### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Improve perf for stage3 training - first wave
Port existing PythonOp/PythonOpGrad python runner to C++, also introduce
an unsafe run mode (to skip inplace, save for backward, materrialized
grad detection on the fly).
This reduce the overhead from XX~XXX us to X ~ lower end of XX us . In
LLAMA2 7B training with 8x32GV100, we have observed 6.7% gains over
PyTorch. (1.59 v.s. 1.49it/s)
Peak memory also dropped from 31GB to 28GB.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
TrainingSession has been deprecated for a while now, but the gradient
ops tests are still using training session. This PR updates these tests
to use inference session instead of training session.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This will enable us to remove all the training session related
deprecated code from the repo.
### Disable test_bert_result_with_layerwise_recompute
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Allow layer-wise recompute
Early, we need users/developers to specify the subgraphs to recompute,
now we introduced a more user-friendly way to enable recompute for all
detected stashed activation recomputation subgraphs. This scarifies
getting the best configs while makes it easier to support user
requirements when they switches from PyTorch per-layer gradient
checkpoint to ORTModule.
`ORTMODULE_MEMORY_OPT_LEVEL` is introduced to control the usage, by
default, it is 0, e.g. `USER_SPECIFIED`, all subgraphs definedin
`ORTMODULE_MEMORY_OPT_CONFIG` will be recomputed. So this is compatible
to existing recompute usage in ORTModule integrated models.
Using `ORTMODULE_MEMORY_OPT_LEVEL=1`, we will enable all recompute plans
detected, so those configs in `ORTMODULE_MEMORY_OPT_CONFIG` will not be
respected any more.
Add Unit Tests using 3 layer blooms.
https://github.com/microsoft/onnxruntime/blob/pengwa/add_aggresive_recompute/docs/Memory_Optimizer.md
### Description
Updating transformers package in test pipeline to fix a security
vulnerability.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Skip module clone for preparing large model export
For LLAMA2 13B, when running with Lora, DeepSpeed stage2 on 8 GPUs . It
failed during preparing outputs which will be used for
torch.onnx.export. The reason, we deep copy all the params including
both big sizes of frozen weights, + a little bit of Lora trainable
weight.
This PR will firstly check whether the GPU memmory is enough for a
cloned module, if not, skip the copy.
Copying the module is to guarantee the fw path run may change the
weight, while this case should be rare. But for now, Not-Able-To-Run is
worse than Runnable-with-A-little-bit-different-initial-weight,
especially for large models.
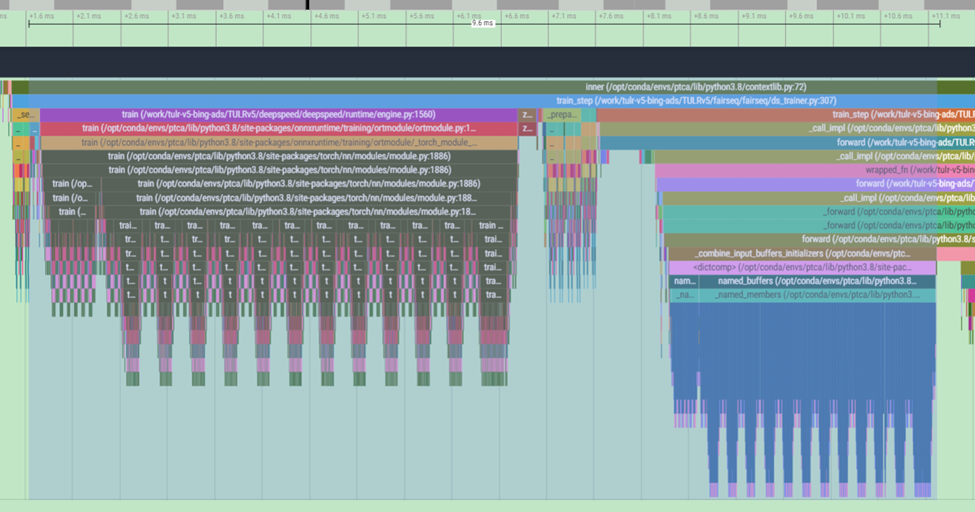
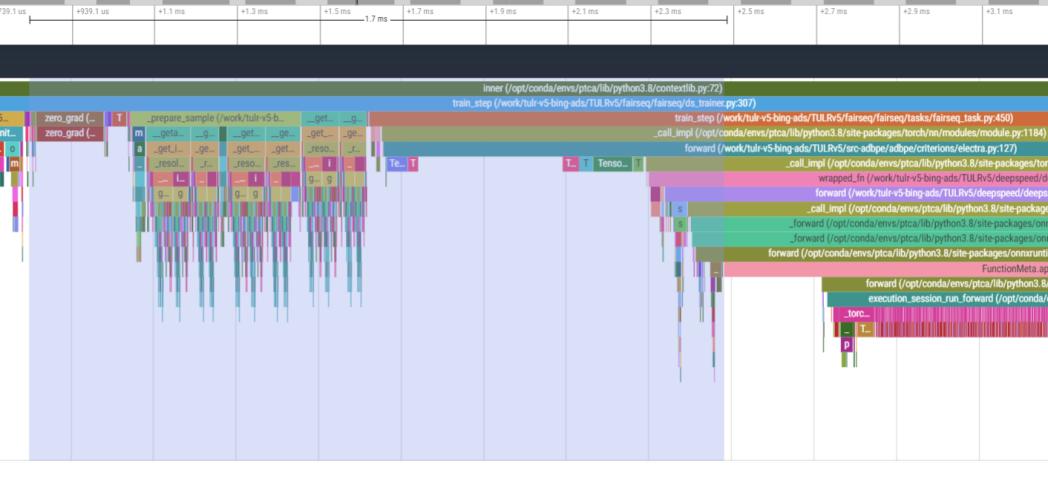
ORT's default topo-order is a reversed DFS algorithm, while the
priority-based topo-order is a forward BFS algorithm. It's likely that
the default order is better than priority-based order on memory because
tensor memory is more likely to be released right after it's consumed.
Currently ORTModule uses priority-based order, for some models, it sorts
lots of small Ops to the beginning, this introduces big CPU overhead at
the beginning (see below screenshot), this PR is to use default order
for training. The priority-based order is heavily used for some
recompute optimization, so if there is recompute enabled, we will still
use priority-based order.
This PR also adds an optimization to the default order, which is to move
all Shape/Size Ops to right after their parent nodes. This is to make
sure the shape and size nodes are executed right after their parents so
it's possible the input tensor memory can be released as soon as
possible. This is especially important for non-CPU devices or for
training case where some gradient graphs use only shape/size of tensors
from forward.
Profiling result:
Before
<img width="910" alt="截屏2023-11-13 12 09 02"
src="https://github.com/microsoft/onnxruntime/assets/11661208/e54d5ead-274f-4725-923e-521bbcfce752">
After
<img width="910" alt="截屏2023-11-13 12 10 44"
src="https://github.com/microsoft/onnxruntime/assets/11661208/f50d196d-11ac-43a2-9493-517e4552ffab">
This PR:
- Remove unused arguments from generated triton code,
- Remove unnecessary mask for symbolic shape case from generated triton
code.
- Add doc for usage of ORTMODULE_TRITON_CONFIG_FILE.
deleted the unused random_device variables because they caused a warning
that was treated like an error.
**_Please check if the declaration is required for the random number
generation. if so, there need to be a dummy reference to the variable or
turning off the warning as error behavior._**
### Description
<!-- Describe your changes. -->
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
`generate_artifacts` generates 4 graphs for training. All graphs should
share the same opset version, the one coming from the model to train,
but the optimizer is left undefined. onnxruntime is using the latest
version defined by onnx but onnxruntime does not necessarily support it.
### Motivation and Context
The code does not let the user change it.
### Description
<!-- Describe your changes. -->
Add bfloat16 support for `MatMulBnb4` contrib op. This is useful for
QLoRA fine-tuning.
- On GPUs with SM80+ (A100, etc), it uses the native cuda bfloat16
dtype, `nv_bfloat16`. On other GPUs, it uses the onnxruntime `BFloat16`
type which uses float for compute.
- I have validated the op in a llama2-7b training scenario. The losses
match pytorch training and the training throughput is better.
- Cannot add a bfloat16 case in the op unit test since casting BFloat16
to and from float multiple times during the test causes the required
tolerances to be unachievable.
The custom autograd function exporter in onnxruntime-training is updated
to support the latest version of bitsandbytes. They changed how the
`quant_state` is stored.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Enable QLoRA fine-tuning with bfloat16.
Recent PyTorch breaks DORT CI and [a
patch](https://github.com/pytorch/pytorch/pull/113697) has been merged
into PyTorch main. In order to update DORT's CI, we made dummy change in
this PR.
### Description
Motivation for this PR is code cleanup.
1. Remove all deprecated python code related to orttrainer, old
checkpoint, related tests and utils
2. Cleanup orttraining_pybind_state.cc to remove all deprecated
bindings.
in LoRA code, it will use conv1d to do projection for qkv, while the
conv1d calculation is mathematically equivalent to matmul, and matmul is
much faster than conv1d.
The subsitution of the graph optimizer is: 1 conv1d >> 2 split + 1
squeeze + group_num matmul + 1 concat
with this optimizer, we see 10%+ in one 1P model
### Description
Add an op named `FlattenAndUnpad`.
This op implements functions:
1. Flatten the first two dims of input tensor.
2. Gather valid value from input tensor with index tensor,.
### Motivation and Context
The grad op of `PadAndUnflatten` was `GatherGrad` which is inefficient
in performance.
I implement this `FlattenAndUnpad` just to replace the `GatherGrad` as
grad of `PadAndUnflatten`.
With this op, we also can simplify the "Reshape + ShrunkenGather"
pattern to `PadAndUnflatten` in padding elimination optimizer, which
will also improve performance.
### Description
<!-- Describe your changes. -->
Registers BFloat16 datatype as valid input type for CUDA QuickGeluGrad
Kernel.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Enabling `meta-llama/Llama-2-70b` to be finetuned with ONNX Runtime
training.
---------
Co-authored-by: Prathik Rao <prathikrao@microsoft.com@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
### Tune logging experience a bit
After last time we update the ORTModule log experience, we found few
issues:
1. `INFO` level output too many things, including PyTorch exporter
verbose logs (tracing graphs) on every ranks. On this level, we only
want to
- Output a little bit more information to Users than `WARNING` level,
for example the memory recomputation recommendations or other
not-fully-ready features.
- Output a little bit more information for a quick diagnostic, collected
on rank-0 only.
2. ONNX Runtime logging filter during graph build, session init
sometimes will hide the issues (for example segement fault), there is no
useful information in `WARNING`/`INFO` for users to report to us. This
is not good!
3. Some of our devs like using `pdb` to debug Python code, but if we add
`import pdb; pdb.set_trace()` in models' code might hang when they use
`INFO` or `WARNING`, where exporter happens and all output got
redirected due to log filtering. The only workaround is to switch to
VERBOSE, which output toooooooooooo many logs.
The corresponding changes proposed here are:
1. For `INFO` logging,
- We only logs rank-0.
- We restricted the ORT backend logging level to be WARNING in this
case, because ORT backend code output way too many logs that should be
under verbose, while we cannot guarantee we can get them cleaned up
immediately once they are added.
- We output the PyTorch exporter verbose log (including tracing graph),
which is useful for a quick diagnostic when an issue happens.
2. Remove all logging filtering on ORT backend, then the segment fault
issue details will not be hidden once it happens again.
3. Introduced a `DEVINFO` logging,
- Log logs on all ranks
- Log ORT backend logging level INFO
- PyTorch exporter logging filtering are all turned OFF (to unblock the
pdb debugging).
4. Currently, to use Memory Optimizer, need use DEVINFO (which will
output ORT backend INFO log). So update memory optimizer document to
reflect this. https://github.com/microsoft/onnxruntime/pull/17481 will
update the requirement back to INFO for show memory optimization infos.
You can check
https://github.com/microsoft/onnxruntime/blob/pengwa/devinfo_level/docs/ORTModule_Training_Guidelines.md#log-level-explanations
for a better view of different log levels.
This PR also extract some changes from a bigger one
https://github.com/microsoft/onnxruntime/pull/17481, to reduce its
complexity for review.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
---------
Co-authored-by: mindest <30493312+mindest@users.noreply.github.com>
### Description
<!-- Describe your changes. -->
Updates input/output type constraints on training operators
ConcatTraining and SplitTraining to include bfloat16 which was
introduced in IR version 4.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Enabling `meta-llama/Llama-2-70b` to be finetuned with ONNX Runtime
training.
Co-authored-by: Prathik Rao <prathikrao@microsoft.com@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
### Customize _get_tensor_rank for model export in stage3
Weight/Params sizes are all (0), so exporter logic depending on input
shape will fail.
This PR override `_get_tensor_rank` function by retrieving the shape for
weight differently.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Optimize 4bit Qlora training
Extent existing `MatmulBnb4bit` to its usage in training scenarios.
The PR includes following changes:
1. Add special `torch.autograd.Function` export logic for
`bitsandbytes.autograd._functions.MatMul4Bit` that is preferred before
common PythonOp exporter.
2. Add `training_mode` optional attribute for op `MatmulBnb4bit`, which
help skip some inference specific logic in implementation.
3. Add `transB` optional attribute, which is by default be 1; setting it
to be 0 is needed by backward usage.
Changing from `PythonOp` to this `MatmulBnb4bit` brings roughly ~2.9%
throughput gains. The reason is:
`bitsandbytes.autograd._functions.MatMul4Bit` has logic
`ctx.save_for_backward`, which would need an additional copy in
PythonOp, otherwise, the tensor might be released by ORT, while backward
op still references it.
Removing the clones also reduce the peak memory consumptions because
`bitsandbytes.autograd._functions.MatMul4Bit` saved tensors that are not
needed in backward compute.
### Description
Transpose is equivalent to a Reshape if:
empty dimensions can change place, not empty dimensions must be in
the same order in the permuted tenosr.
Example: Shape=(1,1,1024,4096) -> perm=(2,0,3,1).
This pr adds a graph transformer which replaces Transpose with Reshape
if they are equivalent.
Because Transpose need memory copy while Reshape needn't, this
replacement can save overhead for memory copy.
This PR is to support efficient attention and flash attention in
ORTModule, including:
- Use ATen to call efficient attention, which requires PyTorch 2.2.0 dev
or newer. ORTMODULE_USE_EFFICIENT_ATTENTION=1 to enable.
- Integrate Triton Flash attention, which requires
triton==2.0.0.dev20221202. Need A100 or H100.
ORTMODULE_USE_FLASH_ATTENTION=1 to enable.
- A python transformer tool to match sub-graph by config and write
transformer quickly.
Current transformers supports attention mask for both efficient attn and
flash attn, and dropout for efficient attn only. To support more
training scenarios (such as causal mask in GPT2), more transformers need
to be added.
The feature is guarded by system environment variables, it won't effect
any current behavior if not enabled. Since it requires specific
PyTorch/Triton versions, related tests is not added for now.
### FP16 optimizer automatically detect DeepSpeed compatibility
Optimum/Transformers are using accelerate lib to prepare models, so our
FP16 optimizer wrapper does not work for long time. Because the
namespace is `accelerate.utils.deepspeed.DeepSpeedOptimizerWrapper`,
which underlying is still calling into DeepSpeed stage1and2 optimizer.
This PR includes following changes:
1. Add `accelerate.utils.deepspeed.DeepSpeedOptimizerWrapper` in the
modifier registry, plus a check on its contained `optimizer` property
MUST be DeepSpeed stage 1 and 2 optimizer. (let's cover Stage 3
optimizer later)
2. For DeepSpeed version > 0.9.1, we will store the source code in a
version list. As long as the related function in DeepSpeed remains
unchanged during its new release, we won't need manually upgrade the
version check any more. If some day, the source code did not match, a
warning will be raised to users, to add a new version of source code in
the list.
With the above change, we will have our FP16 Optimizer working again in
Optimum.

### Support inplace update for PythonOp/Grad
This PR is based on another PR
https://github.com/microsoft/onnxruntime/pull/17685's branch, to make it
easier to review.
With PR: PR https://github.com/microsoft/onnxruntime/pull/17685, By
default all PythonOp inputs/outputs are assumed to not be inplaced, if
during run, we found some inplace update happens (by checking output
data address with all inputs data address), we add clone before set it
as PythonOp/Grad's outputs. In this case, results are correct, but
implicit copies overheads are introduced.
This PR allow users to define output input reuse map, to let ORT know
how to do the reuse map, avoid such unnecessary copies.
### Description
<!-- Describe your changes. -->
Patch for All gather fn for Deepspeed Stage 3 changes
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
- Update ROCm and MIGraphX CI to ROCm5.7
- Simplify test exculde file. Some tests will output `registered
execution providers ROCMExecutionProvider were unable to run the model.`
if they cannot run.
- Add `enable_training` build argument for MIGraphX pipeline.
### Fix convergence for dolly+stage3 training
In
[ZeROOffloadSubscriber](216214b7d3/orttraining/orttraining/python/training/utils/hooks/_zero_offload_subscriber.py (L359C7-L359C28)),
we defined some PythonOp, taking input and returning it inplace, for
example:
216214b7d3/orttraining/orttraining/python/training/utils/hooks/_zero_offload_subscriber.py (L223C20-L223C20).
While it is possible, when ORT runs such a PythonOp, once it completes,
it will release the input OrtValue, triggered the data erasing or
overridden. But the PythonOp's returned value OrtValue are still
pointing to that address, reading or writting on that may introduce a
wrong result or even undefined behaviors.
```
/bert_ort/pengwa/py38/lib/python3.8/site-packages/onnxruntime/training/ortmodule/_custom_autograd_function_runner.py:28: UserWarning: .rank-0: onnxruntime.training.utils.hooks._zero_offload_subscriber.ORTZeROOffloadPreForwardFunction->Backward: ONNX Op attribute 'tensor_reuse_map' doesn't indicate 8-th output is reusing any input, but detected inplace_map indicates it is reusing some input index. A clone will be done before returning to ORT, to align with ORT's NO Buffer reuse plan. Please update inplace_map explicitly to avoid such a copy.
warnings.warn(f".rank-{get_rank()}: {message}")
0%|▏ | 1/1000 [00:04<1:15:08, 4.51s/it][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,023 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 14.1406, 'learning_rate': 0, 'epoch': 0.0}
0%|▏ | 1/1000 [00:04<1:15:08, 4.51s/it]Invalidate trace cache @ step 5: expected module 6, but got module 7
0%|▍ | 2/1000 [00:04<31:53, 1.92s/it][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,124 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
0%|▋ | 3/1000 [00:04<18:05, 1.09s/it][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,227 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
0%|▋ | 3/1000 [00:04<18:05, 1.09s/it][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,326 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
0%|█▏ | 5/1000 [00:04<08:44, 1.90it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,419 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
0%|█▏ | 5/1000 [00:04<08:44, 1.90it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,505 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
1%|█▋ | 7/1000 [00:05<05:28, 3.02it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,597 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
1%|█▋ | 7/1000 [00:05<05:28, 3.02it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,690 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
1%|██▏ | 9/1000 [00:05<03:57, 4.17it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,791 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
1%|██▏ | 9/1000 [00:05<03:57, 4.17it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,889 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
1%|██▋ | 11/1000 [00:05<03:06, 5.32it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:44,981 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.0}
1%|██▋ | 11/1000 [00:05<03:06, 5.32it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:45,073 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.01}
1%|███▏ | 13/1000 [00:05<02:33, 6.42it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:45,166 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.01}
1%|███▏ | 13/1000 [00:05<02:33, 6.42it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:45,256 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.01}
2%|███▌ | 15/1000 [00:05<02:12, 7.43it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:45,348 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.01}
2%|███▌ | 15/1000 [00:05<02:12, 7.43it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:45,439 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.01}
2%|████ | 17/1000 [00:06<01:59, 8.22it/s][WARNING|trainer_pt_utils.py:849] 2023-09-25 08:30:45,535 >> tried to get lr value before scheduler/optimizer started stepping, returning lr=0
{'loss': 0.0, 'learning_rate': 0, 'epoch': 0.01}
2%|████ | 17/1000 [00:06<01:59, 8.22it/s]Traceback (most recent call last):
File "examples/onnxruntime/training/language-modeling/run_clm.py", line 600, in <module>
main()
File "examples/onnxruntime/training/language-modeling/run_clm.py", line 548, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/bert_ort/pengwa/optimum/optimum/onnxruntime/trainer.py", line 457, in train
return inner_training_loop(
File "/bert_ort/pengwa/optimum/optimum/onnxruntime/trainer.py", line 781, in _inner_training_loop
self.deepspeed.step()
File "/bert_ort/pengwa/deepspeed/deepspeed/runtime/engine.py", line 2084, in step
self._take_model_step(lr_kwargs)
File "/bert_ort/pengwa/deepspeed/deepspeed/runtime/engine.py", line 1990, in _take_model_step
self.optimizer.step()
File "/bert_ort/pengwa/deepspeed/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
ret_val = func(*args, **kwargs)
File "/bert_ort/pengwa/deepspeed/deepspeed/runtime/zero/stage3.py", line 1854, in step
if self._overflow_check_and_loss_scale_update():
File "/bert_ort/pengwa/deepspeed/deepspeed/utils/nvtx.py", line 15, in wrapped_fn
ret_val = func(*args, **kwargs)
File "/bert_ort/pengwa/deepspeed/deepspeed/runtime/zero/stage3.py", line 1788, in _overflow_check_and_loss_scale_update
self._update_scale(self.overflow)
File "/bert_ort/pengwa/deepspeed/deepspeed/runtime/zero/stage3.py", line 2132, in _update_scale
self.loss_scaler.update_scale(has_overflow)
File "/bert_ort/pengwa/deepspeed/deepspeed/runtime/fp16/loss_scaler.py", line 175, in update_scale
raise Exception(
Exception: Current loss scale already at minimum - cannot decrease scale anymore. Exiting run.
2%|████ | 17/1000 [00:06<06:07, 2.67it/s]
[2023-09-25 08:30:51,075] torch.distributed.elastic.multiprocessing.api: [ERROR] failed (exitcode: 1) local_rank: 0 (pid: 1065120) of binary: /bert_ort/pengwa/py38/bin/python
Traceback (most recent call last):
File "/bert_ort/pengwa/py38/bin/torchrun", line 8, in <module>
sys.exit(main())
File "/bert_ort/pengwa/py38/lib/python3.8/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper
return f(*args, **kwargs)
File "/bert_ort/pengwa/py38/lib/python3.8/site-packages/torch/distributed/run.py", line 806, in main
run(args)
File "/bert_ort/pengwa/py38/lib/python3.8/site-packages/torch/distributed/run.py", line 797, in run
elastic_launch(
File "/bert_ort/pengwa/py38/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/bert_ort/pengwa/py38/lib/python3.8/site-packages/torch/distributed/launcher/api.py", line 264, in launch_agent
raise ChildFailedError(
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
============================================================
examples/onnxruntime/training/language-modeling/run_clm.py FAILED
------------------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
------------------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-09-25_08:30:51
host : orttrainingdev10.internal.cloudapp.net
rank : 0 (local_rank: 0)
exitcode : 1 (pid: 1065120)
error_file: <N/A>
traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html
============================================================
(/bert_ort/pengwa/py38) pengwa@microsoft.com@orttrainingdev10:/bert_ort/pengwa/optim
```
## The Fix
For those output that are reusing input, but ORT is not aware of, we
detected on the fly (the first iteration, by checking the output tensor
addresses with input tensor addresses) , then do implicit copy before
set it as PythonOp's output tensors.
With this fix: (left: PyTorch, right: ORT)

Bump ruff version and remove pylint from the linter list. Fix any new
error detected by ruff.
### Motivation and Context
Ruff covers many of the pylint rules. Since pylint is not enabled in
this repo and runs slow, we remove it from the linters
Python API to check whether collective ops are available or not
### Description
<!-- Describe your changes. -->
Adding an API to check whether collective ops are available or not.
Since there is no independent MPI enabled build, this flag can be used
on Python front for branching. Specifically, to conditionally enable
tests.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Flag to be used in Python to check whether onnxruntime supports
collective ops or not. Handy for conditionally enabling/disabling tests
and for other branching decisions.
Add Gelu/QuickGelu/GeluGrad/QuickGeluGrad support to Triton Codegen so
that it can be fused with some other connected supported Ops. For
example, in llama2, it can be fused with Mul so we will have extra 1-2%
perf gain.
### Description
<!-- Describe your changes. -->
* Allow either an allocator or a MemBuffer to be used when creating an
OrtValue from an TensorProto
* `Tensor<std::string>` requires an allocator to allocate/free the
string values
* Forcing the buffer to be allocated outside of the Tensor doesn't seem
to provide any benefit in this usage as the Tensor class disables copy
and assignment (so we wouldn't create 2 copies of the buffer via the
Tensor class that externally managing the would buffer avoid)
* New approach means we don't need to manage the buffers in the
optimizer Info class as the Tensor dtor will do that
* Update naming - MLValue was replaced by OrtValue a long time ago
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
#17392
### Description
this is for ORT 1.17.0 - make ORT to use ONNX release 1.15.0 branch. Eventually will update to the release tag once ONNX 1.15.0 is released
### Motivation and Context
Prepare for ORT 1.17.0 release. People can start work on new and updated ONNX ops in ORT.
---------
Signed-off-by: Liqun Fu <liqfu@microsoft.com>
{kind=link}
{kind=link}