# Motivation
Currently, ORT minimal builds use kernel def hashes to map from nodes to
kernels to execute when loading the model. As the kernel def hashes must
be known ahead of time, this works for statically registered kernels.
This works well for the CPU EP.
For this approach to work, the kernel def hashes must also be known at
ORT format model conversion time, which means the EP with statically
registered kernels must also be enabled then. This is not an issue for
the always-available CPU EP. However, we do not want to require that any
EP which statically registers kernels is always available too.
Consequently, we explore another approach to match nodes to kernels that
does not rely on kernel def hashes. An added benefit of this is the
possibility of moving away from kernel def hashes completely, which
would eliminate the maintenance burden of keeping the hashes stable.
# Approach
In a full build, ORT uses some information from the ONNX op schema to
match a node to a kernel. We want to avoid including the ONNX op schema
in a minimal build to reduce binary size. Essentially, we take the
necessary information from the ONNX op schema and make it available in a
minimal build.
We decouple the ONNX op schema from the kernel matching logic. The
kernel matching logic instead relies on per-op information which can
either be obtained from the ONNX op schema or another source.
This per-op information must be available in a minimal build when there
are no ONNX op schemas. We put it in the ORT format model.
Existing uses of kernel def hashes to look up kernels are replaced
with the updated kernel matching logic. We no longer store
kernel def hashes in the ORT format model’s session state and runtime
optimization representations. We no longer keep the logic to
generate and ensure stability of kernel def hashes.
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
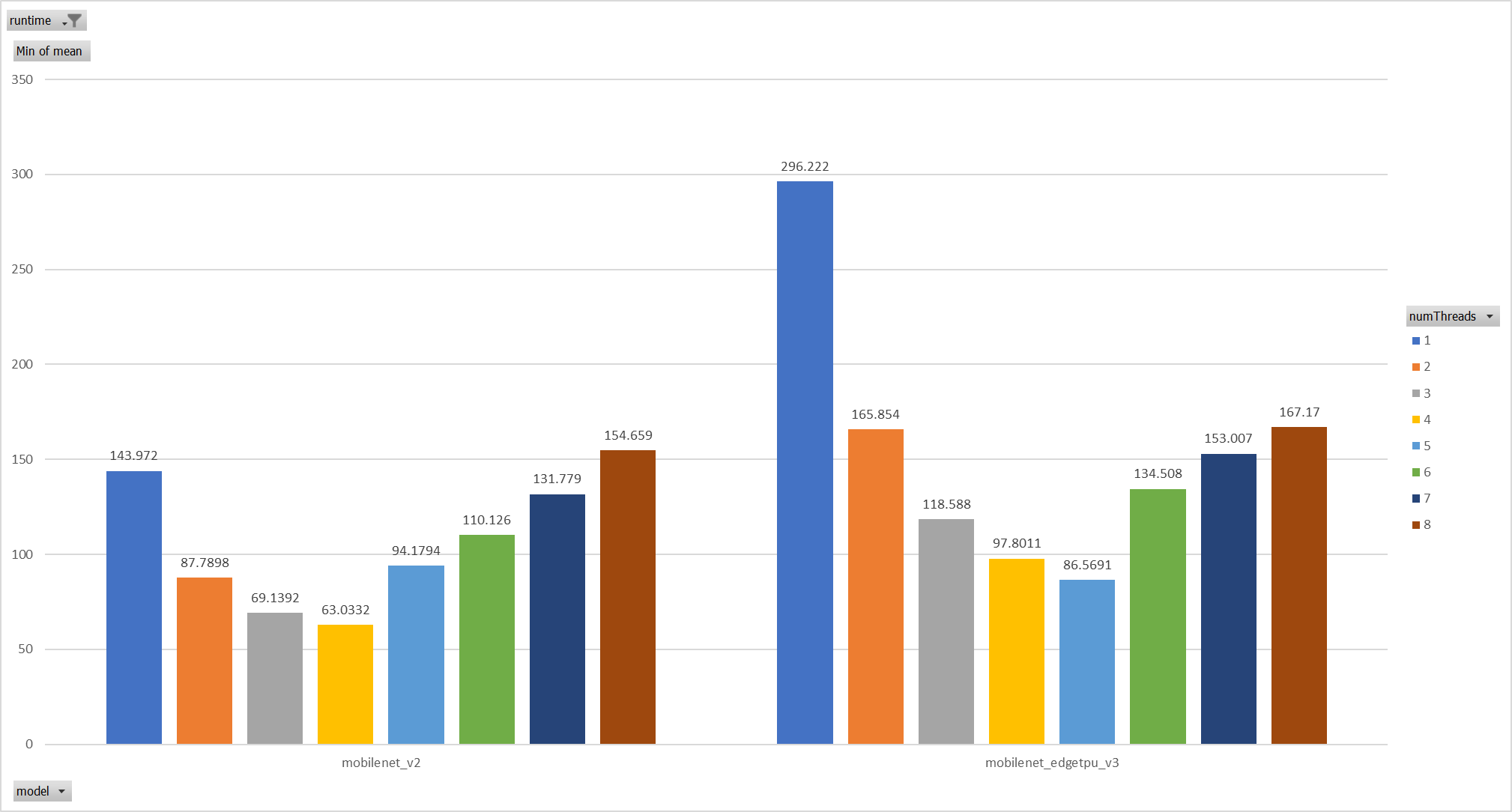
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
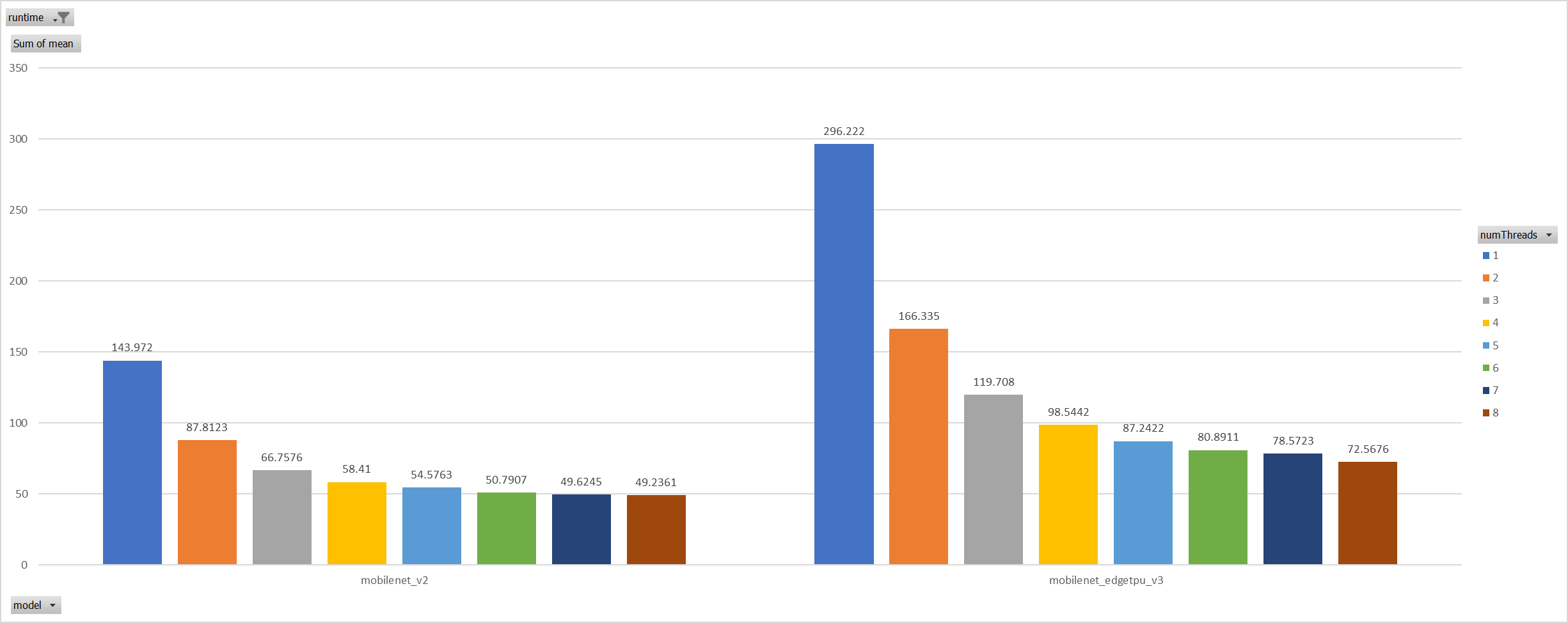
Case 2:
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
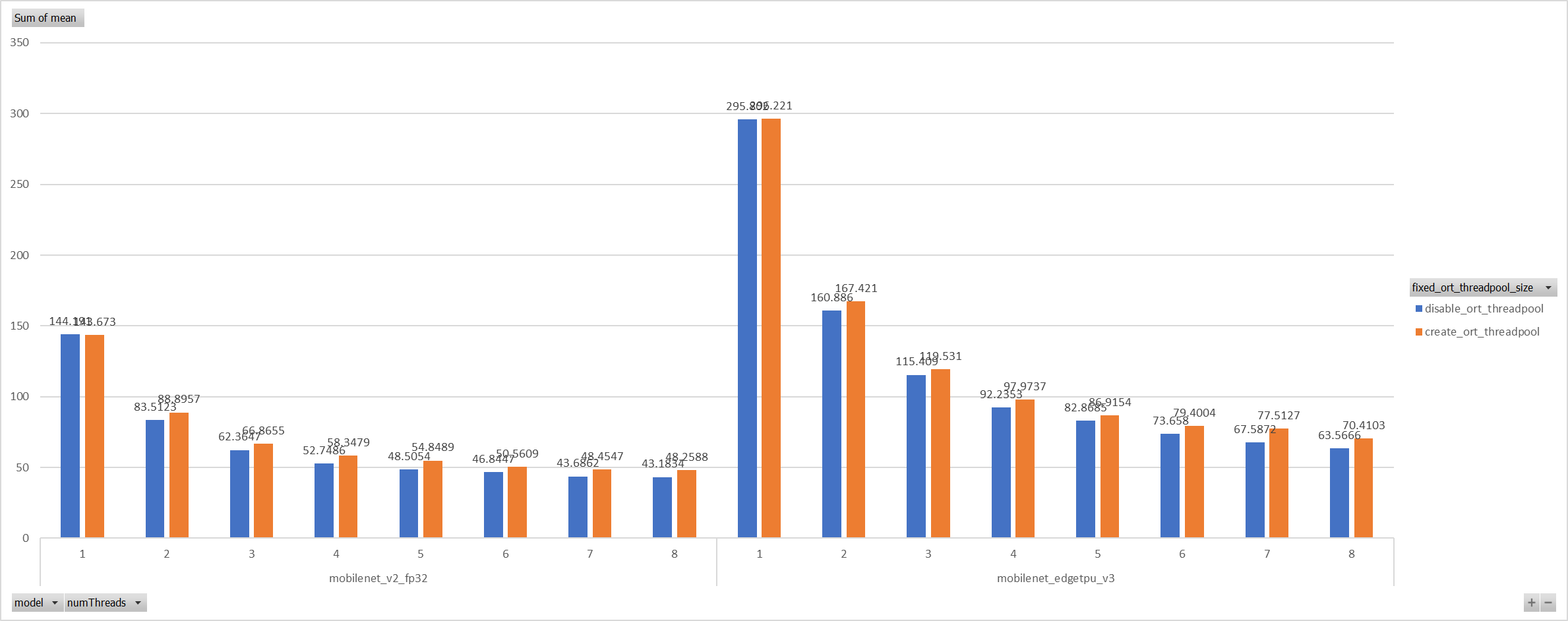
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
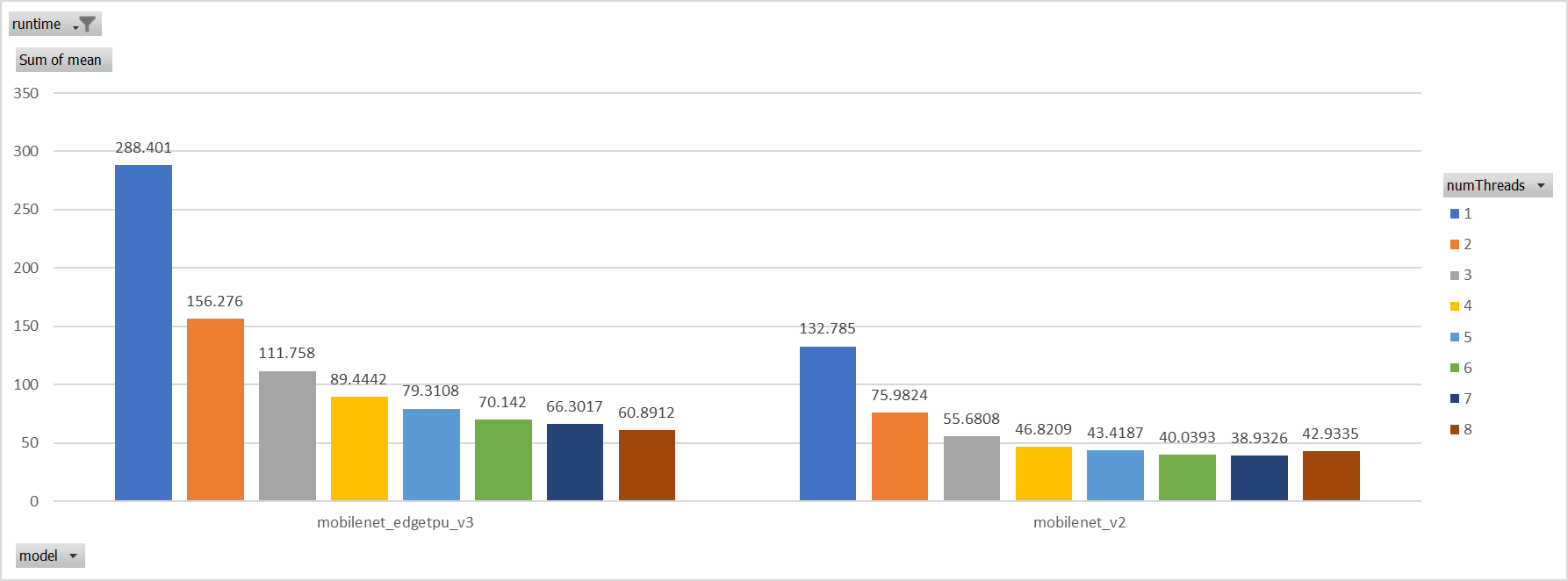
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
* upgrade emsdk to 3.1.19
* fix build break
* ignore '-Wunused-but-set-variable' in eigen
* add malloc and free in exported functions
* EXPORTED_FUNCTIONS
* Add first pass of rocm kernel profiler
* Clean up rocm_profiler. Format args. Demangle kernel names.
Add Api EventRecords
* Remove debug output
* Temporarily disable profiling unit test 'api record check' for cupti
* Fix compile error for non-gpu builds
* Use common file for demangle and pid/tid. Namespace ThreadUtil. Fix gpu buffer clearing.
* Merge demangle into profiler_common
* Merge demangle into profiler_common part 2
* Style cleanup
* Resolve linking issues via ProviderHost interface
* Demangle cuda kernel names
* Clean up comments
* Fix formatting
* Fix anal retentive formatting
LLVM compiler complains the std::hash<const char*> and suggests std::hash<const void*>. But the intention is to hash the name string instead of the pointer. So use std::hash<std::string> to be explicit.
* Add ability to use ORT format model flatbuffer directly for intiializers by leveraging the TensorProto external data infrastructure.
Requires user to provide ORT format model bytes when creating the session, and set both `session.use_ort_model_bytes_directly` and `session.use_ort_model_bytes_for_initializers` to 1 in SessionOptions config entries (AddSessionConfigEntry in C API).
Add a graph optimization that convert u8s8 matrix multiplication to u8u8 if needed
In x86/64 platforms, specifically SSE4.1, AVX2 and AVX512 CPUs provide better performance computing u8s8 matrix multiplications. Unfortunately, the higher performance comes with value overflow problems, as described in:
https://www.intel.com/content/www/us/en/develop/documentation/onednn-developer-guide-and-reference/top/advanced-topics/nuances-of-int8-computations.html
In this change we added a session option "session.x64quantprecision" (default off). For operators that calls u8s8 matrix multiplications, e.g. QAttention, we convert them to u8u8 when the following conditions are all satisfied:
1. Current CPU is SSE4.1, AVX2 or AVX512 with no VNNI support
2. Session option "session.x64quantprecision" is on.
3. Constant weight tensor contains values outside of [-64, 63] range
Note that when weight tensor is not constant, QDQS8ToU8Transformer should already convert it to u8.
* create op from ep
* read input count from context
* create holder to host nodes
* fix typo
* cast type before comparison
* throw error on API fail
* silence warning from minimal build
* switch to unique_ptr with deleter to host nodes
* fix typo
* fix build err for minimal
* fix build err for minimal
* add UT for conv
* enable test on CUDA
* add comment
* fix typo
* use gsl::span and string view for Node constructor
* Added two APIs - CopyKernelInfo and ReleaseKernelInfo
* pass gsl::span by value
* switch to span<NodeArg* const> to allow for reference to const containers
* fix typo
* fix reduced build err
* fix reduced build err
* refactoring node construction logic
* rename exceptions
* add input and output count as arguments for op creation
* refactor static member
* use ORT_CATCH instead of catch
* cancel try catch
* add static value name map
* format input definition and set err code
* fix comments
* fix typo
* Revert "Revert "Refactor ExecutionFrame and SessionState to reduce memory all… (#11888)"
This reverts commit d2cbae3a04.
* Revert prepacked_weights to avoid indirect inclusion in CUDA and TRT code that breaks the build.
Minor wording update to warning message to clarify that the function style Compile API is deprecated now and will be removed soon.
Also updated some code comments.
* Rework the EP factory creation setup so we're not cut-and-pasting function declarations in multiple places.
Convert append EP for SNPE to be generic, and also use for XNNPACK.
Add XNNPACK to C# API
* Don't need stub for MIGraphX as it's using provider bridge.
* Remove old 'create' functions that aren't applicable now that the EPs are built as separate libraries.
* Only use EPs that require the layout transform if the opset is supported by the layout transformer.
* Update wasm registration of xnnpack.
* C API version 0.001
* fix linker issues
* fixes for save checkpoint api
* plus fixes based on tests
* plus test_runner and other changes
* Plus cosmetic updates
* remove unnecessary headers
* plus some updates
* plus more changes
Co-authored-by: Ashwini Khade <askhade@microsoft.com@orttrainingdev10.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
* Reserve the first core for the main thread
Currently in "auto affinity" mode the worker threads are affinized to cores 0..(N-1), leaving the very last core for the main thread. This patch preserves core #0 for the main thread, and affinizes the worker threads to cores 1..N.
* Avoid unneeded spin_pause in thread pool's worker threads
Remove unneeded PAUSE instruction (0.1-0.2 usec latency) after a worker thread finds a task to execute.
* MLAS/x86: optimize QLinearConv on hybrid CPUs
Existing 4x task granularity for task partitioning on hybrid CPUs is
not sufficient to compensate the difference of VNNI instructions
throughput
between performance and efficient cores. This patch...
* Increases granularity for QLinearConv by 2x, to have 2x more tasks
with 2x
smaller output count
* Limits QLinearConv task count from above, to avoid output count per
task
getting smaller than kernel's capability
* Remove hardcoded task count for QLineConv as it limited scaling on
16+ cores CPUs
* MLAS/x86: optimize QLinearConv on hybrid CPUs
Existing 4x task granularity for task partitioning on hybrid CPUs is not sufficient to compensate the difference of VNNI instructions
throughput between performance and efficient cores. This patch...
* Increases granularity for QLinearConv by 2x, to have 2x more tasks
with 2x smaller output count
* Limits QLinearConv task count from above, to avoid output count per
task getting smaller than kernel's capability
* Remove hardcoded task count for QLineConv as it limited scaling on
16+ cores CP
* Addressing comments
* combining x86 ARM branches in qlinearconv threaded job partition
* revert first core assignment
Co-authored-by: Saurabh <saurabh.tangri@intel.com>
Co-authored-by: Chen Fu <fuchen@microsoft.com>
* aten op for inference
* fix build error
* more some code to training only
* remove domain from operator name
* move aten_op_executor ext out from ortmodule
* add pipeline
* add exec mode
* fix script
* fix ut script
* fix test pipeline
* failure test
* rollback
* bugfix
* resolve comments
* enable aten for python build only
* fix win build
* use target_compile_definitions
* support io binding
* turn off aten by default
* fix ut
Co-authored-by: Vincent Wang <weicwang@microsoft.com>
Co-authored-by: zhijxu <zhijxu@microsoft.com>
* Rework allocator sharing to work for multiple devices.
* Update SessionState to not use allocator name in matching for consistency with IExecutionProvider. The name doesn't have any clear meaning (e.g. we use the same name for the per-thread allocator in the CUDA EP as the shared allocate there and in the TRT EP).
* NOTE: this means we will have one allocator per OrtMemType+OrtDevice.
* Reverse order when doing allocator setup in SessionState. This will result in the CPU and CUDA EPs allocators being preferred (they are the most configurable), and also means the per-thread CUDA allocator for default GPU memory will be used even when TRT is enabled.
* NOTE: Combined with the change to remove the allocator name from the key this will mean that if CUDA and TRT or ROCM and MIGraphX are both enabled the CUDA/ROCM per-thread allocator will be used to allocate GPU memory.
* Use InsertAllocator instead of TryInsertAllocator. Each EP should be registered once, and we should only enter RegisterAllocator once, so the 'try' should not be required and would indicate an unexpected setup was involved. i.e. better to fail and figure out if we need to support that setup.
* Add some clarifying comments around how replace allocator works.
* Add unit testing for setup where EP has local allocator that may get out of sync with values in the IExecutionProvider base class.
* Fix invalid check of whether data is on CPU to use device info instead of allocator name.
This reverts commit 1f2c926. Because it makes our packaging pipeline crash
Error message:
[ RUN ] QLinearConvTest.Conv3D_S8S8_Depthwise
Test #1: onnxruntime_test_all ...................Subprocess killed***Exception: 838.24 sec
We haven't successfully reproduced the bug on a real ARM64 hardware. Currently we only saw it showed up with qemu. More investigations are on-going.
* Initiate Ort SNPE EP
* fix snpe ep windows build which is caused by the utility method (ToUTF8String) name change on master
* correct the source path for libonnxruntime.so while building for andorid package
* add AdditionalDependencies for amr64
* On MS-Windows, the patchfile must be a text file, i.e. CR-LF must be used as line endings. A file with LF may give the error: "Assertion failed, hunk, file patch.c, line 343," unless the option '--binary' is given.
* fix build failure if snpe is not enabled
* update doc for contrib op
* separate out snpe ep settings to onnxruntime_snpe_provider.cmake
* renaming according review comments
* update according review comments
{kind=link}
{kind=link}
{kind=link}
{kind=link}