### Description
Adds the below C APIs to support custom ops that wrap an entire model to
be inferenced with an external runtime. The current SNPE EP is an
example of an EP that could be ported to use a custom op wrapper. Ex:
The custom op stores the serialized SNPE DLC binary as a string
attribute. The SNPE model is built when the kernel is created. The model
is inferenced with SNPE APIs on call to the kernel's compute method.
#### C APIs
| API | Description | Why |
| --- | --- | --- |
| `KernelInfo_GetInputCount` | Gets number of inputs from
`OrtKernelInfo`. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfo_GetOutputCount` | Gets number of outputs from
`OrtKernelInfo`. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfo_GetInputName` | Gets an input's name. | Query I/O
characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetOutputName` | Gets an output's name. | Query I/O
characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetInputTypeInfo` | Gets the type/shape information for an
input. | Query I/O characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetOutputTypeInfo` | Gets the type/shape information for
an output. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfoGetAttribute_tensor` | Get a OrtValue tensor stored as an
attribute in the graph node | Extract serialized models, weights, etc. |
| `GetSessionConfigEntry` | Get a session configuration value | Need to
be able to get session-time configurations from within custom op |
| `HasSessionConfigEntry` | Check if session configuration entry exists.
| Need to be able to get session-time configurations from within custom
op |
#### Why so many KernelInfo APIs?<sup>1</sup>
Similar APIs currently exist for `OrtKernelContext`, but not
`OrtKernelInfo`. Note that `OrtKernelContext` is passed to the custom op
on call to its kernel's compute() function. However, `OrtKernelInfo` is
available on kernel creation, which occurs when the session is created.
Having these APIs available from `OrtKernelInfo` allows an operator to
trade-off computation time for session-creation time, and vice versa.
Operators that must build expensive state may prefer to do it during
session creation time instead of compute-time.
SNPE is an example of an EP that needs to be able to query `KernelInfo`
for the name, type, and shape of inputs and outputs in order to build
the model from the serialized DLC data. This is an expensive operation.
Other providers (e.g., OpenVINO) are able to query i/o info from the
serialized model, so they do not strictly need these APIs. However, the
APIs can still be used to validate the expected I/O characteristics.
Additionally, several of our CPU contrib ops currently use the same
internal version of these KernelInfo APIs (Ex:
[qlinear_softmax](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/contrib_ops/cpu/quantization/qlinear_softmax.cc#L71)).
If custom ops are also meant to be a test bed for future ops, then all
custom ops (not just runtime wrappers) would benefit from the addition
of these public KernelInfo APIs (IMO).
#### Example of usage in a custom OP
From
`onnxruntime/test/testdata/custom_op_openvino_wrapper_library/openvino_wrapper.h`
```c++
struct CustomOpOpenVINO : Ort::CustomOpBase<CustomOpOpenVINO, KernelOpenVINO> {
explicit CustomOpOpenVINO(Ort::ConstSessionOptions session_options);
CustomOpOpenVINO(const CustomOpOpenVINO&) = delete;
CustomOpOpenVINO& operator=(const CustomOpOpenVINO&) = delete;
void* CreateKernel(const OrtApi& api, const OrtKernelInfo* info) const;
constexpr const char* GetName() const noexcept {
return "OpenVINO_Wrapper";
}
constexpr const char* GetExecutionProviderType() const noexcept {
return "CPUExecutionProvider";
}
// IMPORTANT: In order to wrap a generic runtime-specific model, the custom operator
// must have a non-homogeneous variadic input and output.
constexpr size_t GetInputTypeCount() const noexcept {
return 1;
}
constexpr size_t GetOutputTypeCount() const noexcept {
return 1;
}
constexpr ONNXTensorElementDataType GetInputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr ONNXTensorElementDataType GetOutputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr OrtCustomOpInputOutputCharacteristic GetInputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr OrtCustomOpInputOutputCharacteristic GetOutputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr bool GetVariadicInputHomogeneity() const noexcept {
return false; // heterogenous
}
constexpr bool GetVariadicOutputHomogeneity() const noexcept {
return false; // heterogeneous
}
std::vector<std::string> GetSessionConfigKeys() const { return {"device_type"}; }
private:
std::unordered_map<std::string, std::string> session_configs_;
};
```
#### How to create a session:
```c++
Ort::Env env;
Ort::SessionOptions session_opts;
Ort::CustomOpConfigs custom_op_configs;
// Create local session config entries for the custom op.
custom_op_configs.AddConfig("OpenVINO_Wrapper", "device_type", "CPU");
// Register custom op library and pass in the custom op configs (optional).
session_opts.RegisterCustomOpsLibrary(lib_name, custom_op_configs);
Ort::Session session(env, model_path.data(), session_opts);
```
### Motivation and Context
Allows creation of simple "wrapper" EPs outside of the main ORT code
base.
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
https://github.com/microsoft/onnxruntime/issues/12843
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
### Description
<!-- Describe your changes. -->
Bug fixed: Quantized models cannot be loaded into ort.InferenceSession
when DedicatedQDQPair is True in extra_options of QDQQuantizer.
Solutions: Add postfix to node names of dedicated QDQ pairs similar to
tensor names of them.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Loading quantized model fails when setting `DedicatedQDQPair` to `True`
in `extra_options` and raise an error as below:
```
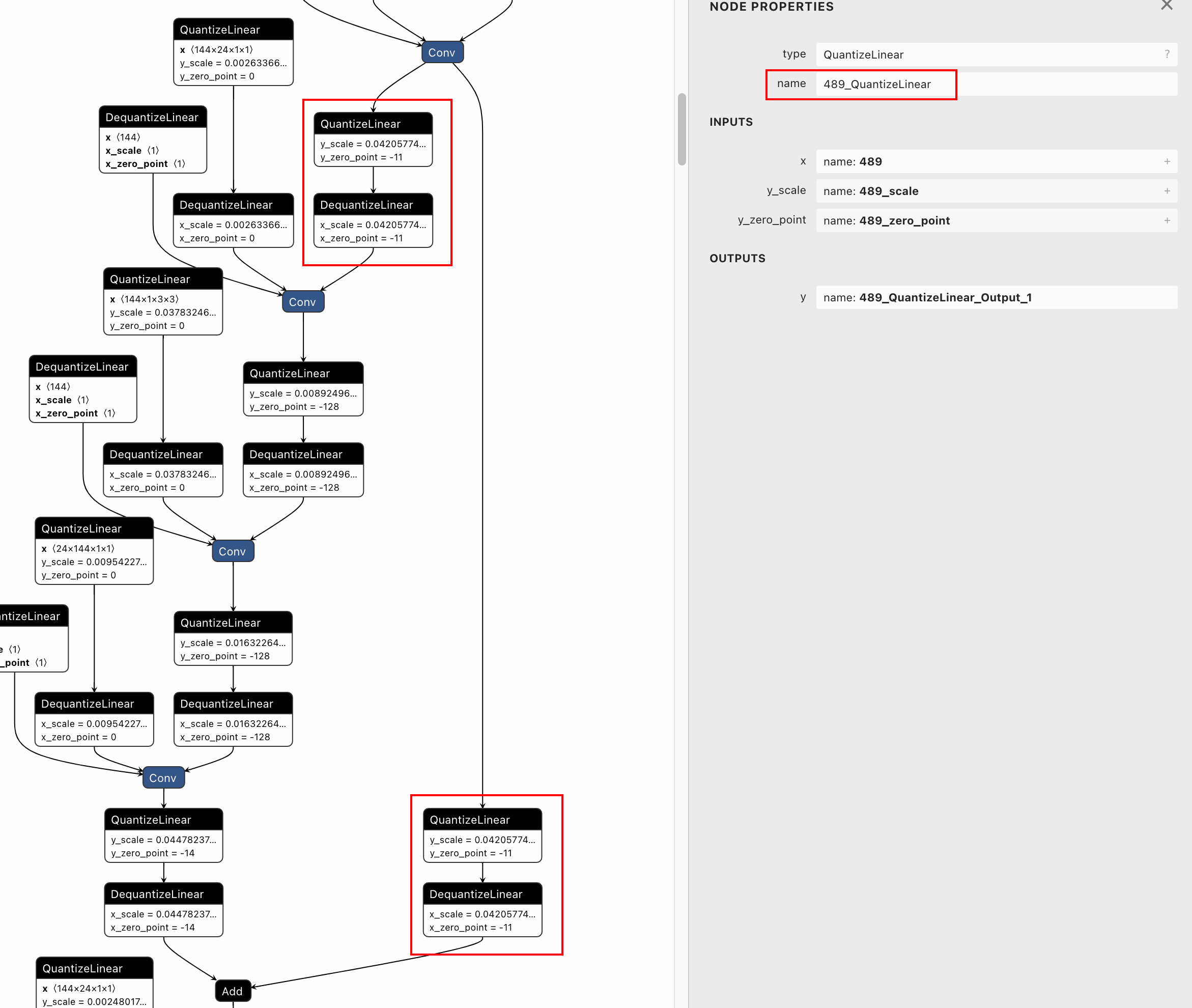
Fail: [ONNXRuntimeError] : 1 : FAIL : Load model from mobilenetv2-opset10-quantized-dedicated.onnx failed:This is an invalid model. Error: two nodes with same node name (489_QuantizeLinear).
```
After visualizing the quantized model using netron, we can find that
both the dedicated QDQ pairs for tensor 489 have the same node names of
"489_QuantizeLinear". So I found that in QDQQuantizer, there is no
unique postfix for the node names of dedicated QDQ pairs.
<img width="1171" alt="image"
src="https://user-images.githubusercontent.com/12782861/212010296-f8cc05ce-c20e-4189-a692-aaf4bbac3a29.png">
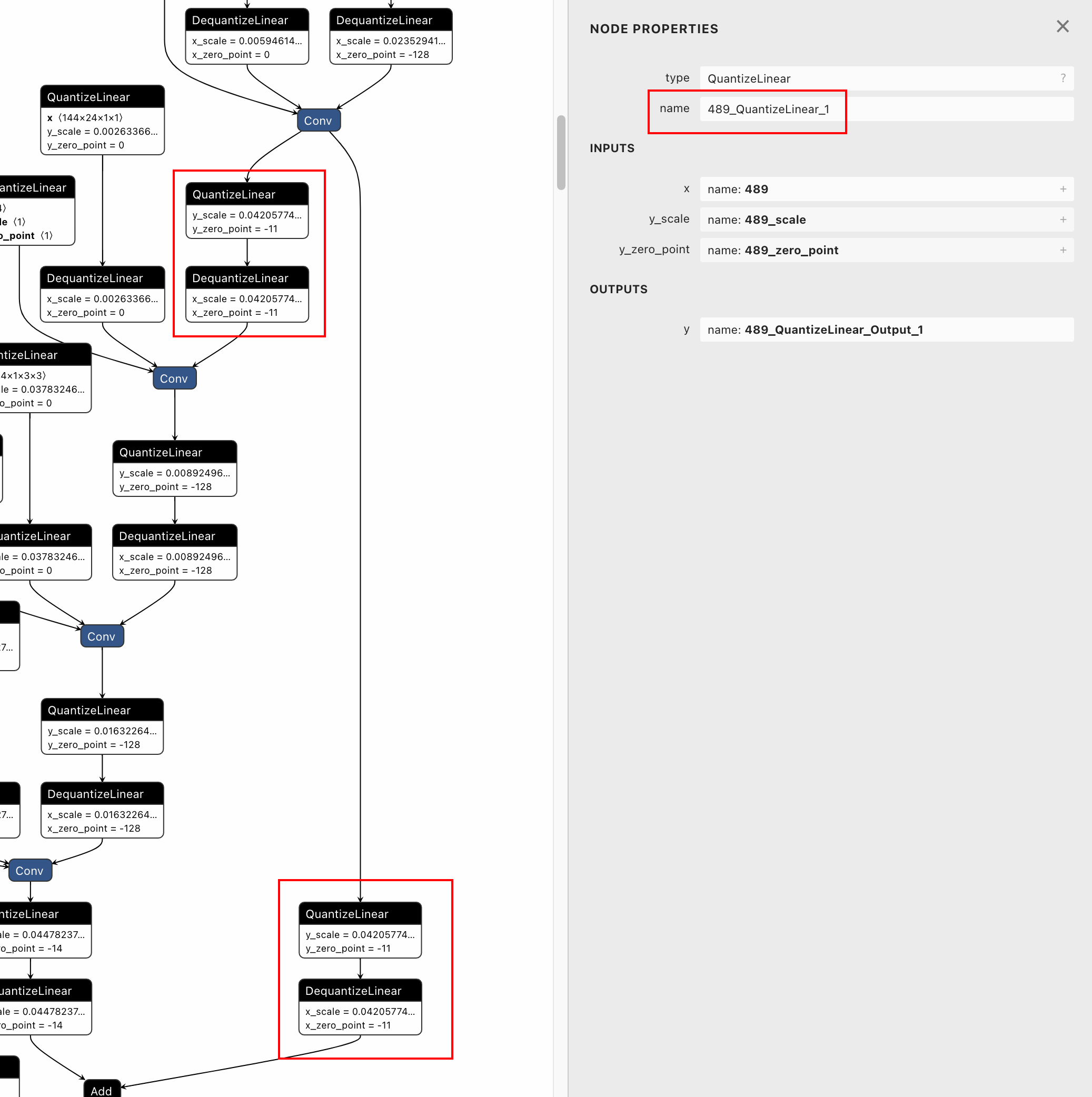
Therefore, I add postfix to node names of QDQ pairs similar to doing so
to tensor names. After this modification, the quantized model can be
loaded successfully and dedicated QDQ pairs have different node names.👌🏻
<img width="1037" alt="image"
src="https://user-images.githubusercontent.com/12782861/212010594-78eba39d-eab6-4d77-9ecd-b55f5303bcf4.png">
### Description
<!-- Describe your changes. -->
1. add an optional input to pass in seed
2. two UTs. one for top_p=0.5, another for top_p=0.01(create greedy
search result, in convert_generation.py)
3. fix a bug in cpu kernel
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
Add an option --use_multi_head_attention to fuse model with
MultiHeadAttention operator instead of Attention operator for testing
purpose.
Note that MultiHeadAttention can be used in self-attention and
cross-attention, while Attention operator is used for self-attention
only. In Attention operator, there is packed Q/K/V weights for input
projection, but that MatMul of input projection is excluded from
MultiHeadAttention.
Fix https://github.com/microsoft/onnxruntime/issues/14017.
Before: shape_value = np.asarray([0, 0, np.array([4]), np.array([8])],
dtype=np.int64) raise Error in numpy 1.24.
After: shape_value = np.asarray([0, 0, 4, 8)], dtype=np.int64) is good
in numpy 1.24.
Update test environment to use numpy 1.24.
### Description
<!-- Describe your changes. -->
rename the CrossAttention to MultiheadAttention since this op can also
be used as self attention
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
Move separated Q, K and V (without input projection) from Attention to a
new operator CrossAttention.
The Attention operator is hard to maintain when we need support with and
without input projection in one class. Add a new operator according to
feedback.
Some change might need in the future, but not in this PR:
(1) bias could be optional (We will not proceed that route unless
experiments show that fusing Add bias with MatMul instead of this op
could improve performance).
(2) support packed KV. There are two ways to support it: when key and
value are same Tensor, they are packed; or we can make value as
optional, and use packed mode when value is empty and the key has packed
K/V.
(3) support cached key and value, and other (like relative position
bias), or more attention mask format. They can be added easily without
breaking backward compatible.
(4) ROCm/CPU implementation of this op.
### Description
1. The graph pattern search introduced in
https://github.com/microsoft/onnxruntime/pull/13914/ needs to be
enhanced so that SkipLayerNormalization is supported
2. Fix fp32 parity for GPT-2 while using `SkipLayerNormalization`
fusion. The optional output of SLN needs to also include the bias (if
present) and the added output should be a sum of `input + skip + (bias)`
### Motivation and Context
Fix some breaking tests
### Description
<!-- Describe your changes. -->
Add GemmFastGelu CK implementation.
TODO
1. The performance of CK GemmFastGelu in ORT is not good as using CK
directly, still need to investigate the reason and improve the CK in
ORT.
`GemmFastGeluUnfused float16 NN m=49152 n=3072 k=768 2298.8064 us 100.89
tflops`
`withbias DeviceGemmMultipleD_Xdl_CShuffle<256, 256, 128, 32, 8, 8,
Default> LoopScheduler: Default, PipelineVersion: v1 float16 NN m=49152
n=3072 k=768 2401.9799 us 96.56 tflops`
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
- Adds a new C API `OrtApi::RegisterCustomOpsLibrary_V2` that manages
the lifetime of dynamic library handles (i.e., calls `dlclose` or
`FreeLibrary`).
- Deprecates C API `OrtApi::RegisterCustomOpsLibrary`.
- Adds C++ API wrapper for convenient registering of custom op
libraries.
- `PySessionOptions` is now an alias of `OrtSessionOptions`
### Motivation and Context
The current API for registering custom op libraries loads dynamic
libraries but requires users to handle the release of the corresponding
library handles. Additionally, the user has to make sure to release the
library handle _after_ the session has been destroyed (or the program
segfaults).
The new API automatically cleans up the library and allows the user to
write more straightforward code.
### Description
T5 uses a layer_norm which only scales and doesn't shift, which is also
known as Root Mean Square Layer Normalization.
ORT already have the simplified_layer_norm which is the RMS layer_norm.
This PR extends this T5 layer_norm with support of skip/bias and the
residual output.
This new op is named SkipSimplifiedLayerNorm and has similar interface
as SkipLayerNorm but removes the beta as input
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
### Description
<!-- Describe your changes. -->
when custom decoder onnx model passes in, user can specify eos/pad token
id instead of populating from torch config.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
1. SkipLayerNormalization has a new output
(https://github.com/microsoft/onnxruntime/pull/13988) and the symbolic
shape inference script needs corresponding updates
2. The greedy sampling op
(https://github.com/microsoft/onnxruntime/pull/13426) shouldn't re-use
the logits buffer as its corresponding kernel doesn't seem to support it
yet.
### Motivation and Context
Fix some transformer issues
Implement CloudEP for hybrid inferencing.
The PR introduces zero new API, customers could configure session and
run options to do inferencing with Azure [triton
endpoint.](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-deploy-with-triton?tabs=azure-cli%2Cendpoint)
Sample configuration in python be like:
```
sess_opt.add_session_config_entry('cloud.endpoint_type', 'triton');
sess_opt.add_session_config_entry('cloud.uri', 'https://cloud.com');
sess_opt.add_session_config_entry('cloud.model_name', 'detection2');
sess_opt.add_session_config_entry('cloud.model_version', '7'); // optional, default 1
sess_opt.add_session_config_entry('cloud.verbose', '1'); // optional, default '0', meaning no verbose
...
run_opt.add_run_config_entry('use_cloud', '1') # 0 for local inferencing, 1 for cloud endpoint.
run_opt.add_run_config_entry('cloud.auth_key', '...')
...
sess.run(None, {'input':input_}, run_opt)
```
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
Deprecate one step beam search since it lacks maintenance (some tests
failed) and its performance is not optimal.
For users who still need this feature, please use older version
(<=1.13.1) of onnxruntime to export one step beam search model, and the
model can run in latest onnxruntime.
It is recommend to use
[convert_generation.py](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/python/tools/transformers/convert_generation.py)
to generate beam search onnx model for better performance.
### Description
<!-- Describe your changes. -->
Sampling op for cpu and cuda
support huggingface case and custom case
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: Ubuntu <wy@v100-2.0cdb2e52twzevn1i4fi45bylyg.jx.internal.cloudapp.net>
`numpy.bool` has been removed as from 1.24.0.
It was before an alias for python's `bool`.
Fixes https://github.com/huggingface/optimum/issues/610
### Motivation and Context
Numpy 1.24.0 breaks for example IO binding helpers.
### Description
Add support of ONNX conversion of GPT-2 for two stages:
* Stage 1 is the initial stage that has empty past state.
* Stage 2 has non-empty past state and sequence_length is 1.
Add a parameter --stage to specify such stage. For stage 1, we will
enable mask_index for Attention so that we can use fused attention in
CUDA.
Other changes:
(1) use int32 inputs as default (otherwise, there is error in inference)
(2) update gpt2_parity to include SkipLayerNormalization (see
https://github.com/microsoft/onnxruntime/pull/13988) and
EmbedLayerNormalization
(3) get all environment variables that might impact GPT-2 latency in
benchmark_gpt2
### Motivation and Context
To test fused attention for GPT-2 model for
https://github.com/microsoft/onnxruntime/pull/13953.
Allows the user to select from supported backends for gpt2/convert_to_onnx.py. Default behavior is preserved if no provider is selected. This allows the ROCm EP to be selected.
Implement reuse kv_cache past and present tensor in Attention Ops.
Unit test for abover feature.
Utilize the reuse kv_cache for past and present tensor in Greedy Search.
Correctness test for it.
Co-authored-by: Zhang Lei <phill.zhang@gmail.com>
**Description**: This PR including following works:
1. provide stream and related synchronization abstractions in
onnxruntime.
2. enhance onnxruntime's execution planner / executor / memory arena to
support execute multiple streams in parallel.
3. deprecate the parallel executor for cpu.
4. deprecate the Fence mechanism.
5. update the cuda / tensorrt EP to support the stream mechanism,
support running different request in different cuda stream.
**Motivation and Context**
- Why is this change required?
currently, the execution plan is just a linear list of those primitives,
ort will execute them step by step. For any given graph, ORT will
serialize it to a fixed execution order. This sequential execution
design simplifies most scenarios, but it has the following limitations:
1. it is difficult to enable inter-node parallelization, we have a
half-baked parallel executor but it is very difficult to make it work
with GPU.
2. The fence mechanism can work with single gpu stream + cpu thread
case, but when extend to multiple stream, it is difficult to manage the
cross GPU stream synchronizations.
3. our cuda EP rely on the BFCArena to make the memory management work
with the GPU async kernels, but current BFCArena is not aware of the
streams, so it doesn't behavior correctly when run with multiple
streams.
This PR enhance our existing execution plan and executor to support
multiple stream execution. we use an unified algorithm to mange both
single stream and multiple stream scenarios.
This PR mainly focus on the infrastructure support for multiple stream
execution, that is said, given a valid stream assignment, onnxruntime
can execute it correctly. How to generate a good stream assignment for a
given model will be in the future PR.
Co-authored-by: Cheng Tang <chenta@microsoft.com@orttrainingdev9.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Cheng Tang <chenta@microsoft.com>
Co-authored-by: RandySheriffH <48490400+RandySheriffH@users.noreply.github.com>
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
Co-authored-by: cao lei <jslhcl@gmail.com>
Co-authored-by: Lei Cao <leca@microsoft.com>
### Description
Allow Tensor to be scalar if it is not per channel.
### Motivation and Context
[<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
-->](https://github.com/microsoft/onnxruntime/issues/13915)
### Description
<!-- Describe your changes. -->
Sort kernel explorer profile result, the instance is sorted according to
the performance.
1. Set sort kernel as an optional config when we pass parameters through
commandline.
`python gemm_test.py N N float16 M N K` disable sort by default, add
`--sort` to enable sort.
2. 'python gemm_test.py' enable sort by default.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
To pass session_options to Xnnpack EP via
`XnnpackProviderFactoryCreator` for Initializing xnnpack's threadpool.
If you want to use different threadpool size or even disable xnnpack's
threadpool, just setting intra_threadpool to 1 by xnnpack EP's
provider_options.
### Motivation and Context
Co-authored-by: Guangyun Han <guangyunhan@microsoft.com>
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
### Description
- Adds a dockerfile for Ubuntu with TensorRT 8.5.1.1.
- Adds option to run EP Perf pipeline with TensorRT 8.5
### Motivation and Context
Necessary to benchmark models with TensorRT 8.5
### Description
Add cuda support to the on device training python bindings.
### Motivation and Context
Now users can set the execution provider (cpu or cuda) when using python
bindings for on device training apis.
### Description
<!-- Describe your changes. -->
1. Update FastGelu conditions for supported parameters, avoid redundant
configurations participating in tuning。
2. Add kernel explorer test for FastGeluStaticSelection
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Co-authored-by: peixuanzuo <peixuanzuo@linmif39a000004.zvflicr54joexhdgnhvmxrxygg.phxx.internal.cloudapp.net>
### Description
Add DML support to the transformers benchmark.py script
### Motivation and Context
Before this change, running the `benchmark.py` script when the
`onnxruntime-directml` package is installed resulted in an error because
it expects a CUDA or ROCM framework.
{kind=link}
{kind=link}