Summary:
If SELECTED_OP_LIST is specified as a relative path in command line, CMake build will fail.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33942
Differential Revision: D20392797
Pulled By: ljk53
fbshipit-source-id: dffeebc48050970e286cf263bdde8b26d8fe4bce
Summary:
When a system has ROCm dev tools installed, `scripts/build_mobile.sh` tried to use it.
This PR fixes looking up unused ROCm library when building libtorch mobile.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34478
Differential Revision: D20388147
Pulled By: ljk53
fbshipit-source-id: b512c38fa2d3cda9ac20fe47bcd67ad87c848857
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34410
### Summary
Currently, the iOS jobs are not being run on PRs anymore. This is because all iOS jobs have specified the `org-member` as a context which used to include all pytorch members. But seems like recently this rule has changed. It turns out that only users from the admin group or builder group can have access right to the context values. https://circleci.com/gh/organizations/pytorch/settings#contexts/2b885fc9-ef3a-4b86-8f5a-2e6e22bd0cfe
This PR will remove `org-member` from the iOS simulator build which doesn't require code signing. For the arm64 builds, they'll only be run on master, not on PRs anymore.
### Test plan
- The iOS simulator job should be able to appear in the PR workflow
Test Plan: Imported from OSS
Differential Revision: D20347270
Pulled By: xta0
fbshipit-source-id: 23f37d40160c237dc280e0e82f879c1d601f72ac
Summary:
Currently testing against the older release `1.4.0` with:
```
PYTORCH_S3_FROM=nightly TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 scripts/release/promote/libtorch_to_s3.sh
PYTORCH_S3_FROM=nightly TEST_WITHOUT_GIT_TAG=1 TEST_PYTORCH_PROMOTE_VERSION=1.4.0 scripts/release/promote/wheel_to_s3.sh
```
These scripts can also be used for `torchvision` as well which may make the release process better there as well.
Later on this should be made into a re-usable module that can be downloaded from anywhere and used amongst all pytorch repositories.
Signed-off-by: Eli Uriegas <eliuriegas@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34274
Test Plan: sandcastle_will_deliver
Differential Revision: D20294419
Pulled By: seemethere
fbshipit-source-id: c8c31b5c42af5096f09275166ac43d45a459d25c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34203
Currently cmake and mobile build scripts still build libcaffe2 by
default. To build pytorch mobile users have to set environment variable
BUILD_PYTORCH_MOBILE=1 or set cmake option BUILD_CAFFE2_MOBILE=OFF.
PyTorch mobile has been released for a while. It's about time to change
CMake and build scripts to build libtorch by default.
Changed caffe2 CI job to build libcaffe2 by setting BUILD_CAFFE2_MOBILE=1
environment variable. Only found android CI for libcaffe2 - do we ever
have iOS CI for libcaffe2?
Test Plan: Imported from OSS
Differential Revision: D20267274
Pulled By: ljk53
fbshipit-source-id: 9d997032a599c874d62fbcfc4f5d4fbf8323a12e
Summary:
Among all ONNX tests, ONNXRuntime tests are taking the most time on CI (almost 60%).
This is because we are testing larger models (mainly torchvision RCNNs) for multiple onnx opsets.
I decided to divide tests between two jobs for older/newer opsets. This is now reducing the test time from 2h to around 1h10mins.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33242
Reviewed By: hl475
Differential Revision: D19866498
Pulled By: houseroad
fbshipit-source-id: 446c1fe659e85f5aef30efc5c4549144fcb5778c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34187
Noticed that a recent PR broke Android/iOS CI but didn't break mobile
build with host toolchain. Turns out one mobile related flag was not
set on PYTORCH_BUILD_MOBILE code path:
```
"set(INTERN_DISABLE_MOBILE_INTERP ON)"
```
First, move the INTERN_DISABLE_MOBILE_INTERP macro below, to stay with
other "mobile + pytorch" options - it's not relevant to "mobile + caffe2"
so doesn't need to be set as common "mobile" option;
Second, rename PYTORCH_BUILD_MOBILE env-variable to
BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN - it's a bit verbose but
becomes more clear what it does - there is another env-variable
"BUILD_PYTORCH_MOBILE" used in scripts/build_android.sh, build_ios.sh,
which toggles between "mobile + pytorch" v.s. "mobile + caffe2";
Third, combine BUILD_PYTORCH_MOBILE_WITH_HOST_TOOLCHAIN with ANDROID/IOS
to avoid missing common mobile options again in future.
Test Plan: Imported from OSS
Differential Revision: D20251864
Pulled By: ljk53
fbshipit-source-id: dc90cc87ffd4d0bf8a78ae960c4ce33a8bb9e912
Summary:
**Summary**
This commit adds a script that fetches a platform-appropriate `clang-format` binary
from S3 for use during PyTorch development. The goal is for everyone to use the exact
same `clang-format` binary so that there are no formatting conflicts.
**Testing**
Ran the script.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33644
Differential Revision: D20076598
Pulled By: SplitInfinity
fbshipit-source-id: cd837076fd30e9c7a8280665c0d652a33b559047
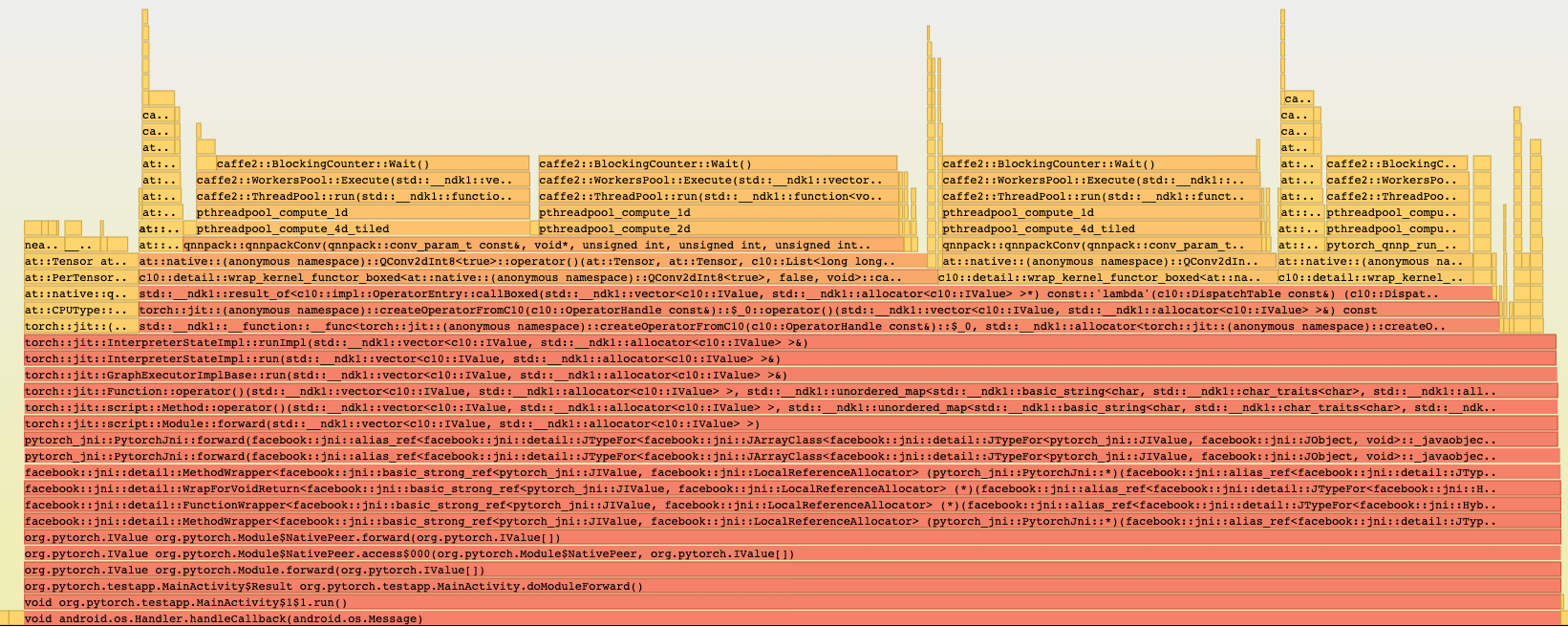
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33722
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding native implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Test Plan:
Build: CI
Functionality: Not exposed
Reviewed By: dreiss
Differential Revision: D20069796
Pulled By: AshkanAliabadi
fbshipit-source-id: d46c1c91d4bea91979ea5bd46971ced5417d309c
Summary:
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding **native** implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Reviewed By: dreiss
Differential Revision: D19521853
Pulled By: AshkanAliabadi
fbshipit-source-id: 99a1fab31d0ece64961df074003bb852c36acaaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33318
### Summary
Recently, we have a [discussion](https://discuss.pytorch.org/t/libtorch-on-watchos/69073/14) in the forum about watchOS. This PR adds the support for building watchOS libraries.
### Test Plan
- `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=WATCHOS ./scripts/build_ios.sh`
Test Plan: Imported from OSS
Differential Revision: D19896534
Pulled By: xta0
fbshipit-source-id: 7b9286475e895d9fefd998246e7090ac92c4c9b6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30315
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
This is a reland of https://github.com/pytorch/pytorch/pull/29731 but
I've extracted all of the prep work into separate PRs which can be
landed before this one.
Some things of note:
* torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
* The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/libprotobuf.a(arena.cc.o) is referenced by DSO"
* A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly
* I had to torch_cpu/torch_cuda caffe2_interface_library so that they get whole-archived linked into torch when you statically link. And I had to do this in an *exported* fashion because torch needs to depend on torch_cpu_library. In the end I exported everything and removed the redefinition in the Caffe2Config.cmake. However, I am not too sure why the old code did it in this way in the first place; however, it doesn't seem to have broken anything to switch it this way.
* There's some uses of `__HIP_PLATFORM_HCC__` still in `torch_cpu` code, so I had to apply it to that library too (UGH). This manifests as a failer when trying to run the CUDA fuser. This doesn't really matter substantively right now because we still in-place HIPify, but it would be good to fix eventually. This was a bit difficult to debug because of an unrelated HIP bug, see https://github.com/ROCm-Developer-Tools/HIP/issues/1706Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18790941
Pulled By: ezyang
fbshipit-source-id: 01296f6089d3de5e8365251b490c51e694f2d6c7
Summary:
Move the shell script into this separate PR to make the original PR
smaller and less scary.
Test Plan:
- With stacked PRs:
1. analyze test project and compare with expected results:
```
ANALYZE_TEST=1 CHECK_RESULT=1 tools/code_analyzer/build.sh
```
2. analyze LibTorch:
```
ANALYZE_TORCH=1 tools/code_analyzer/build.sh
```
Differential Revision: D18474749
Pulled By: ljk53
fbshipit-source-id: 55c5cae3636cf2b1c4928fd2dc615d01f287076a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29731
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
Some subtleties about the patch:
- There were a few functions that crossed CPU-CUDA boundary without API macros. I just added them, easy enough. An inverse situation was aten/src/THC/THCTensorRandom.cu where we weren't supposed to put API macros directly in a cpp file.
- DispatchStub wasn't getting all of its symbols related to static members on DispatchStub exported properly. I tried a few fixes but in the end I just moved everyone off using DispatchStub to dispatch CUDA/HIP (so they just use normal dispatch for those cases.) Additionally, there were some mistakes where people incorrectly were failing to actually import the declaration of the dispatch stub, so added includes for those cases.
- torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
- The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
- In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/l
ibprotobuf.a(arena.cc.o) is referenced by DSO"
- A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly. This situation also happens with custom C++ extensions.
- There's a ROCm compiler bug where extern "C" on functions is not respected. There's a little workaround to handle this.
- Because I was too lazy to check if HIPify was converting TORCH_CUDA_API into TORCH_HIP_API, I just made it so HIP build also triggers the TORCH_CUDA_API macro. Eventually, we should translate and keep the nature of TORCH_CUDA_API constant in all cases.
Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18632773
Pulled By: ezyang
fbshipit-source-id: ea717c81e0d7554ede1dc404108603455a81da82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30144
Create script to produce libtorch that only contains ops needed by specific
models. Developers can use this workflow to further optimize mobile build size.
Need keep a dummy stub for unused (stripped) ops because some JIT side
logic requires certain function schemas to be existed in the JIT op
registry.
Test Steps:
1. Build "dump_operator_names" binary and use it to dump root ops needed
by a specific model:
```
build/bin/dump_operator_names --model=mobilenetv2.pk --output=mobilenetv2.yaml
```
2. The MobileNetV2 model should use the following ops:
```
- aten::t
- aten::dropout
- aten::mean.dim
- aten::add.Tensor
- prim::ListConstruct
- aten::addmm
- aten::_convolution
- aten::batch_norm
- aten::hardtanh_
- aten::mm
```
NOTE that for some reason it outputs "aten::addmm" but actually uses "aten::mm".
You need fix it manually for now.
3. Run custom build script locally (use Android as an example):
```
SELECTED_OP_LIST=mobilenetv2.yaml scripts/build_pytorch_android.sh armeabi-v7a
```
4. Checkout demo app that uses locally built library instead of
downloading from jcenter repo:
```
git clone --single-branch --branch custom_build git@github.com:ljk53/android-demo-app.git
```
5. Copy locally built libraries to demo app folder:
```
find ${HOME}/src/pytorch/android -name '*.aar' -exec cp {} ${HOME}/src/android-demo-app/HelloWorldApp/app/libs/ \;
```
6. Build demo app with locally built libtorch:
```
cd ${HOME}/src/android-demo-app/HelloWorldApp
./gradlew clean && ./gradlew assembleDebug
```
7. Install and run the demo app.
In-APK arm-v7 libpytorch_jni.so build size reduced from 5.5M to 2.9M.
Test Plan: Imported from OSS
Differential Revision: D18612127
Pulled By: ljk53
fbshipit-source-id: fa8d5e1d3259143c7346abd1c862773be8c7e29a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29715
Previous we hard code it to enable static dispatch when building mobile
library. Since we are exploring approaches to deprecate static dispatch
we should make it optional. This PR moved the setting from cmake to bash
build scripts which can be overridden.
Test Plan: - verified it's still using static dispatch when building with these scripts.
Differential Revision: D18474640
Pulled By: ljk53
fbshipit-source-id: 7591acc22009bfba36302e3b2a330b1428d8e3f1
Summary:
Reason:
To have one-step build for test android application based on the current code state that is ready for profiling with simpleperf, systrace etc. to profile performance inside the application.
## Parameters to control debug symbols stripping
Introducing /CMakeLists parameter `ANDROID_DEBUG_SYMBOLS` to be able not to strip symbols for pytorch (not add linker flag `-s`)
which is checked in `scripts/build_android.sh`
On gradle side stripping happens by default, and to prevent it we have to specify
```
android {
packagingOptions {
doNotStrip "**/*.so"
}
}
```
which is now controlled by new gradle property `nativeLibsDoNotStrip `
## Test_App
`android/test_app` - android app with one MainActivity that does inference in cycle
`android/build_test_app.sh` - script to build libtorch with debug symbols for specified android abis and adds `NDK_DEBUG=1` and `-PnativeLibsDoNotStrip=true` to keep all debug symbols for profiling.
Script assembles all debug flavors:
```
└─ $ find . -type f -name *apk
./test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
./test_app/app/build/outputs/apk/resnet/debug/test_app-resnet-debug.apk
```
## Different build configurations
Module for inference can be set in `android/test_app/app/build.gradle` as a BuildConfig parameters:
```
productFlavors {
mobilenetQuant {
dimension "model"
applicationIdSuffix ".mobilenetQuant"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_MOBILENET_QUANT'))
addManifestPlaceholders([APP_NAME: "PyMobileNetQuant"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-mobilenet\"")
}
resnet {
dimension "model"
applicationIdSuffix ".resnet"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_RESNET18'))
addManifestPlaceholders([APP_NAME: "PyResnet"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-resnet\"")
}
```
In that case we can setup several apps on the same device for comparison, to separate packages `applicationIdSuffix`: 'org.pytorch.testapp.mobilenetQuant' and different application names and logcat tags as `manifestPlaceholder` and another BuildConfig parameter:
```
─ $ adb shell pm list packages | grep pytorch
package:org.pytorch.testapp.mobilenetQuant
package:org.pytorch.testapp.resnet
```
In future we can add another BuildConfig params e.g. single/multi threads and other configuration for profiling.
At the moment 2 flavors - for resnet18 and for mobilenetQuantized
which can be installed on connected device:
```
cd android
```
```
gradle test_app:installMobilenetQuantDebug
```
```
gradle test_app:installResnetDebug
```
## Testing:
```
cd android
sh build_test_app.sh
adb install -r test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
```
```
cd $ANDROID_NDK
python simpleperf/run_simpleperf_on_device.py record --app org.pytorch.testapp.mobilenetQuant -g --duration 10 -o /data/local/tmp/perf.data
adb pull /data/local/tmp/perf.data
python simpleperf/report_html.py
```
Simpleperf report has all symbols:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28406
Differential Revision: D18386622
Pulled By: IvanKobzarev
fbshipit-source-id: 3a751192bbc4bc3c6d7f126b0b55086b4d586e7a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28405
### Summary
As discussed with AshkanAliabadi and ljk53, the iOS TestApp will share the same benchmark code with Android's speed_benchmark_torch.cpp. This PR is the first part which contains the Objective-C++ code.
The second PR will include the scripts to setup and run the benchmark project. The third PR will include scripts that can automate the whole "build - test - install" process.
There are many ways to run the benchmark project. The easiest way is to use cocoapods. Simply run `pod install`. However, that will pull the 1.3 binary which is not what we want, but we can still use this approach to test the benchmark code. The second PR will contain scripts to run custom builds that we can tweak.
### Test Plan
- Don't break any existing CI jobs (except for those flaky ones)
Test Plan: Imported from OSS
Differential Revision: D18064187
Pulled By: xta0
fbshipit-source-id: 4cfbb83c045803d8b24bf6d2c110a55871d22962
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27593
## Summary
Since the nightly jobs are lack of testing phases, we don't really have a way to test the binary before uploading it to AWS. To make the work more solid, we need to figure out a way to verify the binary.
Fortunately, the XCode tool chain offers a way to build your app without XCode app, which is the [xcodebuild](https://developer.apple.com/library/archive/technotes/tn2339/_index.html) command. Now we can link our binary to a testing app and run `xcodebuild` to to see if there is any linking error. The PRs below have already done some of the preparation jobs
- [#26261](https://github.com/pytorch/pytorch/pull/26261)
- [#26632](https://github.com/pytorch/pytorch/pull/26632)
The challenge comes when testing the arm64 build as we don't have a way to code-sign our TestApp. Circle CI has a [tutorial](https://circleci.com/docs/2.0/ios-codesigning/) but is too complicated to implement. Anyway, I figured out an easier way to do it
1. Disable automatically code sign in XCode
2. Export the encoded developer certificate and provisioning profile to org-context in Circle CI (done)
3. Install the developer certificate to the key chain store on CI machines via Fastlane.
4. Add the testing code to PR jobs and verify the result.
5. Add the testing code to nightly jobs and verify the result.
## Test Plan
- Both PR jobs and nightly jobs can finish successfully.
- `xcodebuild` can finish successfully
Test Plan: Imported from OSS
Differential Revision: D17848814
Pulled By: xta0
fbshipit-source-id: 48353f001c38e61eed13a43943253cae30d8831a
Summary:
1. scripts/build_android_libtorch_and_pytorch_android.sh
- Builds libtorch for android_abis (by default for all 4: x86, x86_64, armeabi-v7a, arm-v8a) but cab be specified only custom list as a first parameter e.g. "x86"
- Creates symbolic links inside android/pytorch_android to results of the previous builds:
`pytorch_android/src/main/jniLibs/${abi}` -> `build_android/install/lib`
`pytorch_android/src/main/cpp/libtorch_include/${abi}` -> `build_android/install/include`
- Runs gradle assembleRelease to build aar files
proxy can be specified inside (for devservers)
2. android/run_tests.sh
Running pytorch_android tests, contains instruction how to setup and run android emulator in headless and noaudio mode to run it on devserver
proxy can be specified inside (for devservers)
#Test plan
Scenario to build x86 libtorch and android aars with it and run tests:
```
cd pytorch
sh scripts/build_android_libtorch_and_pytorch_android.sh x86
sh android/run_tests.sh
```
Tested on my devserver - build works, tests passed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26833
Differential Revision: D17673972
Pulled By: IvanKobzarev
fbshipit-source-id: 8cb7c3d131781854589de6428a7557c1ba7471e9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26632
### Summary
This script builds the TestApp (located in ios folder) to generate an iOS x86 executable via the `xcodebuild` toolchain on macOS. The goal is to provide a quick way to test the generated static libraries to see if there are any linking errors. The script can also be used by the iOS CI jobs. To run the script, simply see description below:
```shell
$ruby scripts/xcode_ios_x86_build.rb --help
-i, --install path to the cmake install folder
-x, --xcodeproj path to the XCode project file
```
### Note
The script mainly deals with the iOS simulator build. For the arm64 build, I haven't found a way to disable the Code Sign using the `xcodebuiild` tool chain (XCode 10). If anyone knows how to do that, please feel free to leave a comment below.
### Test Plan
- The script can build the TestApp and link the generated static libraries successfully
- Don't break any CI job
Test Plan: Imported from OSS
Differential Revision: D17530990
Pulled By: xta0
fbshipit-source-id: f50bef7127ff8c11e884c99889cecff82617212b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26478
### Summary
Since QNNPACK [doesn't support bitcode](7d2a4e9931/scripts/build-ios-arm64.sh (L40)), I'm going to disable it in our CMake scripts. This won't hurt any existing functionalities, and will only affect the build size. Any application that wants to integrate our framework should turn off bitcode as well.
### Test plan
- CI job works
- LibTorch.a can be compiled and run on iOS devices
Test Plan: Imported from OSS
Differential Revision: D17489020
Pulled By: xta0
fbshipit-source-id: 950619b9317036cad0505d8a531fb8f5331dc81f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26440
As we are optimizing build size for Android/iOS, it starts diverging
from default build on several build options, e.g.:
- USE_STATIC_DISPATCH=ON;
- disable autograd;
- disable protobuf;
- no caffe2 ops;
- no torch/csrc/api;
...
Create this build_mobile.sh script to 'simulate' mobile build mode
with host toolchain so that people who don't work on mobile regularly
can debug Android/iOS CI error more easily. It might also be used to
build libtorch on devices like raspberry pi natively.
Test Plan:
- run scripts/build_mobile.sh -DBUILD_BINARY=ON
- run build_mobile/bin/speed_benchmark_torch on host machine
Differential Revision: D17466580
Pulled By: ljk53
fbshipit-source-id: 7abb6b50335af5b71e58fb6d6f9c38eb74bd5781
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26113
After https://github.com/pytorch/pytorch/pull/16914, passing in an
argument such as "build_deps" (i.e. python setup.py build_deps develop) is
invalid since it gets picked up as an invalid argument.
ghstack-source-id: 90003508
Test Plan:
Before, this script would execute "python setup.py build_deps
develop", which errored. Now it executes "python setup.py develop" without an
error. Verified by successfully running the script on devgpu. In setup.py,
there is already a `RUN_BUILD_DEPS = True` flag.
Differential Revision: D17350359
fbshipit-source-id: 91278c3e9d9f7c7ed8dea62380f18ba5887ab081
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25896
Similar change as PR #25822.
Test Plan:
- Updated CI to use the new script.
- Will check pytorch android CI output to make sure it builds libtorch
instead of libcaffe2.
Reviewed By: dreiss
Differential Revision: D17279722
Pulled By: ljk53
fbshipit-source-id: 93abcef0dfb93df197fabff29e53d71db5674255
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/25822
### Summary
Since protobuf has been removed from mobile, the `build_host_protoc.sh` can be removed from `build_ios.sh` as well. However, the old caffe2 mobile build still depend on it, therefore, I introduced this `BUILD_PYTORCH_MOBILE` flag to gate the build.
- iOS device build
```
BUILD_PYTORCH_MOBILE=1 IOS_ARCH=arm64 ./scripts/build_ios.sh
BUILD_PYTORCH_MOBILE=1 IOS_ARCH=armv7s ./scripts/build_ios.sh
```
- iOS simulator build
```
BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=SIMULATOR ./scripts/build_ios.sh
```
### Test Plan
All device and simulator builds run successfully
Test Plan: Imported from OSS
Differential Revision: D17264469
Pulled By: xta0
fbshipit-source-id: f8994bbefec31b74044eaf01214ae6df797816c3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24331
Currently our logs are something like 40M a pop. Turning off warnings and turning on verbose makefiles (to see the compile commands) reduces this to more like 8M. We could probably reduce log size more but verbose makefile is really useful and we'll keep it turned on for Windows.
Some findings:
1. Setting `CMAKE_VERBOSE_MAKEFILE` inside CMakelists.txt itself as suggested in https://github.com/ninja-build/ninja/issues/900#issuecomment-417917630 does not work on Windows. Setting `-DCMAKE_VERBOSE_MAKEFILE=1` does work (and we respect this environment variable.)
2. The high (`/W3`) warning level is by default on MSVC is due to cmake inserting this in the default flags. On recent versions of cmake, CMP0092 can be used to disable this flag in the default set. The string replace trick sort of works, but the standard snippet you'll find on the internet won't disable the flag from nvcc. I inspected the CUDA cmake code and verified it does respect CMP0092
3. `EHsc` is also in the default flags; this one cannot be suppressed via a policy. The string replace trick seems to work...
4. ... however, it seems nvcc implicitly inserts an `/EHs` after `-Xcompiler` specified flags, which means that if we add `/EHa` to our set of flags, you'll get a warning from nvcc. So we probably have to figure out how to exclude EHa from the nvcc flags set (EHs does seem to work fine.)
5. To suppress warnings in nvcc, you must BOTH pass `-w` and `-Xcompiler /w`. Individually these are not enough.
The patch applies these things; it also fixes a bug where nvcc verbose command printing doesn't work with `-GNinja`.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D17131746
Pulled By: ezyang
fbshipit-source-id: fb142f8677072a5430664b28155373088f074c4b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24330
In principle, we should be able to use the MSVC generator
to do a Windows build, but with the latest build of our
Windows AMI, this is no longer possible. An in-depth
investigation about why this is no longer working should
occur in https://github.com/pytorch/pytorch/issues/24386
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24330
Test Plan: Imported from OSS
Differential Revision: D16828794
Pulled By: ezyang
fbshipit-source-id: fa826a8a6692d3b8d5252fce52fe823eb58169bf
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24030
The cmake arg - `USE_QNNPACK` was disabled for iOS build due to its lack of support for building multiple archs(armv7;armv7s;arm64) simultaneously.To enable it, we need to specify the value of IOS_ARCH explicitly in the build command:
```
./scripts/build_ios.sh \
-DIOS_ARCH=arm64 \
-DBUILD_CAFFE2_MOBILE=OFF \
```
However,the iOS.cmake will overwirte this value according to the value of `IOS_PLATFORM`. This PR is a fix to this problem.
Test Plan:
- `USE_QNNPACK` should be turned on by cmake.
- `libqnnpack.a` can be generated successfully.
- `libortch.a` can be compiled and run successfully on iOS devices.
<img src="https://github.com/xta0/AICamera-ObjC/blob/master/aicamera.gif?raw=true" width="400">
Differential Revision: D16771014
Pulled By: xta0
fbshipit-source-id: 4cdfd502cb2bcd29611e4c22e2efdcdfe9c920d3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/24029
The cmake toolchain file for building iOS is currently in `/third-pary/ios-cmake`. Since the upstream is not active anymore, It's better to maintain this file ourselves moving forward.This PR is also the prerequisite for enabling QNNPACK for iOS.
Test Plan:
- The `libtorch.a` can be generated successfully
- The `libtorch.a` can be compiled and run on iOS devices
<img src="https://github.com/xta0/AICamera-ObjC/blob/master/aicamera.gif?raw=true" width="400">
Differential Revision: D16770980
Pulled By: xta0
fbshipit-source-id: 1ed7b12b3699bac52b74183fa7583180bb17567e
Summary:
ONNX uses virtualenv, and PyTorch doesn't. So --user flag is causing problems in ONNX ci...
Fixing it by moving it to pytorch only scripts. And will install ninja in onnx ci separately.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22946
Reviewed By: bddppq
Differential Revision: D16297781
Pulled By: houseroad
fbshipit-source-id: 52991abac61beaf3cfbcc99af5bb1cd27b790485
Summary:
This is an extension to the original PR https://github.com/pytorch/pytorch/pull/21765
1. Increase the coverage of different opsets support, comments, and blacklisting.
2. Adding backend tests for both caffe2 and onnxruntime on opset 7 and opset 8.
3. Reusing onnx model tests in caffe2 for onnxruntime.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22421
Reviewed By: zrphercule
Differential Revision: D16225518
Pulled By: houseroad
fbshipit-source-id: 01ae3eed85111a83a0124e9e95512b80109d6aee
Summary:
- Fix typo in ```torch/onnx/utils.py``` when looking up registered custom ops.
- Add a simple test case
1. Register custom op with ```TorchScript``` using ```cpp_extension.load_inline```.
2. Register custom op with ```torch.onnx.symbolic``` using ```register_custom_op_symbolic```.
3. Export model with custom op, and verify with Caffe2 backend.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21321
Differential Revision: D16101097
Pulled By: houseroad
fbshipit-source-id: 084f8b55e230e1cb6e9bd7bd52d7946cefda8e33
Summary:
So far, we only have py2 ci for onnx. I think py3 support is important. And we have the plan to add onnxruntime backend tests, which only supports py3.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21715
Reviewed By: bddppq
Differential Revision: D15796885
Pulled By: houseroad
fbshipit-source-id: 8554dbb75d13c57b67ca054446a13a016983326c
Summary:
Fixes#21026.
1. Improve build docs for Windows
2. Change `BUILD_SHARED_LIBS=ON` for Caffe2 local builds
3. Change to out-source builds for LibTorch and Caffe2 (transferred to #21452)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21190
Differential Revision: D15695223
Pulled By: ezyang
fbshipit-source-id: 0ad69d7553a40fe627582c8e0dcf655f6f63bfdf
Summary:
This PR is an intermediate step toward the ultimate goal of eliminating "caffe2" in favor of "torch". This PR moves all of the files that had constituted "libtorch.so" into the "libcaffe2.so" library, and wraps "libcaffe2.so" with a shell library named "libtorch.so". This means that, for now, `caffe2/CMakeLists.txt` becomes a lot bigger, and `torch/CMakeLists.txt` becomes smaller.
The torch Python bindings (`torch_python.so`) still remain in `torch/CMakeLists.txt`.
The follow-up to this PR will rename references to `caffe2` to `torch`, and flatten the shell into one library.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17783
Differential Revision: D15284178
Pulled By: kostmo
fbshipit-source-id: a08387d735ae20652527ced4e69fd75b8ff88b05
Summary:
We now can build libtorch for Android.
This patch aims to provide two improvements to the build
- Make the architecture overridable by providing an environment variable `ANDROID_ABI`.
- Use `--target install` when calling cmake to actually get the header files nicely in one place.
I ran the script without options to see if the caffe2 builds are affected (in particularly by the install), but they seem to run OK and probably only produce a few files in build_android/install.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20152
Differential Revision: D15249020
Pulled By: pjh5
fbshipit-source-id: bc89f1dcadce36f63dc93f9249cba90a7fc9e93d
Summary:
* adds TORCH_API and AT_CUDA_API in places
* refactor code generation Python logic to separate
caffe2/torch outputs
* fix hip and asan
* remove profiler_cuda from hip
* fix gcc warnings for enums
* Fix PythonOp::Kind
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19554
Differential Revision: D15082727
Pulled By: kostmo
fbshipit-source-id: 83a8a99717f025ab44b29608848928d76b3147a4
Summary:
New pip package becomes more restricted. We need to add extra flag to make the installation work.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19725
Differential Revision: D15078698
Pulled By: houseroad
fbshipit-source-id: bbd782a0c913b5a1db3e9333de1ca7d88dc312f1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19218
Sync some contents between fbcode/caffe2 and xplat/caffe2 to move closer towards a world where they are identical.
Reviewed By: dzhulgakov
Differential Revision: D14919916
fbshipit-source-id: 29c6b6d89ac556d58ae3cd02619aca88c79591c1
{kind=link}
{kind=link}