### Description
Remove the parameter device_id out of ExecutionProvider::GetAllocator()
function
### Motivation and Context
The parameter device_id is not necessary. We can fully rely on the
second parameter OrtMemType mem_type to determine the device_id when
getting allocator from executionProvider.
### Description
This is exposing the already existent interface of asynchronous work of
all CUDA base EP's (CUDA + TensorRT).
### Motivation and Context
This is something requested in #12216. It will enable users to build an
efficient data pipeline with ONNXRuntime and CUDA pre-/post-processing.
PCI traffic to the CUDA device can be run during inference as soon as
the postprocessing consumed the input buffer and it can be overwritten.
To do this work has to be submitted async to the device. Please see
below screenshots showing the illustration of this using NSight Systems.
Async:
<img width="1401" alt="image"
src="https://user-images.githubusercontent.com/44298237/209894303-706460ed-cbdb-4be2-a2e4-0c111ec875dd.png">
Synchronous:
<img width="1302" alt="image"
src="https://user-images.githubusercontent.com/44298237/209894630-1ce40925-bbd5-470d-b888-46553ab75fb9.png">
Note the gap in between the 2 inference runs due to issuing PCI traffic
in between and to the CPU overhead the active synchronization has.
---------
Co-authored-by: Chi Lo <chi.lo@microsoft.com>
### Description
Re-work `OrtApi::GetAvailableProviders` in a way that the data is
returned in a single allocation.
Fix exception safety issues and fix `Release` function.
Remove warning suppressions.
Fix exception safety issue in C++ API.
Fix exception safety issue in C# API.
Move EP name length enforcement to the implementation.
### Motivation and Context
The original motivation comes from
https://github.com/microsoft/onnxruntime/issues/14378.
However, the API is already implemented.
Cc: @prabhat00155
* Added the OrtDnnlProviderOptions structure to expose configuration
options to the user
* The number of threads can be defined by the user with the -i flag on
the perftest
* Number of threads can also be configured via the OMP_NUM_THREADS
environment variable
* The number of threads defined in the OrtDnnlProviderOptions is
prioritized over the environment variable
### Description
Avoids thread oversubscription caused by OpenMP allocating the maximum
number of threads possible for oneDNN EP. Added support for the
OrtDnnlProviderOptions, this will allow for more EP customization
capabilities, and allows for user defined number of threads.
### Motivation and Context
- Improves performances and allows for user to fine tune the number of
threads
### Description
Introduce cache_dir CLI for graph serialisation.
Replace existing use_compile_network and blob_dump_path cli options for
openvino with a single command line option "cache_dir" specifying the
path that needs to be passed for blob dump/load improving the developer
experience.
### Motivation and Context?
We were having two values to set cache dir which was unnecessary
Co-authored-by: Preetha <preetha.veeramalai@intel.com>
### Description
Adds the below C APIs to support custom ops that wrap an entire model to
be inferenced with an external runtime. The current SNPE EP is an
example of an EP that could be ported to use a custom op wrapper. Ex:
The custom op stores the serialized SNPE DLC binary as a string
attribute. The SNPE model is built when the kernel is created. The model
is inferenced with SNPE APIs on call to the kernel's compute method.
#### C APIs
| API | Description | Why |
| --- | --- | --- |
| `KernelInfo_GetInputCount` | Gets number of inputs from
`OrtKernelInfo`. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfo_GetOutputCount` | Gets number of outputs from
`OrtKernelInfo`. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfo_GetInputName` | Gets an input's name. | Query I/O
characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetOutputName` | Gets an output's name. | Query I/O
characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetInputTypeInfo` | Gets the type/shape information for an
input. | Query I/O characteristics during kernel creation<sup>1</sup> |
| `KernelInfo_GetOutputTypeInfo` | Gets the type/shape information for
an output. | Query I/O characteristics during kernel
creation<sup>1</sup> |
| `KernelInfoGetAttribute_tensor` | Get a OrtValue tensor stored as an
attribute in the graph node | Extract serialized models, weights, etc. |
| `GetSessionConfigEntry` | Get a session configuration value | Need to
be able to get session-time configurations from within custom op |
| `HasSessionConfigEntry` | Check if session configuration entry exists.
| Need to be able to get session-time configurations from within custom
op |
#### Why so many KernelInfo APIs?<sup>1</sup>
Similar APIs currently exist for `OrtKernelContext`, but not
`OrtKernelInfo`. Note that `OrtKernelContext` is passed to the custom op
on call to its kernel's compute() function. However, `OrtKernelInfo` is
available on kernel creation, which occurs when the session is created.
Having these APIs available from `OrtKernelInfo` allows an operator to
trade-off computation time for session-creation time, and vice versa.
Operators that must build expensive state may prefer to do it during
session creation time instead of compute-time.
SNPE is an example of an EP that needs to be able to query `KernelInfo`
for the name, type, and shape of inputs and outputs in order to build
the model from the serialized DLC data. This is an expensive operation.
Other providers (e.g., OpenVINO) are able to query i/o info from the
serialized model, so they do not strictly need these APIs. However, the
APIs can still be used to validate the expected I/O characteristics.
Additionally, several of our CPU contrib ops currently use the same
internal version of these KernelInfo APIs (Ex:
[qlinear_softmax](https://github.com/microsoft/onnxruntime/blob/main/onnxruntime/contrib_ops/cpu/quantization/qlinear_softmax.cc#L71)).
If custom ops are also meant to be a test bed for future ops, then all
custom ops (not just runtime wrappers) would benefit from the addition
of these public KernelInfo APIs (IMO).
#### Example of usage in a custom OP
From
`onnxruntime/test/testdata/custom_op_openvino_wrapper_library/openvino_wrapper.h`
```c++
struct CustomOpOpenVINO : Ort::CustomOpBase<CustomOpOpenVINO, KernelOpenVINO> {
explicit CustomOpOpenVINO(Ort::ConstSessionOptions session_options);
CustomOpOpenVINO(const CustomOpOpenVINO&) = delete;
CustomOpOpenVINO& operator=(const CustomOpOpenVINO&) = delete;
void* CreateKernel(const OrtApi& api, const OrtKernelInfo* info) const;
constexpr const char* GetName() const noexcept {
return "OpenVINO_Wrapper";
}
constexpr const char* GetExecutionProviderType() const noexcept {
return "CPUExecutionProvider";
}
// IMPORTANT: In order to wrap a generic runtime-specific model, the custom operator
// must have a non-homogeneous variadic input and output.
constexpr size_t GetInputTypeCount() const noexcept {
return 1;
}
constexpr size_t GetOutputTypeCount() const noexcept {
return 1;
}
constexpr ONNXTensorElementDataType GetInputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr ONNXTensorElementDataType GetOutputType(size_t /* index */) const noexcept {
return ONNX_TENSOR_ELEMENT_DATA_TYPE_UNDEFINED;
}
constexpr OrtCustomOpInputOutputCharacteristic GetInputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr OrtCustomOpInputOutputCharacteristic GetOutputCharacteristic(size_t /* index */) const noexcept {
return INPUT_OUTPUT_VARIADIC;
}
constexpr bool GetVariadicInputHomogeneity() const noexcept {
return false; // heterogenous
}
constexpr bool GetVariadicOutputHomogeneity() const noexcept {
return false; // heterogeneous
}
std::vector<std::string> GetSessionConfigKeys() const { return {"device_type"}; }
private:
std::unordered_map<std::string, std::string> session_configs_;
};
```
#### How to create a session:
```c++
Ort::Env env;
Ort::SessionOptions session_opts;
Ort::CustomOpConfigs custom_op_configs;
// Create local session config entries for the custom op.
custom_op_configs.AddConfig("OpenVINO_Wrapper", "device_type", "CPU");
// Register custom op library and pass in the custom op configs (optional).
session_opts.RegisterCustomOpsLibrary(lib_name, custom_op_configs);
Ort::Session session(env, model_path.data(), session_opts);
```
### Motivation and Context
Allows creation of simple "wrapper" EPs outside of the main ORT code
base.
### Description
When there are 2 QDQ pair back to back, we want to delete the 1 Q and 1
DQ nodes.
ex:
Q->DQ->Q->DQ =====> Q->DQ
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Use dlsym/GetProcAddress to lookup a custom ops registration function by
name and call it.
This will be better on mobile platforms where the custom ops library is
linked against, and there isn't necessarily a filesystem that a library
path can be loaded from.
Alternative is to wire up passing in the address of the function, but
that has multiple complications which differ by platform.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Enable using ort and ort-ext packages on mobile platforms.
Co-authored-by: Edward Chen <18449977+edgchen1@users.noreply.github.com>
### Description
Enable creating dedicated build for on device training. With this PR we
can build a lean binary for on device training using flag
--enable_training_apis. This binary includes only the essentials like
training ops, optimizers etc and NOT features like Aten fallback,
strided tensors, gradient builders etc . This binary also removes all
the deprecated components like training::TrainingSession and OrtTrainer
etc
### Motivation and Context
This enables our partners to create a lean binary for on device
training.
…threadpools' options of The Env.
### Description
<!-- Describe your changes. -->
add a c++ class ThreadingOptions, wraps OrtThreadingOptions
as I described in issue #13710
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
close#13710
Co-authored-by: zengxiangneng <zengxiangneng@360.cn>
### Description
- Adds a new C API `OrtApi::RegisterCustomOpsLibrary_V2` that manages
the lifetime of dynamic library handles (i.e., calls `dlclose` or
`FreeLibrary`).
- Deprecates C API `OrtApi::RegisterCustomOpsLibrary`.
- Adds C++ API wrapper for convenient registering of custom op
libraries.
- `PySessionOptions` is now an alias of `OrtSessionOptions`
### Motivation and Context
The current API for registering custom op libraries loads dynamic
libraries but requires users to handle the release of the corresponding
library handles. Additionally, the user has to make sure to release the
library handle _after_ the session has been destroyed (or the program
segfaults).
The new API automatically cleans up the library and allows the user to
write more straightforward code.
### Description
This PR is to address follow-up comments for the multi-stream pr
https://github.com/microsoft/onnxruntime/pull/13495
Changes including:
- Make StreamAwareArena transparent to minimal build
- Make DeviceStreamCollection transparent to minimal build
- Replace ORT_MUST_USE_RESULT with [[nodiscard]]
- Remove unnecessary shared_ptr
### Motivation and Context
This PR is to address follow-up comments for the multi-stream pr
https://github.com/microsoft/onnxruntime/pull/13495
Co-authored-by: Lei Cao <leca@microsoft.com>
Implement CloudEP for hybrid inferencing.
The PR introduces zero new API, customers could configure session and
run options to do inferencing with Azure [triton
endpoint.](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-deploy-with-triton?tabs=azure-cli%2Cendpoint)
Sample configuration in python be like:
```
sess_opt.add_session_config_entry('cloud.endpoint_type', 'triton');
sess_opt.add_session_config_entry('cloud.uri', 'https://cloud.com');
sess_opt.add_session_config_entry('cloud.model_name', 'detection2');
sess_opt.add_session_config_entry('cloud.model_version', '7'); // optional, default 1
sess_opt.add_session_config_entry('cloud.verbose', '1'); // optional, default '0', meaning no verbose
...
run_opt.add_run_config_entry('use_cloud', '1') # 0 for local inferencing, 1 for cloud endpoint.
run_opt.add_run_config_entry('cloud.auth_key', '...')
...
sess.run(None, {'input':input_}, run_opt)
```
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
Adds support for variadic inputs and outputs to custom operators.
### Motivation and Context
Needed for custom ops that wrap external runtimes/models and maybe TensorRT plugins.
### Description
Update absl to a new version
### Motivation and Context
The new version contains fixes that are needed for Nvidia GPU build.
Once we update it to that version, we don't need to maintain our private
patches for Nvidia GPU build.
### Description
Add the ability to run graph
### Motivation and Context
A brief description is as follows:
1) If the whole graph is supported, then will be processed by the graph
engine, directly.
2) If the whole graph is not supported, the whole graph will be divided
into subgraphs and single operators; The sub-graphs will be run on graph
engine, and the single operators will fallback to the traditional mode.
**Description**: This PR including following works:
1. provide stream and related synchronization abstractions in
onnxruntime.
2. enhance onnxruntime's execution planner / executor / memory arena to
support execute multiple streams in parallel.
3. deprecate the parallel executor for cpu.
4. deprecate the Fence mechanism.
5. update the cuda / tensorrt EP to support the stream mechanism,
support running different request in different cuda stream.
**Motivation and Context**
- Why is this change required?
currently, the execution plan is just a linear list of those primitives,
ort will execute them step by step. For any given graph, ORT will
serialize it to a fixed execution order. This sequential execution
design simplifies most scenarios, but it has the following limitations:
1. it is difficult to enable inter-node parallelization, we have a
half-baked parallel executor but it is very difficult to make it work
with GPU.
2. The fence mechanism can work with single gpu stream + cpu thread
case, but when extend to multiple stream, it is difficult to manage the
cross GPU stream synchronizations.
3. our cuda EP rely on the BFCArena to make the memory management work
with the GPU async kernels, but current BFCArena is not aware of the
streams, so it doesn't behavior correctly when run with multiple
streams.
This PR enhance our existing execution plan and executor to support
multiple stream execution. we use an unified algorithm to mange both
single stream and multiple stream scenarios.
This PR mainly focus on the infrastructure support for multiple stream
execution, that is said, given a valid stream assignment, onnxruntime
can execute it correctly. How to generate a good stream assignment for a
given model will be in the future PR.
Co-authored-by: Cheng Tang <chenta@microsoft.com@orttrainingdev9.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Cheng Tang <chenta@microsoft.com>
Co-authored-by: RandySheriffH <48490400+RandySheriffH@users.noreply.github.com>
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
Co-authored-by: cao lei <jslhcl@gmail.com>
Co-authored-by: Lei Cao <leca@microsoft.com>
The float16.h header is shared between the CPU and ROCm EPs. The
USE_ROCM macro is defined universally, but for the float16.h header we
only wish to detect the hip-clang compiler. Otherwise, the CPU EP fails
to build because of -Werror -Wuninitialized caused by the USE_ROCM code
additions, and the CPU EP should be using a different code path.
### Description
To pass session_options to Xnnpack EP via
`XnnpackProviderFactoryCreator` for Initializing xnnpack's threadpool.
If you want to use different threadpool size or even disable xnnpack's
threadpool, just setting intra_threadpool to 1 by xnnpack EP's
provider_options.
### Motivation and Context
Co-authored-by: Guangyun Han <guangyunhan@microsoft.com>
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
### Description
The existing CUDA profiler is neither session-aware, nor thread-safe.
This PR ensures both.
### Motivation and Context
[PR 13549](https://github.com/microsoft/onnxruntime/pull/13549) brought
thread-safety and session-awareness to the ROCm profiler. This PR brings
the same goodness to the CUDA profiler as well.
Sample outputs of a profiling run from the StableDiffusion model (this
model was chosen because it requires orchestration of multiple sessions,
and verifies that the profilers are now indeed session-aware) on both
CUDA and ROCm EPs are attached, along with a script that checks that the
trace files generated by the profile are well-formed.
Update 11/29: Updated the profile outputs. The older profile outputs
exhibited an issue where some timestamps were wildly out of range,
leading to problems visualizing the traces. The bug has been fixed and
the profile outputs have been updated, along with an update to the check
script to ensure that timestamps are monotonically increasing.
[sd_profile_outputs_cuda.tar.gz](https://github.com/microsoft/onnxruntime/files/10118088/sd_profile_outputs_cuda.tar.gz)
[sd_profile_outputs_rocm.tar.gz](https://github.com/microsoft/onnxruntime/files/10118089/sd_profile_outputs_rocm.tar.gz)
[check_profile_output_well_formedness.zip](https://github.com/microsoft/onnxruntime/files/10118090/check_profile_output_well_formedness.zip)
Co-authored-by: Abhishek Udupa <abhishek.udupa@microsoft.com>
### Description
Decouple strided tensor support from ENABLE_TRAINING
### Motivation and Context
This is step 1 for creating a dedicated build for on device training.
Intention is
1. We can set ENABLE_STRIDED_TENSORS in cmake when either
ENABLE_TRAINING or ENABLE_TRAINING_ON_DEVICE is selected, this way we
dont have to use if defined(ENABLE_TRAINING) ||
defined(ENABLE_TRAINING_ON_DEVICE ) everywhere in the code.
2. This also paves the way to easily enable strided tensor support for
inference in future (if required).
Accuracy loss is observed when transformer models such as BERT, DeBERTa,
ViT are running in TRT FP16 mode. The cause is that overflow happens at
Pow op in layer norm.
This PR provides the option to force Pow to run in TRT FP32 precision if
overflow occurs.
Co-authored-by: Ubuntu <azureuser@orteplinuxdev.bxgbzpva45kedp3rhbsbit4phb.jx.internal.cloudapp.net>
Right now we fix the warnings in an ad-hoc way. We run static analysis
in nightly builds, then create work items for the finding it found. Our
CI build pipelines run the same scan but do not break the build. So,
this PR will fix the remaining findings in the CPU EP(including the
training part) and enforce the check. Later on we can continue to expand
the scope.
We still have some warnings left in the JNI part. I will try to address
them later in the next month.
### Description
The existing ROCM profiler has a few shortcomings, which this PR fixes.
### Motivation and Context
The existing ROCM profiler:
1. Is not thread-safe
2. Is not session-aware: i.e., if multiple inference sessions enable
profiling, then events (esp GPU events) get mixed up between the
sessions
3. Has some issues with respect to coding standards.
This PR addresses all of the above by cleanly re-implementing parts of
the ROCM profiler as required.
Attached are 4 profile outputs from a multi-session run of the
StableDiffusion model, as well as a quick-and-dirty script that checks
the profile outputs for the invariants claimed.
[sd_profile_outputs.tar.gz](https://github.com/microsoft/onnxruntime/files/9924608/sd_profile_outputs.tar.gz)
[check_profile_output_wellformedness.zip](https://github.com/microsoft/onnxruntime/files/9924614/check_profile_output_wellformedness.zip)
Co-authored-by: Abhishek Udupa <abhishek.udupa@microsoft.com>
The old runtime optimization format is not readily convertible to the new one without extra information for translating kernel def hashes.
Ignore such saved runtime optimizations and output a warning for now.
### Description
* Add getter/setter to access and update C# OrtEnv log level
* Add C API about updating ort env with custom log level to support the
setter above (Following [pybind
implementation](952c99304a/onnxruntime/python/onnxruntime_pybind_state.cc (L923-L924)))
* Add test case to verify getter & setter
### Motivation and Context
* For C++/Python, the log level can be adjusted via OrtEnv, and this
feature is missing in C# binding
**Description**: Subgraph-level recompute
This PR adds an optional capability trading additional re-computation
for better memory efficiency. Specifically, a pre-defined operator list
used to iterate the Graph to find some subgraphs for recompute, to
reduce some stashed activations whose lifetime across forward and
backward pass.
When training with ORTModule, by default, the graph transformer will
scan the execution graph to find all eligible subgraph to recompute,
along with sizes that can save. An example looks like below.
If we want to enable some of them to recompute, we can define env
variable this way:
`export
ORTMODULE_ENABLE_MEMORY_ALLEVIATION="Mul+FusedMatMul+Cast+Unsqueeze+Unsqueeze+Cast+Sub+Mul+Add+BiasSoftmaxDropout+Cast+:1:-1,BiasGelu+:1:-1,BitmaskDropout+Cast+:1:-1,FusedMatMul+:1:-1,Cast+:1:-1,Mul+Add+:1:-1,Mul+Sub+:1:-1"`
```
[1,0]<stderr>:2,022-10-12 14:47:39.302,954,530 [W:onnxruntime:, memory_alleviation.cc:595 PrintSummary]
[1,0]<stderr>:MemoryAlleviation Summary:
[1,0]<stderr>: User config:
[1,0]<stderr>: Mul+FusedMatMul+Cast+Unsqueeze+Unsqueeze+Cast+Sub+Mul+Add+BiasSoftmaxDropout+Cast+:1,BiasGelu+:1,BitmaskDropout+Cast+:1,FusedMatMul+:1,Cast+:1,Mul+Add+:1,Mul+Sub+:1
[1,0]<stderr>: =================================
[1,0]<stderr>: Subgraph: BitmaskDropout+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 1,024 x Frequency:1
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: BiasGelu+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x input_ids_dim1 x 4,096 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Reshape[1,0]<stderr>:+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:labels_dim0 x Frequency:1
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Unsqueeze+Unsqueeze+Cast+Sub+Mul+Mul+FusedMatMul+Cast+Add+BiasSoftmaxDropout+Cast+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x input_ids_dim1 x Frequency:23
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Mul+FusedMatMul+Cast+Unsqueeze+Unsqueeze+Cast+Sub+Mul+Add+BiasSoftmaxDropout+Cast+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x input_ids_dim1 x Frequency:1
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Mul+Add+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x 1 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: FusedMatMul+Cast+Add+Reshape+Cast+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x 2 x 4 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Mul+Sub+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x 1 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Cast+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:1,024 x 1,024 x Frequency:97
[1,0]<stderr>: PatternShape:3 x 1,024 x Frequency:1
[1,0]<stderr>: PatternShape:8 x 64 x Frequency:24
[1,0]<stderr>: PatternShape:1,024 x 4,096 x Frequency:24
[1,0]<stderr>: PatternShape:4,096 x Frequency:24
[1,0]<stderr>: PatternShape:4,096 x 1,024 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: FusedMatMul+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x input_ids_dim1 x 4,096 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: =================================
```
"Type config:" whether recompute is enabled by users. 0 - disable, 1-
enable.
"Subgraph" means what kind of subgraph will be recomputed, in this case,
it is a single node "Gelu", and it will be "Recompute".
"Shape && Frequency" means, for this recompute, one tensor of size
(batch size, 500) will be saved because it will be recomputed.
**Baseline**
On a 1P model (DEBERTA V2), sequence length 256, training with 16 A100
GPUs. With latest main branch, we can run batch size 16, and the maximum
batch size < 32. So 16 is usually chosen by data scientists. 65% of 40GB
memory is used during training. The SamplesPerSec=479.2543353561354.

**With this PR**
Gelu is recomputed for saving memory peak, batch size 32 can be run. The
97% of 40GB A100 is used, the SamplesPerSec=562.041593991271 (**1.17X**
of baseline).

**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
This PR enables ORT to execute graphs captured by TorchDynamo. Major compilation code is in `OrtBackend.compile` in ort_backend.py. `register_backend.py` is for plugging `OrtBackend` into TorchDynamo as a compiler.
- Reverts change to CustomOpApi::GetTensorData introduced by commit 5dae0c477d,
which causes infinite recursion.
- Moves EndsProfilingAllocated to non-const session implementation
(C++ API header).
### Description
<!-- Describe your changes. -->
The Env argument does not need to be mutable to call the underlying C
API. Update the Ort::Session ctor to have a const Env.
All other changes are from clang-format running.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Cleanup
### Description
Detect and report thread creation failure on Windows.
Do not throw out of constructor after the thread is created,
the thread handle is lost and cannot be joined, resulting in a deadlock.
Make setting a thread priority on Linux consistent with windows.
Set thread priority in the thread itself. Log failure properly,
but do not exit the thread.
### Motivation and Context
Address issues https://github.com/microsoft/onnxruntime/issues/13291
And
https://github.com/microsoft/onnxruntime/issues/13285#issuecomment-1278063223
clang-tidy says "Do not implicitly decay an array into a pointer; consider using gsl::array_view or an explicit cast instead"
It is a false positive scattering around all our codebase when using
helper macros. It is becuase for function with 4 char name, say `main`,
the type of __FUNCTION__ and __PRETTY_FUNCTION__ is `char [5]`.
### Description
Deprecate CustomOpApi and refactor dependencies for exception safety and
eliminate memory leaks.
Refactor API classes for clear ownership and semantics.
Introduce `InitProviderOrtApi()`
### Motivation and Context
Make public API better and safer.
Special note about `Ort::Unowned`. The class suffers from the following
problems:
1. It is not able to hold const pointers to the underlying C objects.
This forces users to `const_cast` and circumvent constness of the
returned object. The user is now able to call mutating interfaces on the
object which violates invariants and may be a thread-safety issue. It
also enables to take ownership of the pointer and destroy it
unintentionally (see examples below).
2. The objects that are unowned cannot be copied and that makes coding
inconvenient and at times unsafe.
3. It directly inherits from the type it `unowns`.
All of the above creates great conditions for inadvertent unowned object
mutations and destructions. Consider the following examples of object
slicing, one of them is from a real customer issue and the other one I
accidentally coded myself (and I am supposed to know how this works).
None of the below can be solved by aftermarket patches and can be hard
to diagnose.
#### Example 1 slicing of argument
```cpp
void SlicingOnArgument(Ort::Value& value) {
// This will take possession of the input and if the argument
// is Ort::Unowned<Ort::Value> it would again double free the ptr
// regardless if it was const or not since we cast it away.
Ort::Value output_values[] = {std::move(value)};
}
void main() {
const OrtValue* ptr = nullptr; // some value does not matter
Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)};
// onowned is destroyed when the call returns.
SlicingOnArgument(unowned);
}
```
#### Example 2 slicing of return value
```cpp
// The return will be sliced to Ort::Value that would own and relase (double free the ptr)
Ort::Value SlicingOnReturn() {
const OrtValue* ptr = nullptr; // some value does not matter
Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)};
return unowned;
}
```
**Description**: This PR adds Ascend CANN execution provider support.
**Motivation and Context**
- Why is this change required? What problem does it solve?
As the info shown in the issue. CANN is the API layer for Ascend
processor. Add CANN EP can allow user run onnx model on Ascend hardware
via onnxruntime
The detail change:
1. Added CANN EP framework.
2. Added the basic operators to support ResNet and VGG model.
3. Added C/C++、Python API support
- If it fixes an open issue, please link to the issue here.
https://github.com/microsoft/onnxruntime/issues/11477
Author:
lijiawei <lijiawei19@huawei.com>
wangxiyuan <wangxiyuan1007@gmail.com>
Co-authored-by: FFrog <ljw1101.vip@gmail.com>
This changes are to align OV 2022.2 Release with ORT . Changes
CPU FP16 Support, dGPU Support, RHEL Dockerfile, Ubuntu 20 Dockerfile
**Motivation and Context**
- This change is required to ensure ORT-OpenVINO Execution Provider is
aligned with latest changes.
- If it fixes an open issue, please link to the issue here.
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: shamaksx <shamax.kshirsagar@intel.com>
Co-authored-by: pratiksha <pratikshax.bapusaheb.vanse@intel.com>
Co-authored-by: pratiksha <mohsinx.mohammad@intel.com>
Co-authored-by: Sahar Fatima <sfatima.3001@gmail.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
Co-authored-by: nmaajidk <n.maajid.khan@intel.com>
Co-authored-by: Mateusz Tabaka <mateusz.tabaka@intel.com>
Co-authored-by: intel <intel@iotgecsp-nuc04.iind.intel.com>
# Motivation
Currently, ORT minimal builds use kernel def hashes to map from nodes to
kernels to execute when loading the model. As the kernel def hashes must
be known ahead of time, this works for statically registered kernels.
This works well for the CPU EP.
For this approach to work, the kernel def hashes must also be known at
ORT format model conversion time, which means the EP with statically
registered kernels must also be enabled then. This is not an issue for
the always-available CPU EP. However, we do not want to require that any
EP which statically registers kernels is always available too.
Consequently, we explore another approach to match nodes to kernels that
does not rely on kernel def hashes. An added benefit of this is the
possibility of moving away from kernel def hashes completely, which
would eliminate the maintenance burden of keeping the hashes stable.
# Approach
In a full build, ORT uses some information from the ONNX op schema to
match a node to a kernel. We want to avoid including the ONNX op schema
in a minimal build to reduce binary size. Essentially, we take the
necessary information from the ONNX op schema and make it available in a
minimal build.
We decouple the ONNX op schema from the kernel matching logic. The
kernel matching logic instead relies on per-op information which can
either be obtained from the ONNX op schema or another source.
This per-op information must be available in a minimal build when there
are no ONNX op schemas. We put it in the ORT format model.
Existing uses of kernel def hashes to look up kernels are replaced
with the updated kernel matching logic. We no longer store
kernel def hashes in the ORT format model’s session state and runtime
optimization representations. We no longer keep the logic to
generate and ensure stability of kernel def hashes.
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
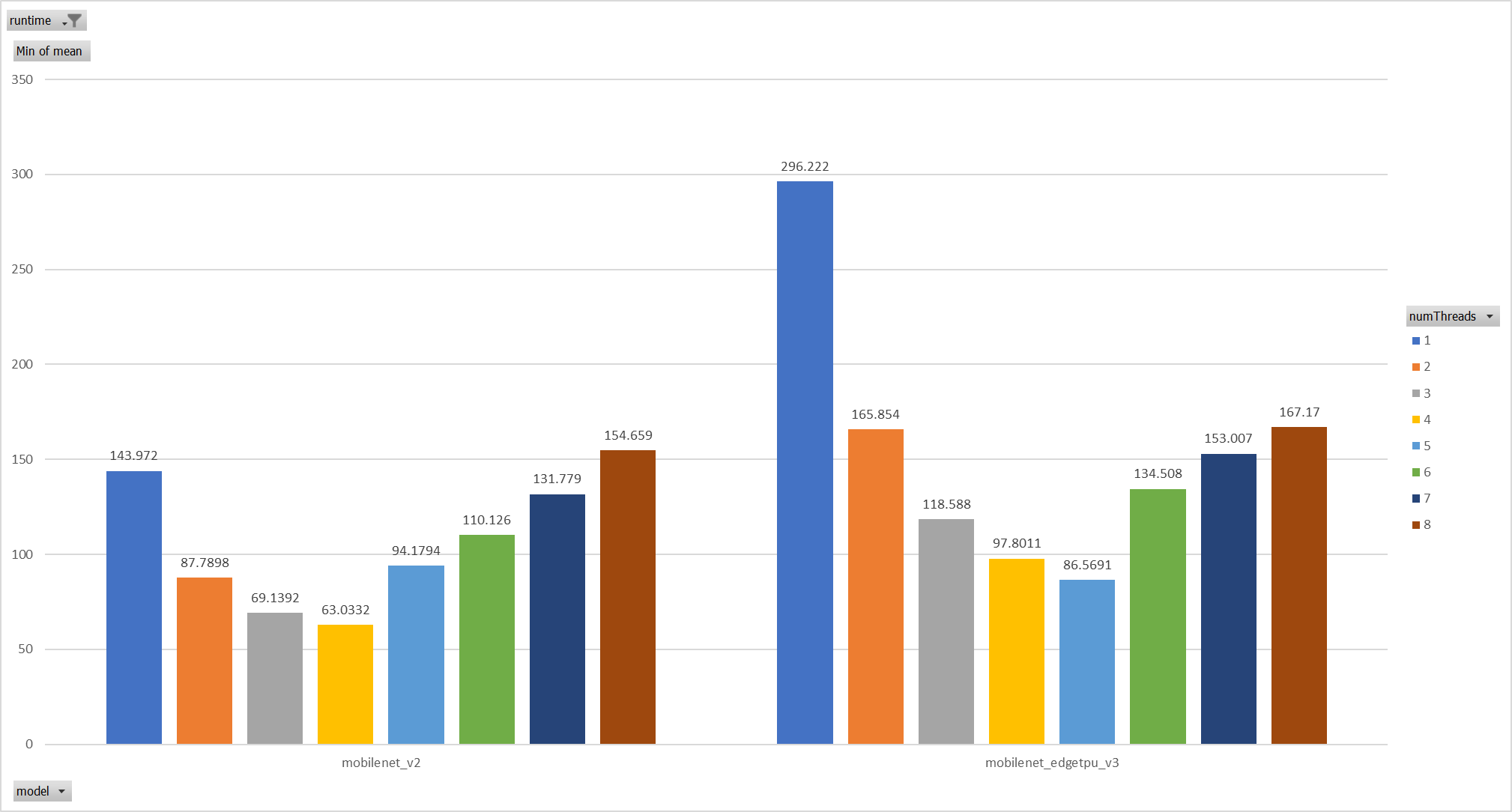
Case 2:
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
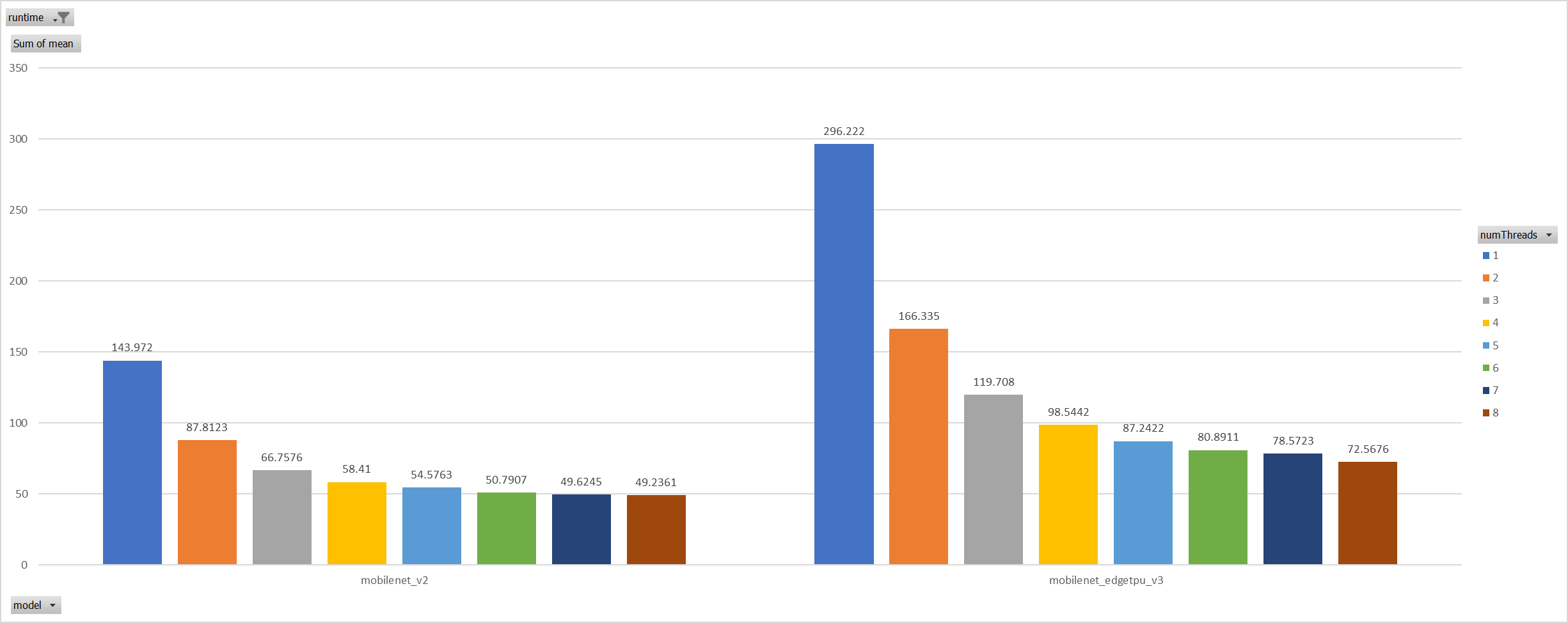
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
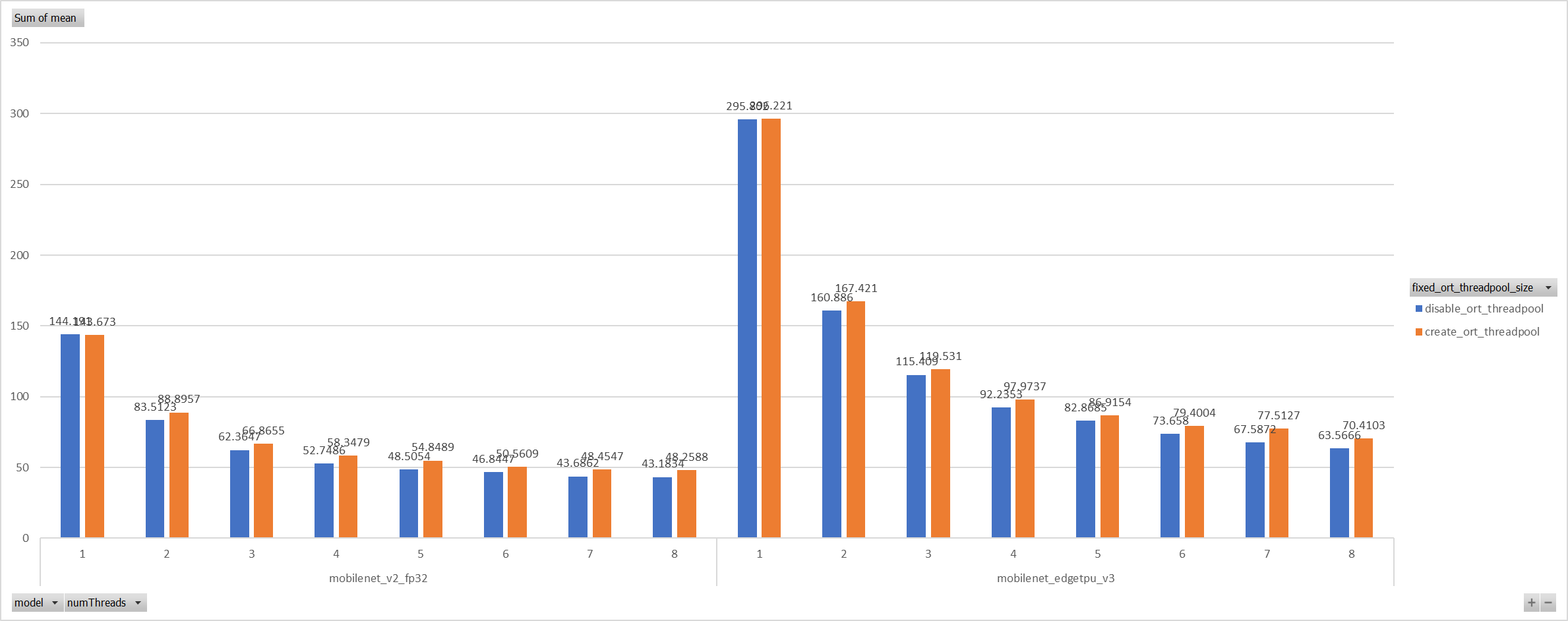
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
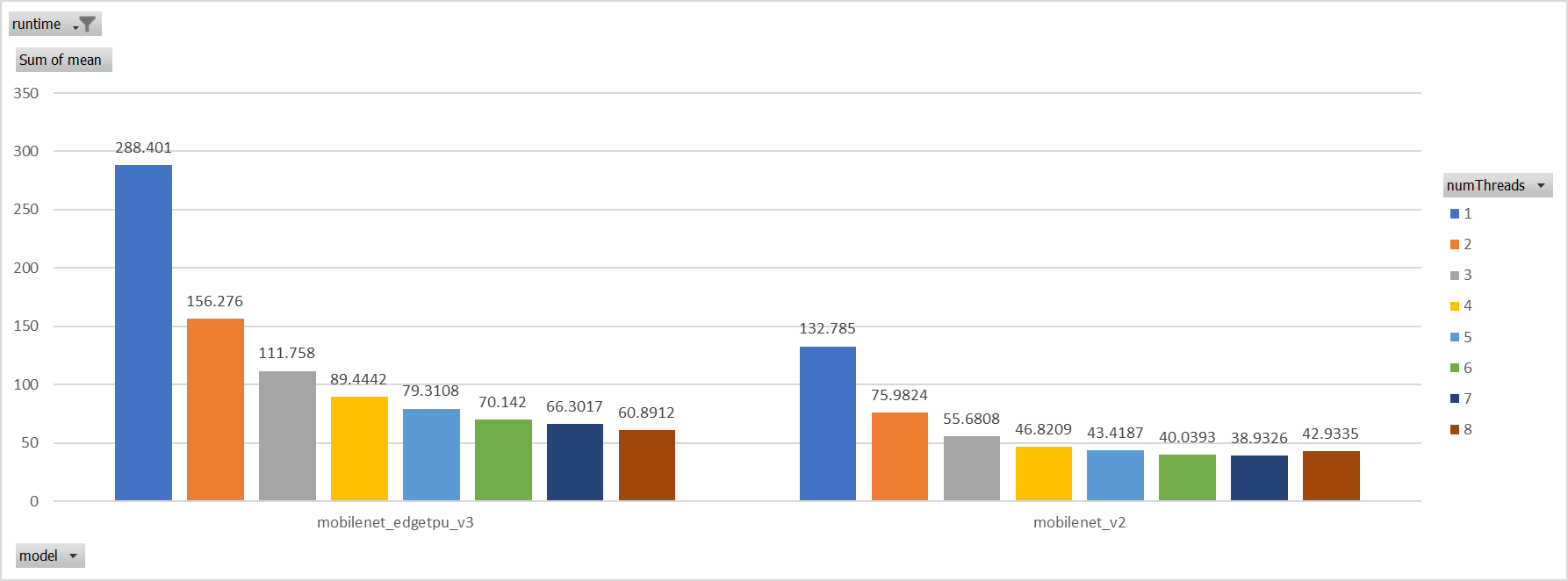
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
* upgrade emsdk to 3.1.19
* fix build break
* ignore '-Wunused-but-set-variable' in eigen
* add malloc and free in exported functions
* EXPORTED_FUNCTIONS
* Add first pass of rocm kernel profiler
* Clean up rocm_profiler. Format args. Demangle kernel names.
Add Api EventRecords
* Remove debug output
* Temporarily disable profiling unit test 'api record check' for cupti
* Fix compile error for non-gpu builds
* Use common file for demangle and pid/tid. Namespace ThreadUtil. Fix gpu buffer clearing.
* Merge demangle into profiler_common
* Merge demangle into profiler_common part 2
* Style cleanup
* Resolve linking issues via ProviderHost interface
* Demangle cuda kernel names
* Clean up comments
* Fix formatting
* Fix anal retentive formatting
LLVM compiler complains the std::hash<const char*> and suggests std::hash<const void*>. But the intention is to hash the name string instead of the pointer. So use std::hash<std::string> to be explicit.
* Add ability to use ORT format model flatbuffer directly for intiializers by leveraging the TensorProto external data infrastructure.
Requires user to provide ORT format model bytes when creating the session, and set both `session.use_ort_model_bytes_directly` and `session.use_ort_model_bytes_for_initializers` to 1 in SessionOptions config entries (AddSessionConfigEntry in C API).
Add a graph optimization that convert u8s8 matrix multiplication to u8u8 if needed
In x86/64 platforms, specifically SSE4.1, AVX2 and AVX512 CPUs provide better performance computing u8s8 matrix multiplications. Unfortunately, the higher performance comes with value overflow problems, as described in:
https://www.intel.com/content/www/us/en/develop/documentation/onednn-developer-guide-and-reference/top/advanced-topics/nuances-of-int8-computations.html
In this change we added a session option "session.x64quantprecision" (default off). For operators that calls u8s8 matrix multiplications, e.g. QAttention, we convert them to u8u8 when the following conditions are all satisfied:
1. Current CPU is SSE4.1, AVX2 or AVX512 with no VNNI support
2. Session option "session.x64quantprecision" is on.
3. Constant weight tensor contains values outside of [-64, 63] range
Note that when weight tensor is not constant, QDQS8ToU8Transformer should already convert it to u8.
* create op from ep
* read input count from context
* create holder to host nodes
* fix typo
* cast type before comparison
* throw error on API fail
* silence warning from minimal build
* switch to unique_ptr with deleter to host nodes
* fix typo
* fix build err for minimal
* fix build err for minimal
* add UT for conv
* enable test on CUDA
* add comment
* fix typo
* use gsl::span and string view for Node constructor
* Added two APIs - CopyKernelInfo and ReleaseKernelInfo
* pass gsl::span by value
* switch to span<NodeArg* const> to allow for reference to const containers
* fix typo
* fix reduced build err
* fix reduced build err
* refactoring node construction logic
* rename exceptions
* add input and output count as arguments for op creation
* refactor static member
* use ORT_CATCH instead of catch
* cancel try catch
* add static value name map
* format input definition and set err code
* fix comments
* fix typo
* Revert "Revert "Refactor ExecutionFrame and SessionState to reduce memory all… (#11888)"
This reverts commit d2cbae3a04.
* Revert prepacked_weights to avoid indirect inclusion in CUDA and TRT code that breaks the build.
Minor wording update to warning message to clarify that the function style Compile API is deprecated now and will be removed soon.
Also updated some code comments.
* Rework the EP factory creation setup so we're not cut-and-pasting function declarations in multiple places.
Convert append EP for SNPE to be generic, and also use for XNNPACK.
Add XNNPACK to C# API
* Don't need stub for MIGraphX as it's using provider bridge.
* Remove old 'create' functions that aren't applicable now that the EPs are built as separate libraries.
* Only use EPs that require the layout transform if the opset is supported by the layout transformer.
* Update wasm registration of xnnpack.
* C API version 0.001
* fix linker issues
* fixes for save checkpoint api
* plus fixes based on tests
* plus test_runner and other changes
* Plus cosmetic updates
* remove unnecessary headers
* plus some updates
* plus more changes
Co-authored-by: Ashwini Khade <askhade@microsoft.com@orttrainingdev10.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
* Reserve the first core for the main thread
Currently in "auto affinity" mode the worker threads are affinized to cores 0..(N-1), leaving the very last core for the main thread. This patch preserves core #0 for the main thread, and affinizes the worker threads to cores 1..N.
* Avoid unneeded spin_pause in thread pool's worker threads
Remove unneeded PAUSE instruction (0.1-0.2 usec latency) after a worker thread finds a task to execute.
* MLAS/x86: optimize QLinearConv on hybrid CPUs
Existing 4x task granularity for task partitioning on hybrid CPUs is
not sufficient to compensate the difference of VNNI instructions
throughput
between performance and efficient cores. This patch...
* Increases granularity for QLinearConv by 2x, to have 2x more tasks
with 2x
smaller output count
* Limits QLinearConv task count from above, to avoid output count per
task
getting smaller than kernel's capability
* Remove hardcoded task count for QLineConv as it limited scaling on
16+ cores CPUs
* MLAS/x86: optimize QLinearConv on hybrid CPUs
Existing 4x task granularity for task partitioning on hybrid CPUs is not sufficient to compensate the difference of VNNI instructions
throughput between performance and efficient cores. This patch...
* Increases granularity for QLinearConv by 2x, to have 2x more tasks
with 2x smaller output count
* Limits QLinearConv task count from above, to avoid output count per
task getting smaller than kernel's capability
* Remove hardcoded task count for QLineConv as it limited scaling on
16+ cores CP
* Addressing comments
* combining x86 ARM branches in qlinearconv threaded job partition
* revert first core assignment
Co-authored-by: Saurabh <saurabh.tangri@intel.com>
Co-authored-by: Chen Fu <fuchen@microsoft.com>
* aten op for inference
* fix build error
* more some code to training only
* remove domain from operator name
* move aten_op_executor ext out from ortmodule
* add pipeline
* add exec mode
* fix script
* fix ut script
* fix test pipeline
* failure test
* rollback
* bugfix
* resolve comments
* enable aten for python build only
* fix win build
* use target_compile_definitions
* support io binding
* turn off aten by default
* fix ut
Co-authored-by: Vincent Wang <weicwang@microsoft.com>
Co-authored-by: zhijxu <zhijxu@microsoft.com>
* Rework allocator sharing to work for multiple devices.
* Update SessionState to not use allocator name in matching for consistency with IExecutionProvider. The name doesn't have any clear meaning (e.g. we use the same name for the per-thread allocator in the CUDA EP as the shared allocate there and in the TRT EP).
* NOTE: this means we will have one allocator per OrtMemType+OrtDevice.
* Reverse order when doing allocator setup in SessionState. This will result in the CPU and CUDA EPs allocators being preferred (they are the most configurable), and also means the per-thread CUDA allocator for default GPU memory will be used even when TRT is enabled.
* NOTE: Combined with the change to remove the allocator name from the key this will mean that if CUDA and TRT or ROCM and MIGraphX are both enabled the CUDA/ROCM per-thread allocator will be used to allocate GPU memory.
* Use InsertAllocator instead of TryInsertAllocator. Each EP should be registered once, and we should only enter RegisterAllocator once, so the 'try' should not be required and would indicate an unexpected setup was involved. i.e. better to fail and figure out if we need to support that setup.
* Add some clarifying comments around how replace allocator works.
* Add unit testing for setup where EP has local allocator that may get out of sync with values in the IExecutionProvider base class.
* Fix invalid check of whether data is on CPU to use device info instead of allocator name.
This reverts commit 1f2c926. Because it makes our packaging pipeline crash
Error message:
[ RUN ] QLinearConvTest.Conv3D_S8S8_Depthwise
Test #1: onnxruntime_test_all ...................Subprocess killed***Exception: 838.24 sec
We haven't successfully reproduced the bug on a real ARM64 hardware. Currently we only saw it showed up with qemu. More investigations are on-going.
* Initiate Ort SNPE EP
* fix snpe ep windows build which is caused by the utility method (ToUTF8String) name change on master
* correct the source path for libonnxruntime.so while building for andorid package
* add AdditionalDependencies for amr64
* On MS-Windows, the patchfile must be a text file, i.e. CR-LF must be used as line endings. A file with LF may give the error: "Assertion failed, hunk, file patch.c, line 343," unless the option '--binary' is given.
* fix build failure if snpe is not enabled
* update doc for contrib op
* separate out snpe ep settings to onnxruntime_snpe_provider.cmake
* renaming according review comments
* update according review comments
* Implement XNNPACK support via an EP.
* Layout transform uses the GraphPartitioner infrastructure.
* Node fusion is supported.
* Conv and MaxPool implementations were ported from Changming's PR.
* Added optional mutex in InferenceSession::Run as we only want to allow sequential calls if xnnpack is enabled
* use the lightweight compile api as default; use dnnl ep for testing
* apply to tensorrt ep
* fix the missing files
* fix build
* fix the copy issue on linux
* migrate migraphx and openvino ep
* fix openvino build break
* fix linux build
* fix unused parameter
* fix coreml build
* use graph view's filtered initializers
* fix openvino break
* fix tvm compile api
* fix tvm / rknpu / vitisai ep build
* add IsInitializedTensor in graph_viewer; fix nuphar build
* use serializer directly as tvm ep is still static lib
* fix the type mismatch
* fix the type mismatch
* fix merge conflict
* add a comment
* fix minimal build
* fix the DML EP's legacy approach
* save type/shape in dnnl IR
* fix linux break
* fix tvm failure
* dnnl ep: move initializer referenced out of dnnl subgraph
* Revert "add IsInitializedTensor in graph_viewer; fix nuphar build"
This reverts commit 1cc3c7f08c16fee4fe3309a67209eb769d479587.
* add IsInitializedTensor to graph viewer
* add the legacy code for nuphar build to temporarily make nuphar build work
* ignore internal test for nuphar
* remove the out of date tests
* keep the legacy API in EP for a while
* turn serializer into a static function
* update comments
* fix tvm build
* Update include/onnxruntime/core/framework/execution_provider.h
Co-authored-by: Pranav Sharma <prs@microsoft.com>
* Update include/onnxruntime/core/framework/execution_provider.h
Co-authored-by: Pranav Sharma <prs@microsoft.com>
* Update onnxruntime/core/framework/execution_provider.cc
Co-authored-by: Pranav Sharma <prs@microsoft.com>
* updatee comments; add warning message for legacy compil call
* add a flag to control out of scope arg in serialization
* fix trt build; improve the test
* resolve merege errors
* fix a typo
Co-authored-by: Cheng Tang <chenta@microsoft.com>
Co-authored-by: Cheng Tang <chenta@microsoft.com@orttrainingdev9.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Pranav Sharma <prs@microsoft.com>
* draft kernel creation
* setup eager context
* call into kernel in eager mode
* redefine test case
* refact eager context
* add comment
* remove header
* rename argument
* redefine API definition with types
* list outputs as argument
* switch to int to represent length
* fix compile err
* create attribute API
* add test case for topk
* remove bool from c api
* add gru test case
* remove var
* fix compile warnings
* rename status
* fix compile err
* exclude sparse tensor
* fix comments
* fix comments
* fix build err
* rename file and move location
* format code
* move file to session folder
* fix comments
Co-authored-by: Randy <Randy@randysmac.attlocal.net>
This reverts commit 4983d6e5d6. We can't destroy OrtEnv through python's atexit function, because at that time there might be many other ORT python objects alive.
* initial fix
* refactor the function handle
* update the implementation
* fix linux build break
* fix training build
* fix minmal build
* fix gradient checker
* deprecate the local function members in graph. host it in model
* fix changming's comments
* fix comments about inlined containers
* fix a missed inlined container
* fix training build
* avoid const for std string_view
Co-authored-by: Cheng Tang <chenta@microsoft.com>
Prior to this, certain shape and type errors were surfaced only when
the model was using the latest known op set version.
Providing users an explicit option allows for better testing of code
that produces models, which includes unit tests within this repo and
other repos such as the TF-ONNX and PT-ONNX converters.
Remove the previous behavior which seems quite counter-intuitive:
an otherwise identical model with a later op set version should be treated
identically in this regard.
The option defaults to false to avoid causing errors for users that
rely on the previous permissive behavior.
Turned on the strict enforcement by default in OpTester, which revealed a few
disagreements between ORT and ONNX on what the correct output shape should
be.
Fix shape inference bug in ReduceSumTraining with noop_with_empty_axes=1
which was revealed.
Fix TensorOpTest.Unsqueeze_scalar, which was testing negative axes on an
op set version where the op did not actually support negative axes.
Fixes#9506.
Rework initializer.cc to eliminate code duplication and add type enforcement.
Address review comments. Add literal operators for MLFloat16 abd BFloat16 and tests.
I disabled some tests temporarily. I will move them to a separated executable file in another PR.
In the future, I want to combine onnxruntime::Environment and OrtEnv classes. Now we have 3 env classes, it is too confusing:
1. onnxruntime::Env
2. onnxruntime::Environment
3. OrtEnv
Our python binding uses onnxruntime::Environment, while all other language bindings use OrtEnv. So python doesn't unload EPs but the others do. It's better to make them consistent.
Please note even I added the call, currently the unload function still is a no-op on Linux. So, currently on Windows we must unload the EPs while on Linux we must not do it.
* Enabling ov-ep for 2022.1 Release
->Added ov-ep 2022.1 flow
->Validated CPU Unit tests with OV
Master using onnxruntime_test_all unit
tests.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fix for output mismatch b/w OpenVINO and ONNX
Refer:
https://jira.devtools.intel.com/browse/CVS-60310
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enabling Adobe ops
->Enable Resize op for iGPU
->Enable Add op for iGPU
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Removing irrelevant conditions
->Removing some conditions from
GetCapability() which are now not
required. (Removed conditions for
OV version support less than 2021.2)
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enable upsample op
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enable Adobe proxy-e model
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Removing any extra conditions for Opset13 ops
* Opset13 changes
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Exception handling for devices
* Added comments
* Implement GPU Throttling feature
*Added GPU Throttling feature for iGPU's.
when user enables it as a runtime option,
it helps in reducing overall CPU usage
of the application
*Added changes to exercise this option
using onnxruntime_perf_test application.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Renaming the runtime config option
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added the user to video and users group
* Handling_GPU.0_GPU.1
* Handling special conditions
->Handling corner cases for
device_type checks
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Modification to include new api 2.0 changes in the code
* Added opset13 changes
->Enabled Few ops
->Added Debug info for case 3b in getcapability()
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enabling ov-ep for 2022.1 Release
->Added ov-ep 2022.1 flow
->Validated CPU Unit tests with OV
Master using onnxruntime_test_all unit
tests.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fix for output mismatch b/w OpenVINO and ONNX
Refer:
https://jira.devtools.intel.com/browse/CVS-60310
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enabling Adobe ops
->Enable Resize op for iGPU
->Enable Add op for iGPU
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Removing irrelevant conditions
->Removing some conditions from
GetCapability() which are now not
required. (Removed conditions for
OV version support less than 2021.2)
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enable upsample op
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enable Adobe proxy-e model
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Removing any extra conditions for Opset13 ops
* Opset13 changes
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Exception handling for devices
* Added comments
* Implement GPU Throttling feature
*Added GPU Throttling feature for iGPU's.
when user enables it as a runtime option,
it helps in reducing overall CPU usage
of the application
*Added changes to exercise this option
using onnxruntime_perf_test application.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Renaming the runtime config option
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added the user to video and users group
* Handling_GPU.0_GPU.1
* Handling special conditions
->Handling corner cases for
device_type checks
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added opset13 changes
->Enabled Few ops
->Added Debug info for case 3b in getcapability()
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Log comments updated
* Changes to enable 2.0 api
* Enabling ov-ep for 2022.1 Release
->Added ov-ep 2022.1 flow
->Validated CPU Unit tests with OV
Master using onnxruntime_test_all unit
tests.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fix for output mismatch b/w OpenVINO and ONNX
Refer:
https://jira.devtools.intel.com/browse/CVS-60310
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enabling Adobe ops
->Enable Resize op for iGPU
->Enable Add op for iGPU
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Removing irrelevant conditions
->Removing some conditions from
GetCapability() which are now not
required. (Removed conditions for
OV version support less than 2021.2)
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enable upsample op
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Enable Adobe proxy-e model
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Removing any extra conditions for Opset13 ops
* Opset13 changes
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Exception handling for devices
* Added comments
* Implement GPU Throttling feature
*Added GPU Throttling feature for iGPU's.
when user enables it as a runtime option,
it helps in reducing overall CPU usage
of the application
*Added changes to exercise this option
using onnxruntime_perf_test application.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Renaming the runtime config option
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added the user to video and users group
* Handling_GPU.0_GPU.1
* Handling special conditions
->Handling corner cases for
device_type checks
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added opset13 changes
->Enabled Few ops
->Added Debug info for case 3b in getcapability()
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fix build issue
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixes issues
*Fixes compiler warnings c4458 on windows.
*Fixes the bug in device_type check logic
*Adds print info for enable_opencl_throttling
option in onnxruntime_perf_test
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* commit to make openvino_2021.4 compatible
* Fixed IO Buffer Optimization
* Fix output names issue
* Fix 2021.3 branch
* Bug Fix for Multiple inputs/outputs
- Assigns the right output_name and
input_name for the graph when
returned by CompiledModel::inputs()
OV function.
- Also takex care of output mismatch
issue b/w openvino output and onnx
output
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Add comments for the changes made
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* IO Buffer Changes
* Commit for Disabling GPU Throttling for 2021.4
* Updated branch
* Fix windows build
->Fixed windows build in debug mode
->Disabled scatternd3_tensor_int64
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixed CPP Unit tests for CPU
-Fixed shrink, MVN, ReduceL2, Maxpool,
upsample, scatter, slice, reshape,
unsqueeze.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixed first set of GPU Tests
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixed additional failing tests on GPU
->Added conditions to disable certain ops
under certain conditions
->Disabled certain tests
->Added some op supports for no_dimension
supported
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added Expand op support for CPU
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added condition for squeeze op
->Shape can't have empty axes attribute
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Add support for LessOrEqual op function
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* OV Interface wait for replaced by indefinite wait call
* use names from ONNX model to access OV tensors
This chnage is to use the input/output names
retrieved from original onnx model to access
OV tensors and to check if there's any input
or output names mismatch b/w ONNX naming
and OV naming.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixes Myriad unit tests and other issues
->Fixes Myriad CPP unit tests
->Fixes output mismatch issue with models with
sub graph partitioning
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fix segfault issue
->Fixed case 3b condition in get_capability()
which was causing the segfault issue
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixed build isuse with ov 2021.4 with I/O buffer
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Disables performance counters for I/O Buffer
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixed inputs/outputs mismatch for HDDL with 2022.1
Signed-off-by: Mohammad Amir Aqeel <mohammadx.amir.aqeel@intel.com>
* Fix to enable GPU FP16
* Enabled mlperf_ssd_mobilenet_300 model fully on CPU
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Added ov version specific dll packaging for nuget
* Fixed conditions for few ops
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Dockerfile updates
* Updated License Info
-Updated the copyrights License Info
-modified FP16 transformations with OV 2022.1
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Disabling mlperf_ssd_mobilenet_300 model
->Disabled this model for openvino. The
test is failing in Internal_CI pipelines.
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Disabling failing python CPU Tests
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Fixed flake8 python errors
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
Co-authored-by: hdgx <harinix.d.g@intel.com>
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: sfatimar <sahar.fatima@intel.com>
Co-authored-by: mohsinmx <mohsinx.mohammad@intel.com>
Co-authored-by: Mohammad Amir Aqeel <mohammadx.amir.aqeel@intel.com>
* rename info to options for TVM EP
* transfer options processing from TVMExecutionProvider to TVMEPOptions
* transfer TVMRunner to separated files
* implement TVMCompiler class
* replace CompileFunc by TVMCompiler object. update TVMRunner. now it does not depend on TvmExecutionProvider
* correct logging of TVM EP options
* RunnerImpl, GERunnerImpl and VMRunnerImpl were implemented
* add prepareComputeInfo method
* remove update_output_shapes flag
* embed all TVM EP dependences to tvm namespace. transfer model compilation from TVMRunner. connect TVMRunnerImpl to TVMRunner
* refactor compileModel method
* small cleaning
* separate TVM EP options data store and processing
* replace TvmTensorShape by InlinedVector with max_size 5
* correct indentation
* update TVM hash
Co-authored-by: Valery Chernov <valery.chernov@deelvin.com>
Add runtime optimization support to ONNX -> ORT format conversion script.
Replace `--optimization_level`, `--use_nnapi`, and `--use_coreml` with a new `--optimization_style` option.
Fix CUDA 10.2 compile error due to inlined_containers.h inclusion
into a common CUDA header.
Use NumberOfNodes() to reserve space in a hash table
Prefer separate call to reserve() rather than passing in the
hash table constructor. They have somewhat different meaning.
Add an optimizer that can remove leftover Q->DQ pairs. Depending on the model this may help with performance and/or improve accuracy. Optional as it could make things worse so user needs to be aware of this and test what works best for their scenario. Enable with SessionOptions config param `session.enable_quant_qdq_cleanup`
Hide Inlined Hash set and maps guts behind template forward declarations.
Currently CUDA 10.2 compiler can not compile abseil but provider interfaces
use those types in their signatures. InlinedVector seems to be fine.
Introduce core/common/inlined_containers_fwd.h header
Work on minimizing memory management calls by
reducing number of allocations and copies.
Replace std::unordered_set to InlinedHashSet
and add usage of InlinedVector.
Employ std::move() to minimize copying and memory allocations.
Remove copying of the const shared data into each of the
PropagateCast transformer instances.
Move inlined_containers.h header to include/common
Adjust AsSpan imlementation for C++ < 17
* add restrictions for hybrid cpus
* add unit test to mock hybrid cpu
* attach hybrid flag
* add mocking interface to CpuInfo
* make is_hybrid
* make mock function const
* add force_hybrid for thread pool
* remove header
* Add layout transformer for NNAPI
* plus merge fixes
* plus some more merge fixes
* test fixes
* comments + cleanup
* plus updates
* post merge changes
* enable layout transformer in extended minimal build
* plus more comments
* more tests + fix CI
* plus updates per review
* more updates per review
* fix file name
* fix qdq tests
* plus more updates
* plus updates
* typo fix
* fix qdq selection in 2nd optimization pass
* fix typo
* fix a test
* update dependency structure for layout transformer
* plus updates
* more updates
* plus change
* more updates to fix linker error in minimal build
* remove unnecessary headers
Add abseil cgmanifest declaration. Update coding standards for InlinedContainers
Adjust coding guidelines. Add default N calculation for InlinedVector<T, N> for general use.
Rename T from InlinedShapeVectorT. Fix Eager build
Add LLVM Copyright with modified derived code notice.
Add abseil and inlined containers typedefs
Introduce TensorShapeVector for shape building.
Use gsl::span<const T> to make interfaces accept different types of vector like args.
Introduce InineShapeVectorT for shape capacity typed instantiations
Refactor cuda slice along with provider shared interfaces
Refactor Concat, Conv, Pad
Build with Conv Einsum and ConvTranspose refactored.
Remove TesnorShape::GetDimsAsVector()
Refactor SliceIterator and SliceIteratorBase
Refactor broadcast
Refactor Pads for twice as long
Remove memory planner intermediate shapes vector
Refactor orttraining
Fix passing TenshroShapeVector to tests
Remove abseil copy and submodule, use FetchContent_Declare/Fetch
Path with separate command
Make RocmAsyncBuffer accept anything convertible to span. Adjust Linux GPU pipeline.
* add new field constant_initializers in metadef and remove constant initializers from trt node inputs
* remove redundancy
* use GetConstantInitializer() to get constant initializers
* add ORT_ENFORCE check
Co-authored-by: Ubuntu <azureuser@orteplinuxdev.bxgbzpva45kedp3rhbsbit4phb.jx.internal.cloudapp.net>
* squashed commit for standalone tvm execution provider
* critical fix for correct python build with stvm ep
* get tuning log file from ep options. It has priority over AUTOTVM_TUNING_LOG
* updates and fixes
* update parsing of stvm provider options
* add support of external data for onnx model
* add conditional dump of subgraphs
* remove unused code
* get input tensor shapes through provider options. get output shapes for fixed input ones by TVM API
* support AUTO_TVM tuning log file inside ORT. Selector for Ansor and Auto_TVM is provider option (tuning_type)
* add fp16
* add functionality of conversion of model layout to NHWC if need. Necessary parameter was added to STVM provider options
* fix license text in header. fix log format
* small fixes
* fix issues from flake8
* remove model proto construction from GetCapability
* reserve memory for vector of DLTensors
* add simple tutorial for STVM EP
* STVM docs
* jroesch/tvm -> apache/tvm
* remove dead code, unneccessary logs and comments
* fix in readme
* improve tutorial notebook
* tvm update
* update STVM_EP.md
* fix default value
* update STVM_EP.md
* some TODOs for the future development
* shorten long lines
* add hyperlink to STVM_EP.md
* fix Linux CI error
* fix error in csharp test
Co-authored-by: Jared Roesch <jroesch@octoml.ai>
Co-authored-by: Valery Chernov <valery.chernov@deelvin.com>
Co-authored-by: KJlaccHoeUM9l <wotpricol@mail.ru>
* Added checks for Hetero/Multi
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Remote Context Plugin
* changes for IO Buffer plugin
* erronous couts added
* erronous entry rectified
* Set the Openvino OP Buffer also as output
* Enable AUTO plugin in OpenVINO EP
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Remote Context Plugin
* changes for IO Buffer plugin
* erronous couts added
* erronous entry rectified
* Added checks for Hetero/Multi
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Set the Openvino OP Buffer also as output
* Enable AUTO plugin in OpenVINO EP
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Please commit error message and rectification of param.context
* Alignment fixed
Signed-off-by: MaajidKhan <n.maajidkhan@gmail.com>
* Changed the string to OpenVINO_GPU
* hanged OpenVINO to to OpenVINO_CPU
* Onnxruntime updated API for memory location
* Removing Duplicate LOG Error
* Tensor.h removed DeviceType function. Updated comment
* API Comments updated
* Removing changes to Provider Indo
* Erronous commit
* Removing Extra logs
* Merge CMAKE
* Not copy from a local location
* Duplicate Entry
* Remove extra line
Co-authored-by: MaajidKhan <n.maajidkhan@gmail.com>
* schema change
* cc channges
* remove temp debug code
* Adding fbs namespace to session_state_flatbuffers_utils.h
* Add fbs namepsace to all ort format utils
* Construct valid graphs for ONNX checker for IR version < 4.
Previously the constructed graph was not guaranteed to have its
initializers be a subset of its inputs, which is required for IR
version < 4. This resulted in spurious failures.
Fixes#9663
Add support for saving graph runtime optimizations in an ORT format model. The idea is to allow some optimizations to be "replayed" at runtime in a minimal build. The replaying part will be in a future change.
* re-hipify all rocm EP sources
* fix all other files affected by re-hipify
* add cuda_provider_factory.h to amd_hipify.py
* do not use cudnn_conv_algo_search in ROCm EP, missing reduce min registration
* Fix ReduceConsts template specialization introduced in #9101.
Fixes the error when building for ROCm 4.3.1:
error: too many template headers for onnxruntime::rocm::ReduceConsts<__half>::One (should be 0)
* fix flake8 error in amd_hipify.py
* speed up hipify with concurrent.futures
* flake8 fix in amd_hipify.py
* Remove unused NodeArgs
* Handle case where a node arg from an initializer from initializer_names_to_preserve
* Fix CI failure
* update test
* Fix outer scope node args failure
* Use NodeArg* as the key of the std::set instead of string
* Minor updates
* implement cuda provider
* define profiler common
* call start after register
* add memcpy event
* add cuda correlation
* format code
* add cupti to test path
* switch to CUpti_ActivityKernel3
* reset cupti path
* fix test case
* fix trt pipeline
* add namespace
* format code
* exclude training from testing
* remove mutex
Add documentation for these C API functions:
RunOptionsGetRunLogSeverityLevel
RunOptionsGetRunLogVerbosityLevel
RunOptionsGetRunTag
RunOptionsSetRunLogSeverityLevel
RunOptionsSetRunLogVerbosityLevel
RunOptionsSetRunTag
Update some existing documentation.
* updates for picking pnnx commit
* add tests filter to c# tests
* plus test fixes
* fix versioning for contrib ops
* fix tests
* test filter for optional ops
* more versioning related updates
* fix test
* fix layernorm spec
* more updates
* update docs
* add more test filters
* more filters
* update binary size threshold
* update docs
* draft - enable model local function
* enable model local functions in ORT
* update to latest rel onnx commit
* plus tests
* plus more updates
* plus updates
* test updates
* Fix for nested functions + shape inference
* plus bug fix and updates per review
* plus fixes per review
* plus test updates
* plus updates per review
* plus fixes
* fix a test
* support register external ep lib inforation; make eager mode share the same ep pools with training workloads
* fix inference code
* fix build break
* fix the message
* seperate the training python module; share the execution proivder instance
* fix build break
* fix cuda test crash; reorg the python module code base
* se correct env
* use provider customized hash func
* fixbuild break
* fix rocm break
* use const ref in argument
* rename the file
* move hash func to trainiing module
* Revert "Cleanup C# bindings to add EP (#8810)"
This reverts commit b21ea00020.
* Add back in a minimal set of changes.
Provide stubs in for a limited set of things
- things called from C# using a static lib of ORT built for mac/ios
- things in OrtApis that are not included in the build by default
- things in OrtApis that are excluded in a minimal build
* Cleanup order or EPs in test
* Fix unused function in ROCM build
Add cmake parameter and #ifdefs to allow for disabling sparse tensor support. This comes with a significant binary size cost so we want to be able to exclude it in a minimal build.
Fix C# add EP bindings.
Add stubs to ORT so that if EP is not included in the build we return a graceful error message.
Move declaration of stubs into C API and out for EP so they're in one place and are easier to use (no extra header required in the C/C++ world and consistent with the CUDA EP setup).
Fix inconsistency in ROCM EP.
Cleanup a few other things.
Add IsSparseTensor
Add CreateSparseTensor
Add utilities and test fully sparse instantiation
Fully sparse blocksparse
Add test and docs for fully sparse tensor instantiation
Rework creation API
Use API
Non string API
Retrofit of existing String API
Add tests
Add documentation
Address build issues (Winml pending)
Add inference test
Bump binary size
Add ifdef DISABLE CONTRIB
* Do not copy the model_data when session is started by CreateSessionFromArray
* Add config option for disabling copy model bytes
* Add one additional test
* Address CR comments
SparseTensor support
Implement Builder pattern
Fix support for 1-D and 2-D COO indices
Implement and test CSR support.
Handle shape inference for SparseTensors
Implement conversion for COO, CSR and tests.
Address the case where constant sparse initializer is the output.
Implement test infra for SparseTensors
Implement SparseDenseMatMul for Csr and COO and tested it.
Add hash for SparseToDenseMatMul
Finish shared provider refactor
Refactor GetOrCreate to Create
Working on py interface
Expose OrtDevice and use it in allocate_numpy
Adjust Sparse interfaces, add support for string SparseTensor. Add tests.
Add and test to_cuda()
Add accessors to format specific indices
Test values and indices views, read-only flag, after GC access
Add sparse related methods to OrtValue
Re-work SparseTensor wrapper, add OrtValue methods
Rework numpy_array_to_cuda/to_cpu
Add run_with_ort_values
Add models and test sparse_mat_mul with run_with_ort_values
Refactor sparse tensor to use a single buffer
Ifdef x86 Eigen CSR sparse matmul implementation
Exclude broken test, check for string type when copying cross device
Split pybind schema, regenerate docs, add exclusion
Conditionally exclude schema module
Update docs fix cuda build
Add test to a filter and renerate JS docs
Add conversion and test string support for sparse tensors
Exclude conversion utils from minimal build
Add CUDA Memcpy and adjust provider interfaces
* Add helper to check if node provides a graph output. The current approach unnecessarily creates a vector when most of the optimizers only care about a true/false response.
* Undo accidental change
* Fix a couple of issues due to copying from larger set of changes.
Switched the code to C++17. To build ONNX Runtime on old distros like CentOS 7, you need to install a newer GCC from additionary repos. If you build onnxruntime with the newer GCC, typically the result binary can't be distributed to other places because it depends on the new GCC's runtime libraries, something that the stock OS doesn't have. But on RHEL/CentOS, it can be better. We use Red Hat devtoolset 8/9/10 with CentOS7 building our code. The new library features(like std::filesystem) that not exists in the old C++ runtime will be statically linked into the applications with some restrictions:
1. GCC has dual ABI, but we can only use the old one. It means std::string is still copy-on-write and std::list::size() is still O(n). Also, if you build onnxruntime on CentOS 7 and link it with some binaries that were built on CentOS 8 or Ubuntu with the new ABI and export C++ symbols directly(instead of using a C API), the it won't work.
2. We still can't use std::optional. It is a limitation coming from macOS. We will solve it when we got macOS 11 build machines. It won't be too long.
3. Please avoid to use C++17 in CUDA files(*.cu). Also, the *.h files that they include(like core/framework/float16.h). This is Because CUDA 10.2 doesn't support C++17. You are welcome to use the new features in any *.cc files.
* prepare for C# to configure provider options
* add c# code
* revert modification
* Add update provider info configuration in trt ep side
* fix bugs
* fix bug for compiler error C2259
* Add c# test
* fix bug
* fix bug
* Properly deal with string
* Add c# api for accepting trt provider options
* fix bug
* Modify C# test
* add shared lib test
* Add get provider options functionality
* clean up
* clean up
* fix bug
* fix bugs for CI
* Fix bugs for CI and documentation
* Move TRT EP provider options related functions out of C API
* revert
* fix bug
* refactor
* add check for provider options string
* code refactor
* fix CI bug
* Fix CI bugs
* clean up
* fix bug
* Fix bug for Post Analysis
* fix accidental bug
* Add API_IMPL_BEGIN/API_IMPL_END
* clean up
* code refactor
* code refactor
* fix CI fail
* fix bug
* use string append
* Change the code to better handle strncpy and string append
* Output error message to android log instead of stderr
* Address CR comments, move macro to a helper function
* Address CR comments
* Fix ort minimal build break
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}