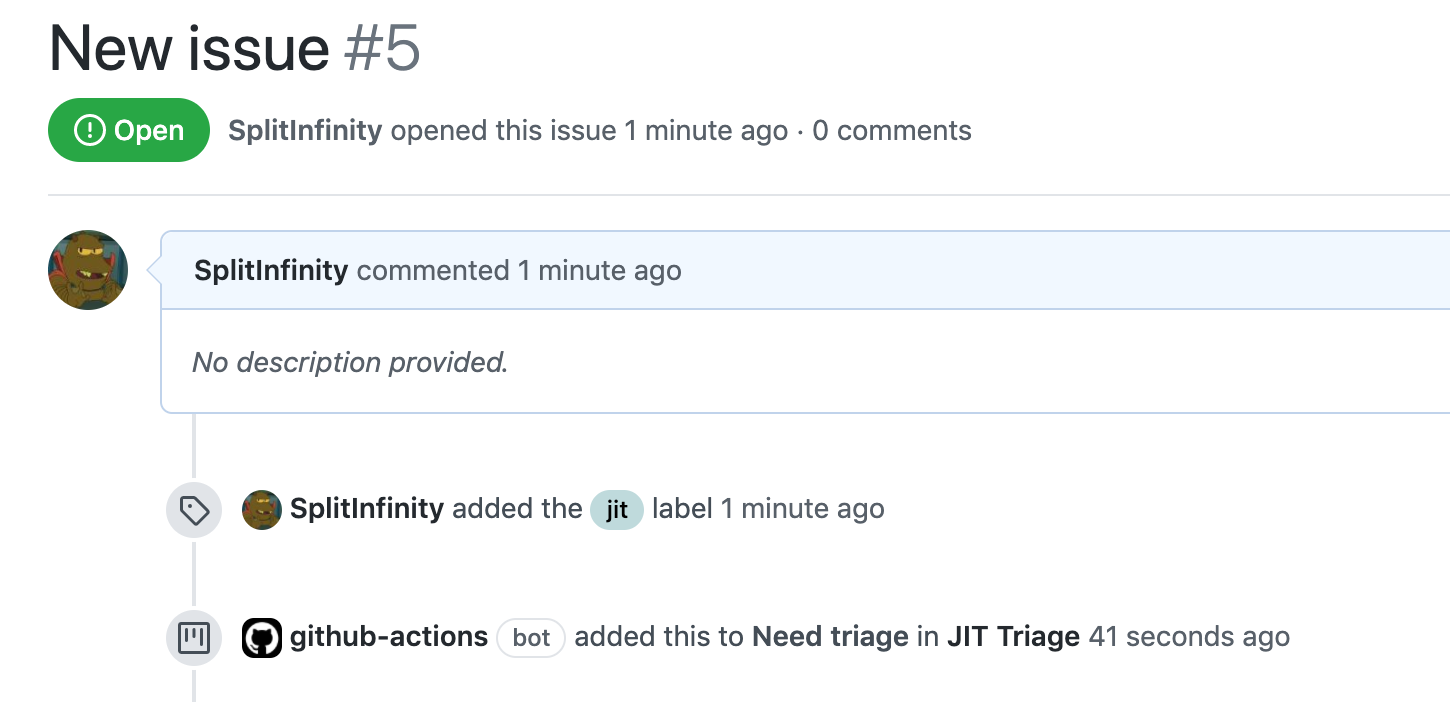
*New issue that is opened with the JIT label*
<img width="725" alt="Captura de Pantalla 2020-07-08 a la(s) 6 59 17 p m" src="https://user-images.githubusercontent.com/4392003/86988560-60dd9b80-c14d-11ea-94f0-fac01a0d239b.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41170
Differential Revision: D22460584
Pulled By: SplitInfinity
fbshipit-source-id: 278483cebbaf3b35e5bdde2a541513835b644464
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41056
**Summary**
This commit adds a new GitHub workflow that automatically adds a card to
the "Need triage" section of the project board for tracking JIT triage
for each new issue that is opened and labelled "jit".
**Test Plan**
???
Test Plan: Imported from OSS
Differential Revision: D22444262
Pulled By: SplitInfinity
fbshipit-source-id: 4e7d384822bffb978468c303322f3e2c04062644
{kind=link}
{kind=link}