Implement CloudEP for hybrid inferencing.
The PR introduces zero new API, customers could configure session and
run options to do inferencing with Azure [triton
endpoint.](https://learn.microsoft.com/en-us/azure/machine-learning/how-to-deploy-with-triton?tabs=azure-cli%2Cendpoint)
Sample configuration in python be like:
```
sess_opt.add_session_config_entry('cloud.endpoint_type', 'triton');
sess_opt.add_session_config_entry('cloud.uri', 'https://cloud.com');
sess_opt.add_session_config_entry('cloud.model_name', 'detection2');
sess_opt.add_session_config_entry('cloud.model_version', '7'); // optional, default 1
sess_opt.add_session_config_entry('cloud.verbose', '1'); // optional, default '0', meaning no verbose
...
run_opt.add_run_config_entry('use_cloud', '1') # 0 for local inferencing, 1 for cloud endpoint.
run_opt.add_run_config_entry('cloud.auth_key', '...')
...
sess.run(None, {'input':input_}, run_opt)
```
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
### Description
Adds support for variadic inputs and outputs to custom operators.
### Motivation and Context
Needed for custom ops that wrap external runtimes/models and maybe TensorRT plugins.
### Description
Update absl to a new version
### Motivation and Context
The new version contains fixes that are needed for Nvidia GPU build.
Once we update it to that version, we don't need to maintain our private
patches for Nvidia GPU build.
### Description
Add the ability to run graph
### Motivation and Context
A brief description is as follows:
1) If the whole graph is supported, then will be processed by the graph
engine, directly.
2) If the whole graph is not supported, the whole graph will be divided
into subgraphs and single operators; The sub-graphs will be run on graph
engine, and the single operators will fallback to the traditional mode.
**Description**: This PR including following works:
1. provide stream and related synchronization abstractions in
onnxruntime.
2. enhance onnxruntime's execution planner / executor / memory arena to
support execute multiple streams in parallel.
3. deprecate the parallel executor for cpu.
4. deprecate the Fence mechanism.
5. update the cuda / tensorrt EP to support the stream mechanism,
support running different request in different cuda stream.
**Motivation and Context**
- Why is this change required?
currently, the execution plan is just a linear list of those primitives,
ort will execute them step by step. For any given graph, ORT will
serialize it to a fixed execution order. This sequential execution
design simplifies most scenarios, but it has the following limitations:
1. it is difficult to enable inter-node parallelization, we have a
half-baked parallel executor but it is very difficult to make it work
with GPU.
2. The fence mechanism can work with single gpu stream + cpu thread
case, but when extend to multiple stream, it is difficult to manage the
cross GPU stream synchronizations.
3. our cuda EP rely on the BFCArena to make the memory management work
with the GPU async kernels, but current BFCArena is not aware of the
streams, so it doesn't behavior correctly when run with multiple
streams.
This PR enhance our existing execution plan and executor to support
multiple stream execution. we use an unified algorithm to mange both
single stream and multiple stream scenarios.
This PR mainly focus on the infrastructure support for multiple stream
execution, that is said, given a valid stream assignment, onnxruntime
can execute it correctly. How to generate a good stream assignment for a
given model will be in the future PR.
Co-authored-by: Cheng Tang <chenta@microsoft.com@orttrainingdev9.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Cheng Tang <chenta@microsoft.com>
Co-authored-by: RandySheriffH <48490400+RandySheriffH@users.noreply.github.com>
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
Co-authored-by: cao lei <jslhcl@gmail.com>
Co-authored-by: Lei Cao <leca@microsoft.com>
The float16.h header is shared between the CPU and ROCm EPs. The
USE_ROCM macro is defined universally, but for the float16.h header we
only wish to detect the hip-clang compiler. Otherwise, the CPU EP fails
to build because of -Werror -Wuninitialized caused by the USE_ROCM code
additions, and the CPU EP should be using a different code path.
### Description
To pass session_options to Xnnpack EP via
`XnnpackProviderFactoryCreator` for Initializing xnnpack's threadpool.
If you want to use different threadpool size or even disable xnnpack's
threadpool, just setting intra_threadpool to 1 by xnnpack EP's
provider_options.
### Motivation and Context
Co-authored-by: Guangyun Han <guangyunhan@microsoft.com>
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
### Description
The existing CUDA profiler is neither session-aware, nor thread-safe.
This PR ensures both.
### Motivation and Context
[PR 13549](https://github.com/microsoft/onnxruntime/pull/13549) brought
thread-safety and session-awareness to the ROCm profiler. This PR brings
the same goodness to the CUDA profiler as well.
Sample outputs of a profiling run from the StableDiffusion model (this
model was chosen because it requires orchestration of multiple sessions,
and verifies that the profilers are now indeed session-aware) on both
CUDA and ROCm EPs are attached, along with a script that checks that the
trace files generated by the profile are well-formed.
Update 11/29: Updated the profile outputs. The older profile outputs
exhibited an issue where some timestamps were wildly out of range,
leading to problems visualizing the traces. The bug has been fixed and
the profile outputs have been updated, along with an update to the check
script to ensure that timestamps are monotonically increasing.
[sd_profile_outputs_cuda.tar.gz](https://github.com/microsoft/onnxruntime/files/10118088/sd_profile_outputs_cuda.tar.gz)
[sd_profile_outputs_rocm.tar.gz](https://github.com/microsoft/onnxruntime/files/10118089/sd_profile_outputs_rocm.tar.gz)
[check_profile_output_well_formedness.zip](https://github.com/microsoft/onnxruntime/files/10118090/check_profile_output_well_formedness.zip)
Co-authored-by: Abhishek Udupa <abhishek.udupa@microsoft.com>
### Description
Decouple strided tensor support from ENABLE_TRAINING
### Motivation and Context
This is step 1 for creating a dedicated build for on device training.
Intention is
1. We can set ENABLE_STRIDED_TENSORS in cmake when either
ENABLE_TRAINING or ENABLE_TRAINING_ON_DEVICE is selected, this way we
dont have to use if defined(ENABLE_TRAINING) ||
defined(ENABLE_TRAINING_ON_DEVICE ) everywhere in the code.
2. This also paves the way to easily enable strided tensor support for
inference in future (if required).
Accuracy loss is observed when transformer models such as BERT, DeBERTa,
ViT are running in TRT FP16 mode. The cause is that overflow happens at
Pow op in layer norm.
This PR provides the option to force Pow to run in TRT FP32 precision if
overflow occurs.
Co-authored-by: Ubuntu <azureuser@orteplinuxdev.bxgbzpva45kedp3rhbsbit4phb.jx.internal.cloudapp.net>
Right now we fix the warnings in an ad-hoc way. We run static analysis
in nightly builds, then create work items for the finding it found. Our
CI build pipelines run the same scan but do not break the build. So,
this PR will fix the remaining findings in the CPU EP(including the
training part) and enforce the check. Later on we can continue to expand
the scope.
We still have some warnings left in the JNI part. I will try to address
them later in the next month.
### Description
The existing ROCM profiler has a few shortcomings, which this PR fixes.
### Motivation and Context
The existing ROCM profiler:
1. Is not thread-safe
2. Is not session-aware: i.e., if multiple inference sessions enable
profiling, then events (esp GPU events) get mixed up between the
sessions
3. Has some issues with respect to coding standards.
This PR addresses all of the above by cleanly re-implementing parts of
the ROCM profiler as required.
Attached are 4 profile outputs from a multi-session run of the
StableDiffusion model, as well as a quick-and-dirty script that checks
the profile outputs for the invariants claimed.
[sd_profile_outputs.tar.gz](https://github.com/microsoft/onnxruntime/files/9924608/sd_profile_outputs.tar.gz)
[check_profile_output_wellformedness.zip](https://github.com/microsoft/onnxruntime/files/9924614/check_profile_output_wellformedness.zip)
Co-authored-by: Abhishek Udupa <abhishek.udupa@microsoft.com>
The old runtime optimization format is not readily convertible to the new one without extra information for translating kernel def hashes.
Ignore such saved runtime optimizations and output a warning for now.
### Description
* Add getter/setter to access and update C# OrtEnv log level
* Add C API about updating ort env with custom log level to support the
setter above (Following [pybind
implementation](952c99304a/onnxruntime/python/onnxruntime_pybind_state.cc (L923-L924)))
* Add test case to verify getter & setter
### Motivation and Context
* For C++/Python, the log level can be adjusted via OrtEnv, and this
feature is missing in C# binding
**Description**: Subgraph-level recompute
This PR adds an optional capability trading additional re-computation
for better memory efficiency. Specifically, a pre-defined operator list
used to iterate the Graph to find some subgraphs for recompute, to
reduce some stashed activations whose lifetime across forward and
backward pass.
When training with ORTModule, by default, the graph transformer will
scan the execution graph to find all eligible subgraph to recompute,
along with sizes that can save. An example looks like below.
If we want to enable some of them to recompute, we can define env
variable this way:
`export
ORTMODULE_ENABLE_MEMORY_ALLEVIATION="Mul+FusedMatMul+Cast+Unsqueeze+Unsqueeze+Cast+Sub+Mul+Add+BiasSoftmaxDropout+Cast+:1:-1,BiasGelu+:1:-1,BitmaskDropout+Cast+:1:-1,FusedMatMul+:1:-1,Cast+:1:-1,Mul+Add+:1:-1,Mul+Sub+:1:-1"`
```
[1,0]<stderr>:2,022-10-12 14:47:39.302,954,530 [W:onnxruntime:, memory_alleviation.cc:595 PrintSummary]
[1,0]<stderr>:MemoryAlleviation Summary:
[1,0]<stderr>: User config:
[1,0]<stderr>: Mul+FusedMatMul+Cast+Unsqueeze+Unsqueeze+Cast+Sub+Mul+Add+BiasSoftmaxDropout+Cast+:1,BiasGelu+:1,BitmaskDropout+Cast+:1,FusedMatMul+:1,Cast+:1,Mul+Add+:1,Mul+Sub+:1
[1,0]<stderr>: =================================
[1,0]<stderr>: Subgraph: BitmaskDropout+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 1,024 x Frequency:1
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: BiasGelu+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x input_ids_dim1 x 4,096 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Reshape[1,0]<stderr>:+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:labels_dim0 x Frequency:1
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Unsqueeze+Unsqueeze+Cast+Sub+Mul+Mul+FusedMatMul+Cast+Add+BiasSoftmaxDropout+Cast+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x input_ids_dim1 x Frequency:23
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Mul+FusedMatMul+Cast+Unsqueeze+Unsqueeze+Cast+Sub+Mul+Add+BiasSoftmaxDropout+Cast+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x input_ids_dim1 x Frequency:1
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Mul+Add+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x 1 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: FusedMatMul+Cast+Add+Reshape+Cast+
[1,0]<stderr>: AlleviationType: Disabled
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x 2 x 4 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Mul+Sub+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x 16 x input_ids_dim1 x 1 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: Cast+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:1,024 x 1,024 x Frequency:97
[1,0]<stderr>: PatternShape:3 x 1,024 x Frequency:1
[1,0]<stderr>: PatternShape:8 x 64 x Frequency:24
[1,0]<stderr>: PatternShape:1,024 x 4,096 x Frequency:24
[1,0]<stderr>: PatternShape:4,096 x Frequency:24
[1,0]<stderr>: PatternShape:4,096 x 1,024 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: Subgraph: FusedMatMul+
[1,0]<stderr>: AlleviationType: Recompute
[1,0]<stderr>: Patterns:
[1,0]<stderr>: PatternShape:input_ids_dim0 x input_ids_dim1 x 4,096 x Frequency:24
[1,0]<stderr>: --------------------------------
[1,0]<stderr>: =================================
```
"Type config:" whether recompute is enabled by users. 0 - disable, 1-
enable.
"Subgraph" means what kind of subgraph will be recomputed, in this case,
it is a single node "Gelu", and it will be "Recompute".
"Shape && Frequency" means, for this recompute, one tensor of size
(batch size, 500) will be saved because it will be recomputed.
**Baseline**
On a 1P model (DEBERTA V2), sequence length 256, training with 16 A100
GPUs. With latest main branch, we can run batch size 16, and the maximum
batch size < 32. So 16 is usually chosen by data scientists. 65% of 40GB
memory is used during training. The SamplesPerSec=479.2543353561354.

**With this PR**
Gelu is recomputed for saving memory peak, batch size 32 can be run. The
97% of 40GB A100 is used, the SamplesPerSec=562.041593991271 (**1.17X**
of baseline).

**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
This PR enables ORT to execute graphs captured by TorchDynamo. Major compilation code is in `OrtBackend.compile` in ort_backend.py. `register_backend.py` is for plugging `OrtBackend` into TorchDynamo as a compiler.
- Reverts change to CustomOpApi::GetTensorData introduced by commit 5dae0c477d,
which causes infinite recursion.
- Moves EndsProfilingAllocated to non-const session implementation
(C++ API header).
### Description
<!-- Describe your changes. -->
The Env argument does not need to be mutable to call the underlying C
API. Update the Ort::Session ctor to have a const Env.
All other changes are from clang-format running.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Cleanup
### Description
Detect and report thread creation failure on Windows.
Do not throw out of constructor after the thread is created,
the thread handle is lost and cannot be joined, resulting in a deadlock.
Make setting a thread priority on Linux consistent with windows.
Set thread priority in the thread itself. Log failure properly,
but do not exit the thread.
### Motivation and Context
Address issues https://github.com/microsoft/onnxruntime/issues/13291
And
https://github.com/microsoft/onnxruntime/issues/13285#issuecomment-1278063223
clang-tidy says "Do not implicitly decay an array into a pointer; consider using gsl::array_view or an explicit cast instead"
It is a false positive scattering around all our codebase when using
helper macros. It is becuase for function with 4 char name, say `main`,
the type of __FUNCTION__ and __PRETTY_FUNCTION__ is `char [5]`.
### Description
Deprecate CustomOpApi and refactor dependencies for exception safety and
eliminate memory leaks.
Refactor API classes for clear ownership and semantics.
Introduce `InitProviderOrtApi()`
### Motivation and Context
Make public API better and safer.
Special note about `Ort::Unowned`. The class suffers from the following
problems:
1. It is not able to hold const pointers to the underlying C objects.
This forces users to `const_cast` and circumvent constness of the
returned object. The user is now able to call mutating interfaces on the
object which violates invariants and may be a thread-safety issue. It
also enables to take ownership of the pointer and destroy it
unintentionally (see examples below).
2. The objects that are unowned cannot be copied and that makes coding
inconvenient and at times unsafe.
3. It directly inherits from the type it `unowns`.
All of the above creates great conditions for inadvertent unowned object
mutations and destructions. Consider the following examples of object
slicing, one of them is from a real customer issue and the other one I
accidentally coded myself (and I am supposed to know how this works).
None of the below can be solved by aftermarket patches and can be hard
to diagnose.
#### Example 1 slicing of argument
```cpp
void SlicingOnArgument(Ort::Value& value) {
// This will take possession of the input and if the argument
// is Ort::Unowned<Ort::Value> it would again double free the ptr
// regardless if it was const or not since we cast it away.
Ort::Value output_values[] = {std::move(value)};
}
void main() {
const OrtValue* ptr = nullptr; // some value does not matter
Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)};
// onowned is destroyed when the call returns.
SlicingOnArgument(unowned);
}
```
#### Example 2 slicing of return value
```cpp
// The return will be sliced to Ort::Value that would own and relase (double free the ptr)
Ort::Value SlicingOnReturn() {
const OrtValue* ptr = nullptr; // some value does not matter
Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)};
return unowned;
}
```
**Description**: This PR adds Ascend CANN execution provider support.
**Motivation and Context**
- Why is this change required? What problem does it solve?
As the info shown in the issue. CANN is the API layer for Ascend
processor. Add CANN EP can allow user run onnx model on Ascend hardware
via onnxruntime
The detail change:
1. Added CANN EP framework.
2. Added the basic operators to support ResNet and VGG model.
3. Added C/C++、Python API support
- If it fixes an open issue, please link to the issue here.
https://github.com/microsoft/onnxruntime/issues/11477
Author:
lijiawei <lijiawei19@huawei.com>
wangxiyuan <wangxiyuan1007@gmail.com>
Co-authored-by: FFrog <ljw1101.vip@gmail.com>
This changes are to align OV 2022.2 Release with ORT . Changes
CPU FP16 Support, dGPU Support, RHEL Dockerfile, Ubuntu 20 Dockerfile
**Motivation and Context**
- This change is required to ensure ORT-OpenVINO Execution Provider is
aligned with latest changes.
- If it fixes an open issue, please link to the issue here.
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: shamaksx <shamax.kshirsagar@intel.com>
Co-authored-by: pratiksha <pratikshax.bapusaheb.vanse@intel.com>
Co-authored-by: pratiksha <mohsinx.mohammad@intel.com>
Co-authored-by: Sahar Fatima <sfatima.3001@gmail.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
Co-authored-by: nmaajidk <n.maajid.khan@intel.com>
Co-authored-by: Mateusz Tabaka <mateusz.tabaka@intel.com>
Co-authored-by: intel <intel@iotgecsp-nuc04.iind.intel.com>
# Motivation
Currently, ORT minimal builds use kernel def hashes to map from nodes to
kernels to execute when loading the model. As the kernel def hashes must
be known ahead of time, this works for statically registered kernels.
This works well for the CPU EP.
For this approach to work, the kernel def hashes must also be known at
ORT format model conversion time, which means the EP with statically
registered kernels must also be enabled then. This is not an issue for
the always-available CPU EP. However, we do not want to require that any
EP which statically registers kernels is always available too.
Consequently, we explore another approach to match nodes to kernels that
does not rely on kernel def hashes. An added benefit of this is the
possibility of moving away from kernel def hashes completely, which
would eliminate the maintenance burden of keeping the hashes stable.
# Approach
In a full build, ORT uses some information from the ONNX op schema to
match a node to a kernel. We want to avoid including the ONNX op schema
in a minimal build to reduce binary size. Essentially, we take the
necessary information from the ONNX op schema and make it available in a
minimal build.
We decouple the ONNX op schema from the kernel matching logic. The
kernel matching logic instead relies on per-op information which can
either be obtained from the ONNX op schema or another source.
This per-op information must be available in a minimal build when there
are no ONNX op schemas. We put it in the ORT format model.
Existing uses of kernel def hashes to look up kernels are replaced
with the updated kernel matching logic. We no longer store
kernel def hashes in the ORT format model’s session state and runtime
optimization representations. We no longer keep the logic to
generate and ensure stability of kernel def hashes.
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
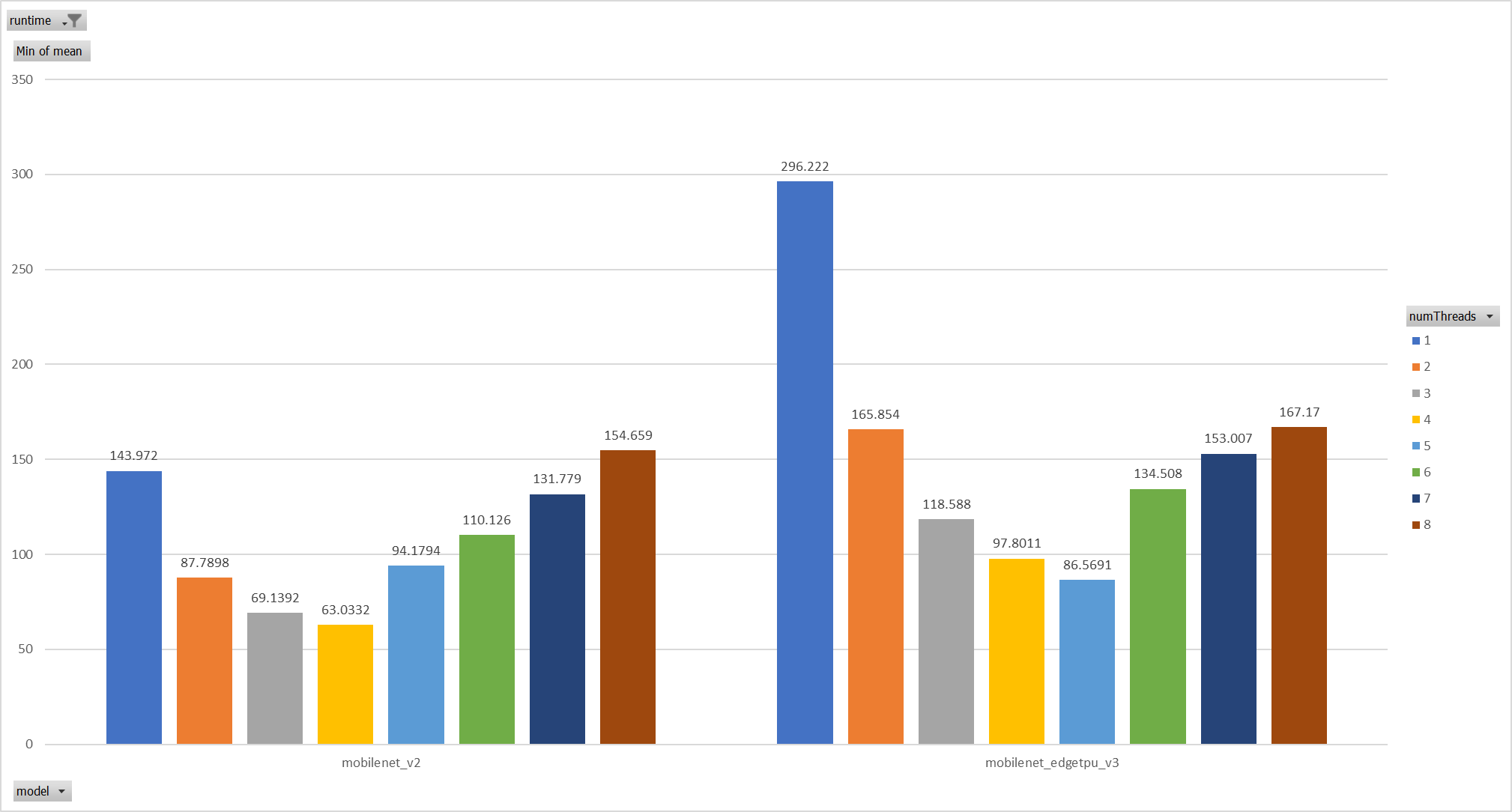
Case 2:
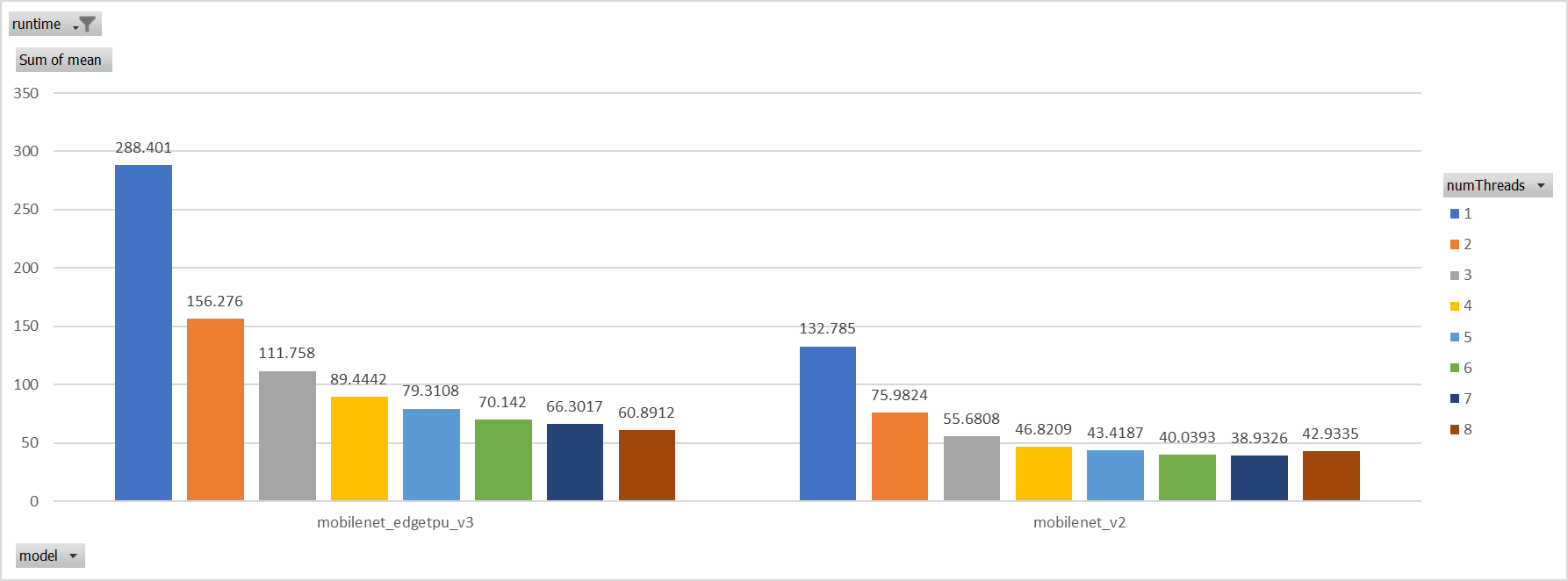
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
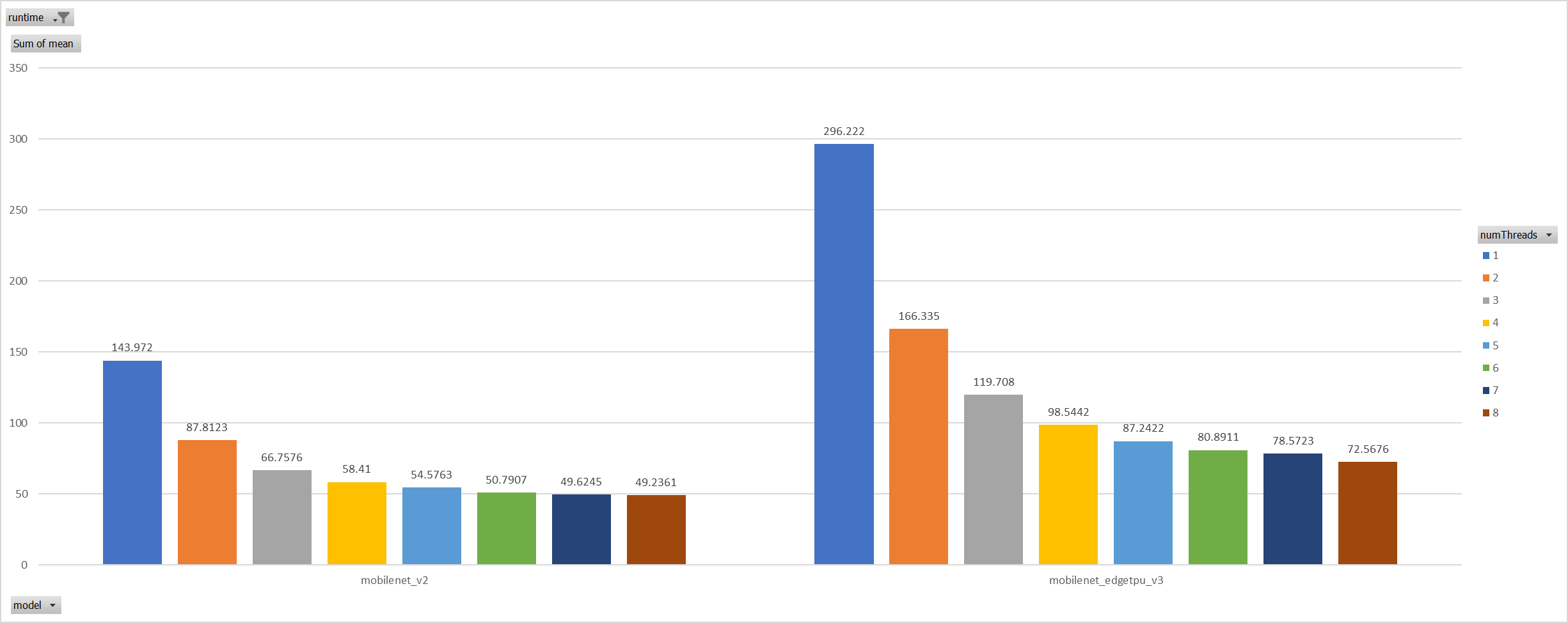
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
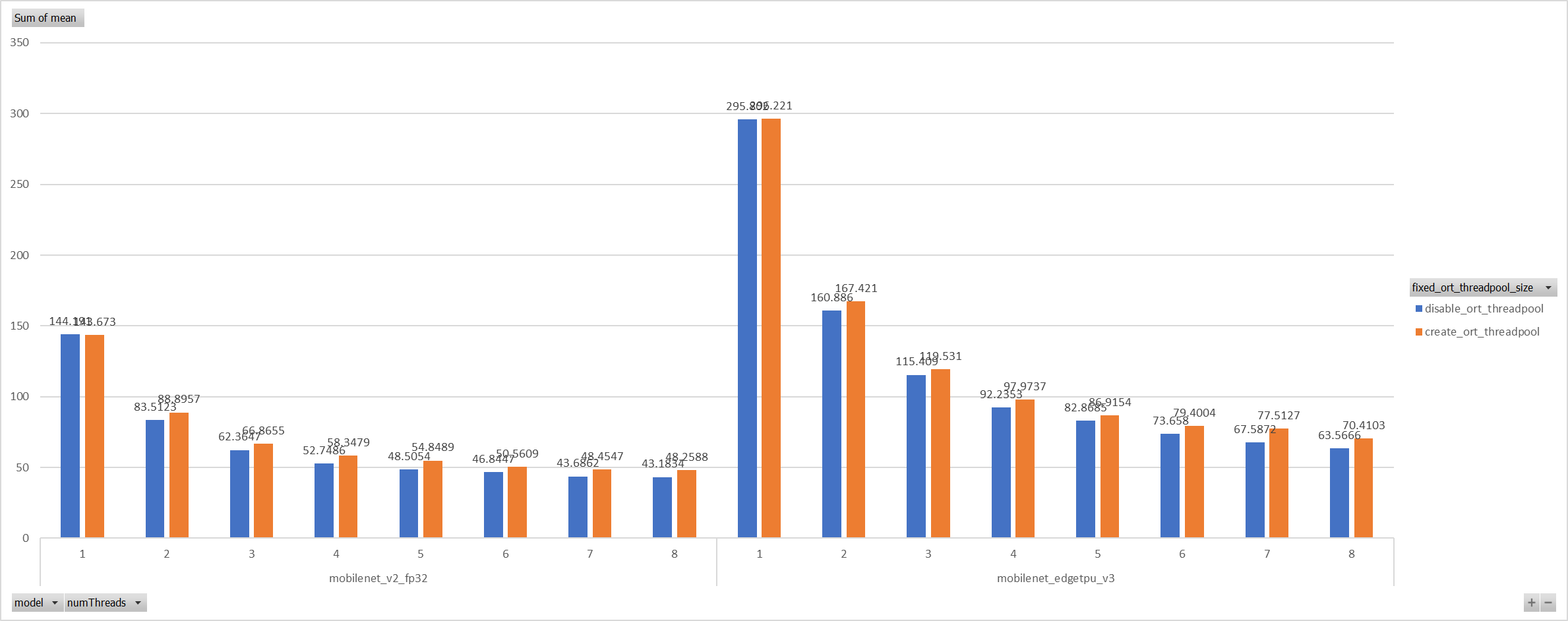
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
* upgrade emsdk to 3.1.19
* fix build break
* ignore '-Wunused-but-set-variable' in eigen
* add malloc and free in exported functions
* EXPORTED_FUNCTIONS
* Add first pass of rocm kernel profiler
* Clean up rocm_profiler. Format args. Demangle kernel names.
Add Api EventRecords
* Remove debug output
* Temporarily disable profiling unit test 'api record check' for cupti
* Fix compile error for non-gpu builds
* Use common file for demangle and pid/tid. Namespace ThreadUtil. Fix gpu buffer clearing.
* Merge demangle into profiler_common
* Merge demangle into profiler_common part 2
* Style cleanup
* Resolve linking issues via ProviderHost interface
* Demangle cuda kernel names
* Clean up comments
* Fix formatting
* Fix anal retentive formatting
LLVM compiler complains the std::hash<const char*> and suggests std::hash<const void*>. But the intention is to hash the name string instead of the pointer. So use std::hash<std::string> to be explicit.
* Add ability to use ORT format model flatbuffer directly for intiializers by leveraging the TensorProto external data infrastructure.
Requires user to provide ORT format model bytes when creating the session, and set both `session.use_ort_model_bytes_directly` and `session.use_ort_model_bytes_for_initializers` to 1 in SessionOptions config entries (AddSessionConfigEntry in C API).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}