### Description
<!-- Describe your changes. -->
The Env argument does not need to be mutable to call the underlying C
API. Update the Ort::Session ctor to have a const Env.
All other changes are from clang-format running.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
Cleanup
### Description
Detect and report thread creation failure on Windows.
Do not throw out of constructor after the thread is created,
the thread handle is lost and cannot be joined, resulting in a deadlock.
Make setting a thread priority on Linux consistent with windows.
Set thread priority in the thread itself. Log failure properly,
but do not exit the thread.
### Motivation and Context
Address issues https://github.com/microsoft/onnxruntime/issues/13291
And
https://github.com/microsoft/onnxruntime/issues/13285#issuecomment-1278063223
clang-tidy says "Do not implicitly decay an array into a pointer; consider using gsl::array_view or an explicit cast instead"
It is a false positive scattering around all our codebase when using
helper macros. It is becuase for function with 4 char name, say `main`,
the type of __FUNCTION__ and __PRETTY_FUNCTION__ is `char [5]`.
### Description
Deprecate CustomOpApi and refactor dependencies for exception safety and
eliminate memory leaks.
Refactor API classes for clear ownership and semantics.
Introduce `InitProviderOrtApi()`
### Motivation and Context
Make public API better and safer.
Special note about `Ort::Unowned`. The class suffers from the following
problems:
1. It is not able to hold const pointers to the underlying C objects.
This forces users to `const_cast` and circumvent constness of the
returned object. The user is now able to call mutating interfaces on the
object which violates invariants and may be a thread-safety issue. It
also enables to take ownership of the pointer and destroy it
unintentionally (see examples below).
2. The objects that are unowned cannot be copied and that makes coding
inconvenient and at times unsafe.
3. It directly inherits from the type it `unowns`.
All of the above creates great conditions for inadvertent unowned object
mutations and destructions. Consider the following examples of object
slicing, one of them is from a real customer issue and the other one I
accidentally coded myself (and I am supposed to know how this works).
None of the below can be solved by aftermarket patches and can be hard
to diagnose.
#### Example 1 slicing of argument
```cpp
void SlicingOnArgument(Ort::Value& value) {
// This will take possession of the input and if the argument
// is Ort::Unowned<Ort::Value> it would again double free the ptr
// regardless if it was const or not since we cast it away.
Ort::Value output_values[] = {std::move(value)};
}
void main() {
const OrtValue* ptr = nullptr; // some value does not matter
Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)};
// onowned is destroyed when the call returns.
SlicingOnArgument(unowned);
}
```
#### Example 2 slicing of return value
```cpp
// The return will be sliced to Ort::Value that would own and relase (double free the ptr)
Ort::Value SlicingOnReturn() {
const OrtValue* ptr = nullptr; // some value does not matter
Ort::Unowned<Ort::Value> unowned{const_cast<OrtValue*>(ptr)};
return unowned;
}
```
**Description**: This PR adds Ascend CANN execution provider support.
**Motivation and Context**
- Why is this change required? What problem does it solve?
As the info shown in the issue. CANN is the API layer for Ascend
processor. Add CANN EP can allow user run onnx model on Ascend hardware
via onnxruntime
The detail change:
1. Added CANN EP framework.
2. Added the basic operators to support ResNet and VGG model.
3. Added C/C++、Python API support
- If it fixes an open issue, please link to the issue here.
https://github.com/microsoft/onnxruntime/issues/11477
Author:
lijiawei <lijiawei19@huawei.com>
wangxiyuan <wangxiyuan1007@gmail.com>
Co-authored-by: FFrog <ljw1101.vip@gmail.com>
This changes are to align OV 2022.2 Release with ORT . Changes
CPU FP16 Support, dGPU Support, RHEL Dockerfile, Ubuntu 20 Dockerfile
**Motivation and Context**
- This change is required to ensure ORT-OpenVINO Execution Provider is
aligned with latest changes.
- If it fixes an open issue, please link to the issue here.
Co-authored-by: mayavijx <mayax.vijayan@intel.com>
Co-authored-by: shamaksx <shamax.kshirsagar@intel.com>
Co-authored-by: pratiksha <pratikshax.bapusaheb.vanse@intel.com>
Co-authored-by: pratiksha <mohsinx.mohammad@intel.com>
Co-authored-by: Sahar Fatima <sfatima.3001@gmail.com>
Co-authored-by: Preetha Veeramalai <preetha.veeramalai@intel.com>
Co-authored-by: nmaajidk <n.maajid.khan@intel.com>
Co-authored-by: Mateusz Tabaka <mateusz.tabaka@intel.com>
Co-authored-by: intel <intel@iotgecsp-nuc04.iind.intel.com>
# Motivation
Currently, ORT minimal builds use kernel def hashes to map from nodes to
kernels to execute when loading the model. As the kernel def hashes must
be known ahead of time, this works for statically registered kernels.
This works well for the CPU EP.
For this approach to work, the kernel def hashes must also be known at
ORT format model conversion time, which means the EP with statically
registered kernels must also be enabled then. This is not an issue for
the always-available CPU EP. However, we do not want to require that any
EP which statically registers kernels is always available too.
Consequently, we explore another approach to match nodes to kernels that
does not rely on kernel def hashes. An added benefit of this is the
possibility of moving away from kernel def hashes completely, which
would eliminate the maintenance burden of keeping the hashes stable.
# Approach
In a full build, ORT uses some information from the ONNX op schema to
match a node to a kernel. We want to avoid including the ONNX op schema
in a minimal build to reduce binary size. Essentially, we take the
necessary information from the ONNX op schema and make it available in a
minimal build.
We decouple the ONNX op schema from the kernel matching logic. The
kernel matching logic instead relies on per-op information which can
either be obtained from the ONNX op schema or another source.
This per-op information must be available in a minimal build when there
are no ONNX op schemas. We put it in the ORT format model.
Existing uses of kernel def hashes to look up kernels are replaced
with the updated kernel matching logic. We no longer store
kernel def hashes in the ORT format model’s session state and runtime
optimization representations. We no longer keep the logic to
generate and ensure stability of kernel def hashes.
**Description**: Describe your changes.
XNNPACK takes pthreadpool as its internal threadpool implemtation, it
couples calculation and parallelization. Thus it's impossible to
leverage ORT's threadpool (EIGEN/OPENMP based). So we enabled
pthreadpool in XNNPACK EP in this PR.
Case 1: Pthreadpool coexist with ORT-threadpool simply
Expriments setup
hardware:RedMi8A with 8 cores, ARMv7
The two threadpool has the same pool size form 1 to 8.
Two models: mobilenet_v2 and mobilenet_egetppu.
we can see the picture below and draw a conclusion, latency are even
higher from 5 threads or more.
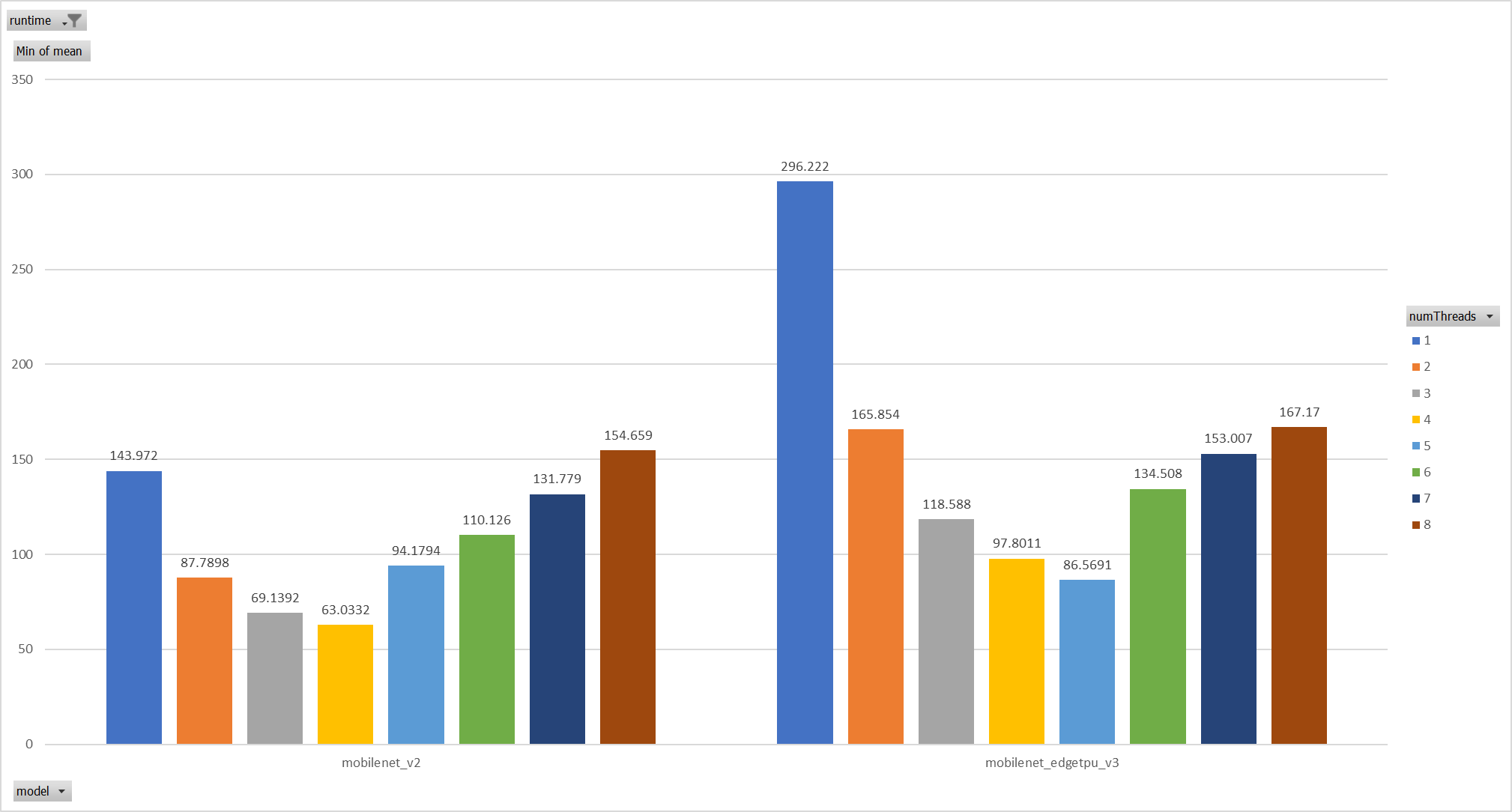
Case 2:
For the reason of performance regression with 5 more threads,
ORT-threads are spinning on CPU and diddn't realease it after
computation finished. It's equivalent of creating 5x2 threads for
parallelization while we have only 8 cpu cores.
So I mannuly disabled spinning after ort-threadpool finished and enabled
it when enter ort-threadpool.
The result is quite normal now.
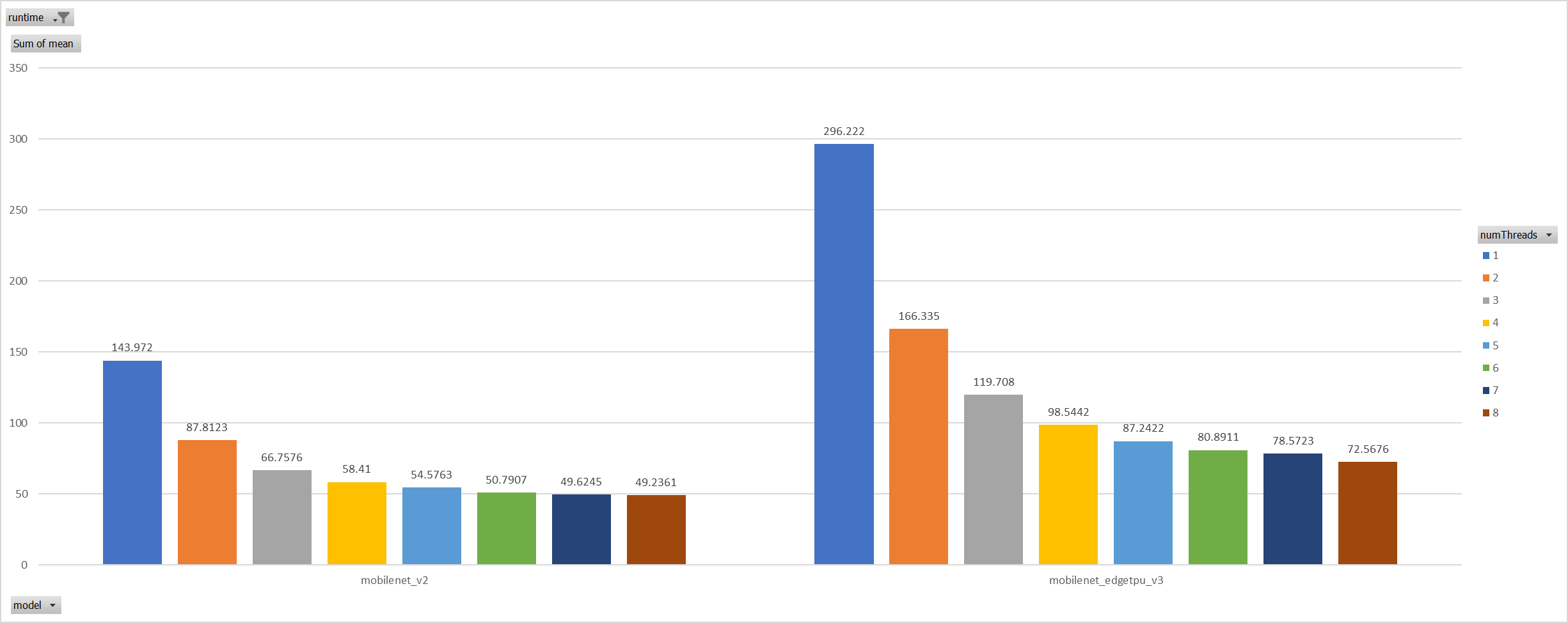
Case 3:
Even we achieved a reasonable results with disabling spinning, Will
ORT-threadpool still impact performance of pthreadpool?
we have expriment setting up as: Setting ORT-threadpool size
(intra_thread_num) as 1, and only pthreadpool created.
Attention that, almost a third of ops are running by CPU EP. we are
surprisingly find that disabling ort-threadpool is even better in
performance than creating two threadpool.
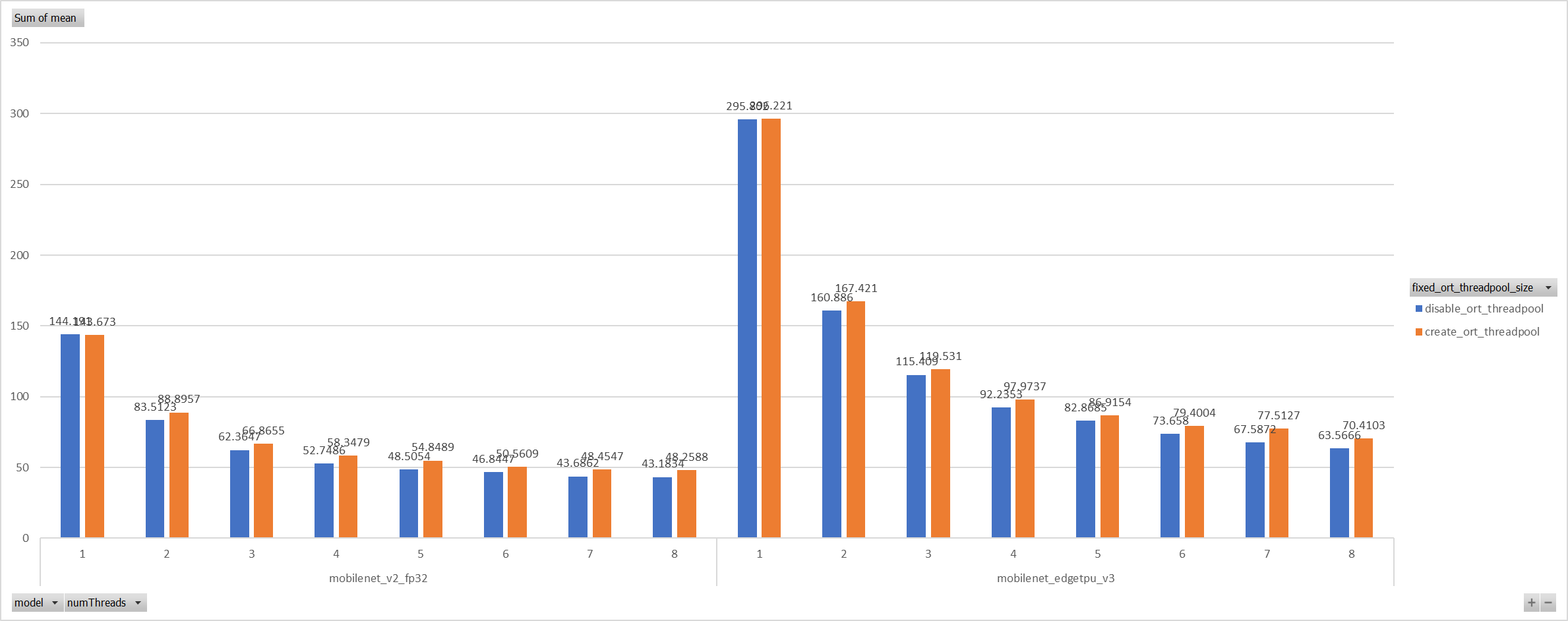
Case 4:
Use a unified threadpool between CPU ep and XNNPACK ep.
It's the fastest among all. But if we take the similar workload
partition strategy as ORT-threadpool, it could be faster.
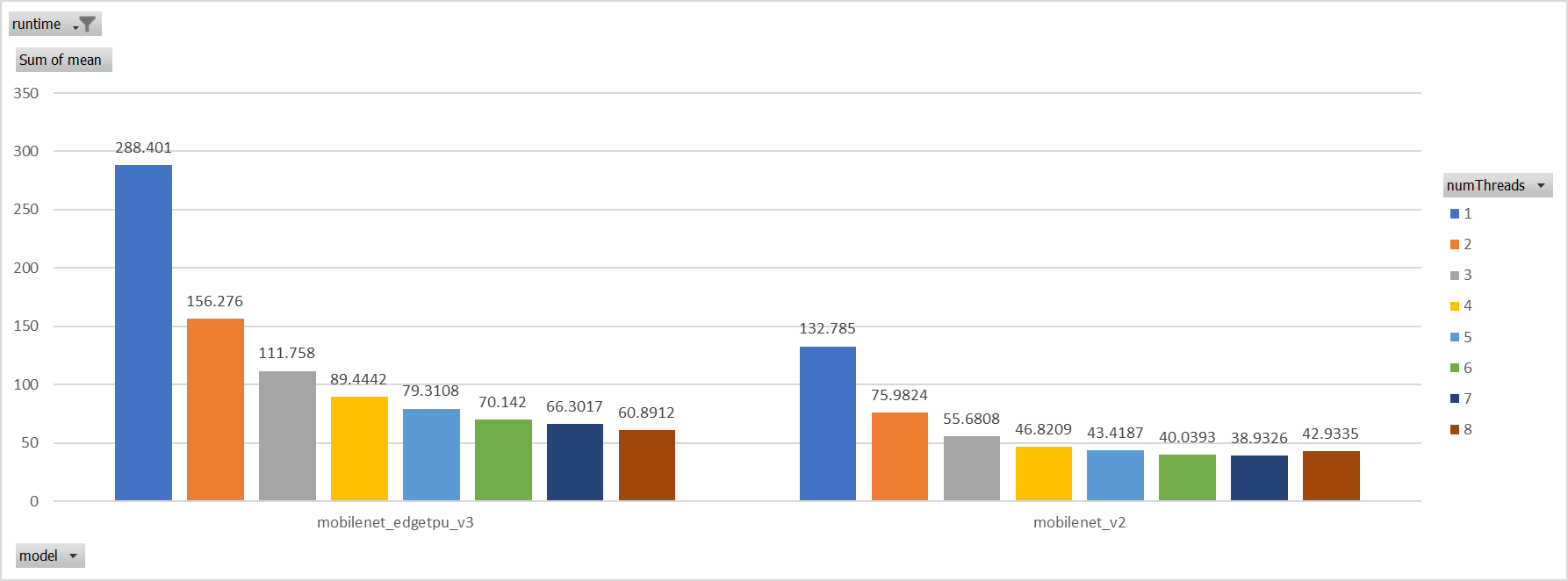
**Motivation and Context**
- Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here.
Co-authored-by: Jicheng Wen <jicwen@microsoft.com>
* upgrade emsdk to 3.1.19
* fix build break
* ignore '-Wunused-but-set-variable' in eigen
* add malloc and free in exported functions
* EXPORTED_FUNCTIONS
* Add first pass of rocm kernel profiler
* Clean up rocm_profiler. Format args. Demangle kernel names.
Add Api EventRecords
* Remove debug output
* Temporarily disable profiling unit test 'api record check' for cupti
* Fix compile error for non-gpu builds
* Use common file for demangle and pid/tid. Namespace ThreadUtil. Fix gpu buffer clearing.
* Merge demangle into profiler_common
* Merge demangle into profiler_common part 2
* Style cleanup
* Resolve linking issues via ProviderHost interface
* Demangle cuda kernel names
* Clean up comments
* Fix formatting
* Fix anal retentive formatting
LLVM compiler complains the std::hash<const char*> and suggests std::hash<const void*>. But the intention is to hash the name string instead of the pointer. So use std::hash<std::string> to be explicit.
* Add ability to use ORT format model flatbuffer directly for intiializers by leveraging the TensorProto external data infrastructure.
Requires user to provide ORT format model bytes when creating the session, and set both `session.use_ort_model_bytes_directly` and `session.use_ort_model_bytes_for_initializers` to 1 in SessionOptions config entries (AddSessionConfigEntry in C API).
Add a graph optimization that convert u8s8 matrix multiplication to u8u8 if needed
In x86/64 platforms, specifically SSE4.1, AVX2 and AVX512 CPUs provide better performance computing u8s8 matrix multiplications. Unfortunately, the higher performance comes with value overflow problems, as described in:
https://www.intel.com/content/www/us/en/develop/documentation/onednn-developer-guide-and-reference/top/advanced-topics/nuances-of-int8-computations.html
In this change we added a session option "session.x64quantprecision" (default off). For operators that calls u8s8 matrix multiplications, e.g. QAttention, we convert them to u8u8 when the following conditions are all satisfied:
1. Current CPU is SSE4.1, AVX2 or AVX512 with no VNNI support
2. Session option "session.x64quantprecision" is on.
3. Constant weight tensor contains values outside of [-64, 63] range
Note that when weight tensor is not constant, QDQS8ToU8Transformer should already convert it to u8.
* create op from ep
* read input count from context
* create holder to host nodes
* fix typo
* cast type before comparison
* throw error on API fail
* silence warning from minimal build
* switch to unique_ptr with deleter to host nodes
* fix typo
* fix build err for minimal
* fix build err for minimal
* add UT for conv
* enable test on CUDA
* add comment
* fix typo
* use gsl::span and string view for Node constructor
* Added two APIs - CopyKernelInfo and ReleaseKernelInfo
* pass gsl::span by value
* switch to span<NodeArg* const> to allow for reference to const containers
* fix typo
* fix reduced build err
* fix reduced build err
* refactoring node construction logic
* rename exceptions
* add input and output count as arguments for op creation
* refactor static member
* use ORT_CATCH instead of catch
* cancel try catch
* add static value name map
* format input definition and set err code
* fix comments
* fix typo
{kind=link}
{kind=link}
{kind=link}
{kind=link}