### PythonOp Enhancement: Bool and Tuple[Bool] Constants, Materialize
Grads, Empty Inputs, Save In Context
1. Support `bool` or `Tuple[bool]` constant type in inputs.
2. Support `ctx.set_materialize_grads(True|False)`
3. Backward op can accept empty input (that don't require grad)
4. Special handling for ORT tensors are saved in context
**Scenario**: a tensor is generated by ORT, then it might be saved for
backward by `ctx.save_for_backward(tensor)`, while `tensor`'s reference
count is not increased in ORT's allocation plan, so it is possible ORT
release the tensor data, before backward usage.
**Currently**: we copy every tensor before running
autograd.Function.forward(), this might be a problem for cases there are
many PythonOp (for example zero stage 3).
**Proposal**: To avoid those unnecessary copies for tensors that are not
saved in context, this change introduced a `_GlobalOpKernelInfoMap`.
During the kernel first run, we will anyway copy all tensors generated
from ORT, and give it to torch.autograd.Function for run, then we check
whether the inputs needs to be saved in context, and save the input
index that needs saving in `_GlobalOpKernelInfoMap`. Then for later
iterations, we just copy what is needed.
### Allow defining customized PythonOp shape inferer
For `torch.autograd.Function`, we converted it to PythonOp in MSDomain,
there are two places to do shape inferencing for it:
1. in SymbolicShapeInfer, there is one.
2. in PythonOp op definition.
For common PythonOp, since we don't know the relation ship between
inputs and outputs, so we only infer the rank from output ranks, and
generate symbolic dimensions for each dim. While this will introduce
many meaningless symbolic dimensions, sometimes blocking our graph
transformers to do op fusion.
This PR provide a way to define custom shape inferencing for
`torch.autograd.Function` we defined, to propagate the original
dimensions across the PythonOp at the best efforts.
But the 2rd one is not covered yet, we could refine that later. Fixing
1st one is enough for ORTModule training/evaluation.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Use full qualified name for PythonOp export
Originally, when there are duplicate named torch.autograd.Function in
different module, for example:
`a.b.c.Gelu` v.s. `d.e.func.<locals>.Gelu`
We by default will throw exception to let user be aware we cannot
distinguish the two Gelu because during model export, we did not module
path. The workaround is we introduced
`ORTMODULE_SKIPPED_AUTOGRAD_FUNCTIONS` to ignore those duplicated named
Gelu that is not used by model run. This has limitations obviously for
example if two Gelus are both used in training.
This PR finds a way to construct a full qualified name.
`def _export_pt_1_10(g, n, *args, **kwargs):`
1. in exporter function, kwargs contains `name` and `module`, in the
above example:
`a.b.c.Gelu` --> name: `Gelu`, module: `a.b.c`
`d.e.func.<locals>.Gelu` --> name: `Gelu`, module: `d.e`
Using name and module is not enough to get a full qualified name, for
the second case, where `d.e` is the module path, then there is a
function called `func`, in this function, there is a local
auto.grad.Function named `Gelu`. (Many of our UT looks like this). We
can only get `d.e.Gelu`, but this is not the correct full qual name.
The reason for this: `kwargs[name]` or `n.name` only return the class's
name, not the class's full qual name. (be noted kwargs[module]` is
correct).
2. `n` is torch.Node, we can access `pyobj` to get the
torch.autograd.Function's apply method instance, then use `._self` to
get the torch.autograd.Function class. Then we can get the `module` and
`class`'s ful qual name, added together, we get the full qual name.
With the above change, we don't need use `kwargs[name]` and
`kwargs[module]` , and don't need check naming conflicting or
`ORTMODULE_SKIPPED_AUTOGRAD_FUNCTIONS` env var any more.
### Fix few bugs
1. symbolic shape infer, there is no None check before get length.
2. Rename PythonOp/PythonOpGrad's attribute `name` to `func_name`,
otherwise, when we use onnx.helper.make_node to create node, `name`
conflicts with node name.
3. Filter shape inference warnings for PythonOp for torch 2.0 or newer.
4. Close file descriptor for log suppression. Without the fix, two extra
fd is left after the log suppression exit its context.
Before enter log suppression (left), Before exit log suppression (right)

With the fix, no fd added after context exit.

### Motivation and Context
When we handle PyTorch models' inputs in different places (ORTModule or
others), it's common for us to flatten a structured data into a 1-D
tensor list (required by lib for example torch.onnx.export,
torch.autograd.Function.forward or ORT inference session), then do
subsequent work, then unflatten back to original hierarchy as returned
values.
DeepStage3 hooks support work also need such a lib to do similar things,
so I was proposing to extract this pair of APIs in training/utils/,
which can be more used more generally. Also a comprehensive set of test
data are used for testing unflatten/flatten in unit tests.
Let me know if you have any other suggestions.
### Refactor schema extraction and output unflattening
Move `_extract_schema` and `unflatten_user_output` in
`orttraining/orttraining/python/training/ortmodule/_io.py` . to
`extract_data_and_schema` and `unflatten_data_using_schema` in
`orttraining/orttraining/python/training/utils/torch_io_helper.py` as
shared libs, which can be used later by other features (deepspeed stage
3 hook rewrite).
While there are still a few duplicated logic handling flatten with
different task by recursively loop the data struct, will change them
step by step in case of heavy review efforts.
### Save optimized pre_grad graph once it's ready
`graph_builder.build()` did two things for training: 1. optimized
forward graph, e.g. pre_grad graph optimization. 2. build gradient
graph.
Originally after `graph_builder.build()` completed, pre_graph graph is
saved. While if pre_grad graph optimization completed, but fail during
gradient graph build, we still cannot get pre_grad graph to investigate.
This PR made the change once pre_grad graph is ready, we save it (if
save_model is enabled) in C++ backend.
### Description
<!-- Describe your changes. -->
This PR adds support to cache the exported training/evaluation ONNX
model in `ORTModule`. On future runs, instead of exporting the model
again, we can pick up the model from a location on disc and run
`ORTModule` training/evaluation.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
ORT Training DRI Contribution
---------
Co-authored-by: root <root@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Prathik Rao <prathikrao@microsoft.com@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Baiju Meswani <bmeswani@microsoft.com>
Co-authored-by: pengwa <pengwa@microsoft.com>
### ORTModule log clean up
ORTModule log level - WARNING(Default) is for end users; INFO and
VERBOSE is for internal ORT training developers.
Few issues:
1. ONNX export will output lots of WARNING error message like "The shape
inference of
com.microsoft::SoftmaxCrossEntropyLossInternal/ATen/PythonOp type is
missing", which is useless for us or end users.

3. ORT also print some information like
""CleanUnusedInitializersAndNodeArgs] Removing
initializer","ReverseBFSWithStopGradient] Skip building gradient for",
which is also useless for us or end users most of the time.

5. Different ranks output logs and making ORT developers or end users
feels there are too many logs but usually not useful until we need
investigate.
Few improvements for the issues:
1. For ONNX export logs, there are two kinds of logs: a. export verbose
log; b. other logs printed by torch C++ backend. So this PR make
following change:
# VERBOSE -> FULL export verbose log + FULL torch other logs from stdout
and stderr (C++ backend)
# INFO -> FULL export verbose log + FILTERED torch other logs from
stdout and stderr (C++ backend)
# WARNING/ERROR -> [Rank 0] NO export verbose log + FILTERED torch other
logs from stdout and stderr (C++ backend)
e.g. for verbose level, print all logs as usually; for info level, print
verbose export log, and filtered logs from torch C++ backend (removing
messages like this "The shape inference of
com.microsoft::SoftmaxCrossEntropyLossInternal/ATen/PythonOp type is
missing") . For higher level, only log the info on rank 0.
2. For ORT gradient graph build and session creation, also suppress the
message and filtered out the message when log level >=INFO.
3. log level > INFO, then only logs on rank 0 is logged, to have a
cleaner user experience
This is the log for a BLOOM model training after the change: there are
limited of warnings.

### Description
Disable two PERF* rules in ruff to allow better readability. Rational
commented inline. This change also removes the unused noqa directives
because of the rule change.
### Motivation and Context
Readability
Sometimes, ONNX exporter generates rank- or shape-dependent sub-graphs.
Thus, error could occur when running the ONNX model with different
inputs. This PR
([78e736d](78e736d857))
addresses this problem by
- if needed, exporting multiple ONNX models with different inputs for
the same GraphModule.
- implementing a naive mechanism to determine of existing ONNX models
(and the associated InferenceSession) can be reused.
On the other hand, in the second commit
[b5a9b5f](b5a9b5f849),
this PR also enables dynamic shapes in DORT by
- passing dynamic_shapes = True to exporter (see how
DEFAULT_DYNAMIC_BACKEND is created)
- calling torch._dynamo.optimize(dynamic_ort_aot, dynamic=True) (see how
dynamic_ort_aot is created).
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at
bottom):
* __->__ #16789
Bump ruff to 0.0.278 and fix new lint errors. I added noqa to all
existing RUF012 errors which requires mutable class variables to be
annotated with `ClassVar`, as well as all PERF issues.
Signed-off-by: Justin Chu <justinchu@microsoft.com>
### Description
torch.norm is deprecated as mentioned in issue #16751. This PR replaces
the call to torch.norm by the options suggested by torch documentation.
There are several global configs used by DORT.
```py
DEFAULT_ONNX_EXPORTER_OPTIONS = torch.onnx._internal.exporter.ResolvedExportOptions(
torch.onnx._internal.exporter.ExportOptions()
)
# TODO(wechi): This line must generate result identical to the call of
# _create_onnx_supports_op_overload_table(...) inside
# create_onnx_friendly_decomposition_table(...) in
# torch/onnx/_internal/fx/decomposition_table.py.
_SUPPORT_DICT = torch.onnx._internal.fx.decomposition_table._create_onnx_supports_op_overload_table(
DEFAULT_ONNX_EXPORTER_OPTIONS.onnx_registry
) # type: ignore
_EXTRA_SUPPORT_DICT: Dict[str, Any] = {
"getattr": None,
"_operator.getitem": None,
}
DORT_DECOMPOSITION_TABLE = DEFAULT_ONNX_EXPORTER_OPTIONS.decomposition_table
```
We can see all but `_EXTRA_SUPPORT_DICT` are extracted from deduced from
ONNX exporter's options. As there are many ways to configure ONNX
exporter's options, we decided to move these variables to `OrtBackend`'s
`__init__` so that the construction of `OrtBackend` becomes more
flexible (especially for enabling dynamic shape or not).
DORT only select devices from inputs arguments' (type: torch.Tensor).
However, it errors out when a graph doesn't have any inputs (e.g., a
single aten::full graph). This PR address this problem by changing the
EP selection to
- First, inspect graph inputs. If there are some valid devices, use them
plus a default one (`OrtBackend.ep: str`).
- Otherwise, inspect graph outputs carried by `torch.fx.GraphModule` and
use all valid devices plus the default `OrtBackend.ep`.
- When both (1) and (2) fail, it uses the default EP specified by
`OrtBackend.ep`.
### Use autograd_inlining for model export
From some versions of PyTorch, there is an issue related to custom
autograd.Function inlining, even though we register custom export
function for the autograd.Function (e.g. when custom autograd function
is enabled).
As an options, PyTorch exporter adds a new flag during export, we can
disable the inline. https://github.com/pytorch/pytorch/pull/104067
Currently the PyTorch change is in nightly built, this PR dynamically
check the torch.onnx.export's signature and decide to use the
`autograd_inlining` when it exists.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Log ORTModule initialization overhead
When profiling some model for example
```
torchrun --nproc_per_node=1 examples/onnxruntime/training/language-modeling/run_mlm.py --model_name_or_path microsoft/deberta-v3-large --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --num_train_epochs 10 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --do_train --overwrite_output_dir --output_dir ./outputs/ --seed 1137 --fp16 --report_to none --optim adamw_ort_fused --max_steps 200 --logging_steps 1 --use_module_with_loss
{'train_runtime': 303.8711, 'train_samples_per_second': 0.658, 'train_steps_per_second': 0.658, 'train_loss': 6.569518616199494, 'epoch': 0.09}
100%|200/200 [05:03<00:00, 1.52s/it]
***** train metrics *****
epoch = 0.09
train_loss = 6.5695
train_runtime = 0:05:03.87
train_samples = 2223
train_samples_per_second = 0.658
train_steps_per_second = 0.658
```
The end to end time is 303s (train_runtime=0:05:03.87), but the
ORTModule first step initialization (including export, graph build, etc)
takes about 255s, so when we compare the end to end time for a baseline
ORT with an improved version of ORT, there is no perf gains, since the
x% gains over (303-255) is diluted out among the overall 303s. This is
misleading!
So this PR outputs the ORTModule initialization overhead in the output,
then we can manually compute the real compte time and get the perf
gains.
If the log level is >= WARNING, then only the total end to end time +
export time is logged, otherwise, more details of break down is logged:


The ONNX exporter in DORT have been moved to PyTorch as a formal
feature. We therefore switch to consume the exporter from PyTorch
instead of maintaining two duplicates.
### Manage ORTModule options
Move all env vars that used for feature ON/OFF into runtime options for
consistent managements.
Be noted: the features' switch are assigned in 2 phases: default values,
overwritten by env vars (if specified by users). So env vars take the
highest priority when all 2 phases both given value explicitly for one
feature.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
DORT support for custom ops
### Motivation and Context
Custom ops registered via custom_ops shared_library cannot be run using
DORT atm. This PR enables it using:
1. registering custom_ops supported in DORT
2. plumbing down session_options from OrtBackend when creating the
InferenceSession, that were used to register the custom_ops shared
library using
`session_options.register_custom_ops_library(shared_library)`
Fix#16355. The root cause change in PyTorch is
[#103302](https://github.com/pytorch/pytorch/pull/103302), which seem
blocking calling make_fx inside a dynamo backend.
Changes:
1. Move decomposition to `register_backend.py`, so we don't have to call
`make_fx` inside DORT, which triggers a bunch of new exceptions.
2. Remove shape inference based on FakeTensorProp since the FX graph
received from dynamo contains all shapes now.
3. Fix a macro bug so that DORT can build without CUDA.
Before (3),
```
#if defined(USE_CUDA) || defined(USE_ROCM)
virtual PhiloxGenerator& PhiloxGenerator__Default() = 0;
#ifdef ENABLE_TRAINING_TORCH_INTEROP
...
#endif
#endif
```
After (3),
```
#if defined(USE_CUDA) || defined(USE_ROCM)
virtual PhiloxGenerator& PhiloxGenerator__Default() = 0;
#endif
#ifdef ENABLE_TRAINING_TORCH_INTEROP
...
#endif
```
The later one looks better since the `ENABLE_TRAINING_TORCH_INTEROP` is
for Python bridge code, not for random-number-generating kernels
`PhiloxGenerator`.
### Description
This PR is to refactor ExecutionProvider API for memory management,
which is to move allocators from EP level to SessionState level and
indexed by OrtDevice
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This PR is to refactor ExecutionProvider API for memory management,
which is to move allocators from EP level to SessionState level and
indexed by OrtDevice. By this change, EP level will shift the burden of
maintaining allocators, which will be user friendly for EP developers
---------
Co-authored-by: Lei Cao <leca@microsoft.com@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
### Description
Optimize compute graph by eliminating padding in embedding.
### Motivation and Context
The computation for padding in nodes after embedding is unnecessary and
waste computation resources.
This pr just add an Optimizer of PaddingElimination to check and
eliminate the padding after embedding automatically by modifying the
graph.
### Implementation:
1. Find and check embedding node in graph.
2. Iterate the subgraph afterward the embedding node and record all the
input nodes and output nodes to this subgraph.
3. Insert 'Reshape + ShrunkenGather' to flatten each input node shape
from [batch_size, seqlen, ...] to [valid_token_without_padding, ...],
and insert 'GatherGrad + Reshape' to unflatten each output node shape
from [valid_token_without_padding, ...] to [batch_size, seqlen, ...]
---------
Co-authored-by: mindest <linminuser@gmail.com>
### Enhance StatisticsSubscriber
There are few improvements for `StatisticsSubscriber`:
- Reduce peak memory impact for tensors (having many many many elements,
consuming too much GPU memory, causing original recipe run failed with
OOM), by split the statistics into two phases (split into buckets, and
merge result across buckets).
- Allow dump intermediate tensors. Originally only nn.Module forward()'s
return value are dumped, there are requirements we want to inspect some
specific intermediate tensor in the forward() function, now we support
it.
- Add documents for collecting dumps on multiple ranks
Docs link on this branch for better view:
https://github.com/microsoft/onnxruntime/blob/pengwa/conv_tool_v2/docs/ORTModule_Convergence_Notes.md
---------
Co-authored-by: mindest <30493312+mindest@users.noreply.github.com>
### Description
<!-- Describe your changes. -->
Detect fake tensor mode if it has already been created. Follows this
example in pytorch:
86c7652503/torch/_inductor/compile_fx.py (L280)
### Motivation and Context
As of torch nightly 6/2/23, when trying to run a torch dynamo graph on
the ORT backend, we observe
```
E torch._dynamo.exc.BackendCompilerFailed: backend='compiler_fn' raised:
E AssertionError: Mixing fake modes NYI
E
E
E You can suppress this exception and fall back to eager by setting:
E import torch._dynamo
E torch._dynamo.config.suppress_errors = True
```
The issue is that `ort_backend.py` creates a new fake tensor mode even
though one has already been created by torch.
### Consolidate ORTModule logging
There are few improvements for ORTModule loggings:
- All ORTModule logging are used logger that is initialized in
`ortmodule.py`.
- Manage all export logs same way, e.g. use `
_logger.suppress_os_stream_output(log_level=self._debug_options.logging.log_level)`
to control exporting related logs suppressing or not. If any warning or
errors suppressed, `self._warning_log_detected_during_export` will be
set to True, then when we log ORTModule feature matrix, we will also
told users there are logs suppressed.
- Downgrade some warnings. We had some warnings for years, and looks
many models have them by default, no action we actually can take, so
downgrade them to make user logging cleaner.
- PyTorch export requires update of custom export function signature
changes, otherwise, _symbolic_context_handler complains with warnings,
so update custom export function adaption for version >=1.13 PyTorch.
- Add ORTModule feature matrix summary, **this is supposed to be only
places users see our logs by default** (unless they use INFO or
VERBOSE). Features ON/OFF states are shown clearly to them in case they
want to try some features in OFF states. This logs only shows up in rank
0 (if there are multiple rank), the intention is we want user to see a
useful and clean output from ORTModule by default. The outputs shown as
below:


- `reinitialize_ortmodule` in util.py is only used by ortmodule.py,
moving it into ortmodule.py, then utils takes no dependency on
`orttraining/orttraining/python/training/ortmodule/_custom_op_symbolic_registry.py`,
then `_custom_op_symbolic_registry.py` can call functions defined in
utils.py (without recursively include).
### Description
The PR implements FloatE4M3FN, FloatE5M2, FloatE4MEFNUZ, FloatE5M2FNUZ
as described in PR https://github.com/onnx/onnx/pull/4805. It uses CUDA
API to cast float/half to float8 if CUDA>=11.8, a custom implementation
if CUDA<11.8.
* It implements, Cast, QuantizeLinear, DequantizeLinear for all types on
CPU, only for types FloatE4M3FN, FloatE5M2 on CUDA.
* It extends the supported types for control flow operator, Shape,
Reshape, Identity, If, Loop, Scan, Reshape
* It implements Equal(19).
* Cast, QuantizeLinear, DequantizeLinear operators now support a
parameter `saturate` only valid for float 8 types. It is true by
default. In that case, any value out of range is converted into the
maximum float 8 value. If false, it is infinite.
* QuantizeLinear, DequantizeLinear now supports multiple scales on CUDA
(and ROCm by extension), scale = 1D tensor with one scale per channel
### Motivation and Context
Supports latest onnx version.
Fixes
[AB#15395](https://aiinfra.visualstudio.com/6a833879-cd9b-44a4-a9de-adc2d818f13c/_workitems/edit/15395)
---------
Co-authored-by: Xavier Dupre <xadupre@microsoft.com@orttrainingdev8.d32nl1ml4oruzj4qz3bqlggovf.px.internal.cloudapp.net>
Co-authored-by: Randy Shuai <rashuai@microsoft.com>
Co-authored-by: Edward Chen <18449977+edgchen1@users.noreply.github.com>
Co-authored-by: Scott McKay <Scott.McKay@microsoft.com>
### Type hint for ORTModule
Add Type hint for ORTModule
Refine comments.
The reason of removing theinterface execution_session_run_forward from
`orttraining/orttraining/python/training/ortmodule/_graph_execution_manager.py`:
PR
cc275e7529 (diff-497e18dc8878818205b81fd80f85942548d8aa15d0f1204ce3e3d9795e3dd195)
and some commit before it breaks the function interface contracts
between parent calss _graph_execution_manager.py and its children
_training_manager.py and _inference_manager.py. So there is no need to
have this interface.
### Other EE work opportunities
1. Use logger correctly.
2. Remove few duplication logic parsing input/output recursively.
3. Clean up environment variable usage.
### Enable conditional optimization on inputs
Label sparsity based optimization can be enabled depending on the input
inspection result.
So this PR introduce a conditional optimization path for ORTModule,
where we automatically detect data sparsity from label or embedding, and
enable the graph optimization accordingly without any user interaction.
This feature had a new requirement of delaying passing pre_grad graph
transformation config to OrtModuleGraphBuilder, from `Initialize` phase
to its `Build` phase. Because once after `_initialize_graph_builder` we
can detect the input sparsity, and make a decision to enable the
label/embed sparisty based graph optimizations.
Add UT cases for label/embed input runtime inspector.
### Description
<!-- Describe your changes. -->
support the latest deepspeed 0.9.1 for the next release
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This will avoid the warn message `Skip modifying optimizer because of
unsupported DeepSpeed version`
---------
Co-authored-by: ruiren <ruiren@microsoft.com>
### Description
<!-- Describe your changes. -->
### Error
```
RuntimeError: There was an error while exporting the PyTorch model to ONNX:-
Traceback (most recent call last):
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/onnxruntime/training/ortmodule/_utils.py", line 254, in get_exception_as_string
raise exception
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/onnxruntime/training/ortmodule/_graph_execution_manager.py", line 385, in _get_exported_model
torch.onnx.export(self._flattened_module,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/__init__.py", line 305, in export
return utils.export(model, args, f, export_params, verbose, training,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 118, in export
_export(model, args, f, export_params, verbose, training, input_names, output_names,
File "/opt/conda/envs/ptca/lib/python3.8/site-packages/torch/onnx/utils.py", line 743, in _export
proto, export_map, val_use_external_data_format = graph._export_onnx(
RuntimeError: ONNX export failed: Couldn't export Python operator XDropout
```
The error leads to Out of Memory issue, because the log.txt file is **26
GB**.
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
The root cause is that in each `_forward`
```
if log_level <= _logger.LogLevel.WARNING and not self._raised_ORTModuleONNXModelException:
warnings.warn(
(
f"Fallback to PyTorch due to exception {type(self._exception)} was triggered. "
"Report this issue with a minimal repro at https://www.github.com/microsoft/onnxruntime. "
f"See details below:\n\n{_utils.get_exception_as_string(self._exception)}"
),
UserWarning,
)
```
above code will be called and log the `exception` through
`get_exception_as_string`,
In my training case, this will lead to 40 k times of `Traceback` stdout
and 110 millions lines of `onnx graph` output and run into OOM.
### Validation
After above fixes, the log.txt file will only be **2.4 MB**.
---------
Co-authored-by: ruiren <ruiren@microsoft.com>
### Description
Run clang-format in CI. Formatted all c/c++, objective-c/c++ files.
Excluded
```
'onnxruntime/core/mlas/**',
'onnxruntime/contrib_ops/cuda/bert/tensorrt_fused_multihead_attention/**',
```
because they contain assembly or is data heavy
### Motivation and Context
Coding style consistency
### Description
Bump ruff version in CI and fixed new lint errors.
- This change enables the flake8-implicit-str-concat rules which helps
detect unintended string concatenations:
https://beta.ruff.rs/docs/rules/#flake8-implicit-str-concat-isc
- Update gitignore to include common python files that we want to
exclude.
### Motivation and Context
Code quality
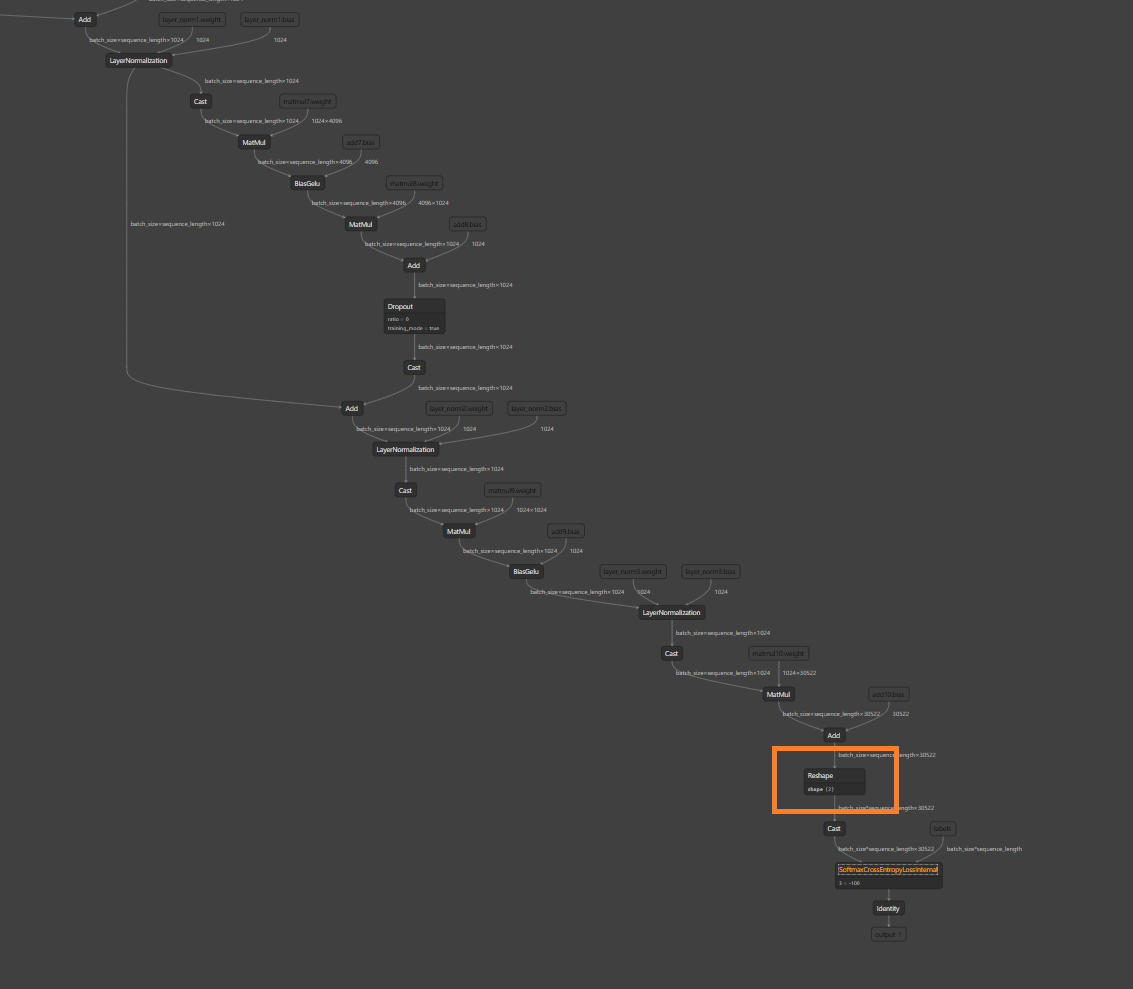
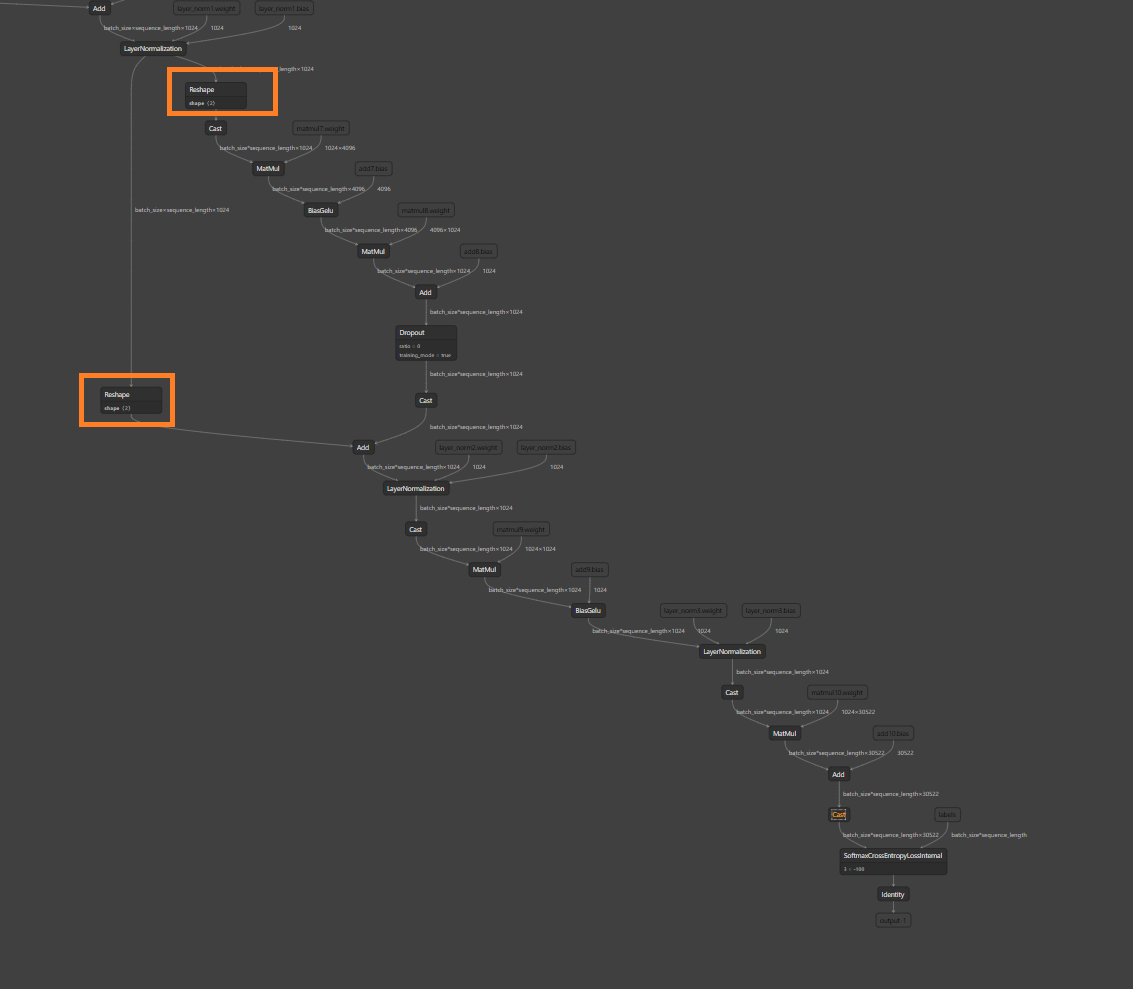
### Optimize SCE loss compute
Compute optimization based on label data sparsity:
- Insert ShrunkenGather before SCELoss node, to filter out invalid
labels for compute.
- Support ShrunkenGather upstream.
- Added test for the above.
- Added flag to enable label sparsity optimization with env var, by
default disabled now. Will enable after comprehensive benchmarking
later.
- Extract common logic into test_optimizer_utils.h/cc from
core/optimizer/compute_optimzier_test.cc, then the common functions can
be shared by both core/optimizer/compute_optimzier_test.cc and
orttraining/core/optimizer/compute_optimzier_test.cc
- Extract common logic into shared_utils.h/cc: `GetONNXOpSetVersion` and
`Create1DInitializerFromVector`
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
### Description
<!-- Describe your changes. -->
Update the support deepspeed to 0.8.3 as it's the latest version
### Motivation and Context
<!-- - Why is this change required? What problem does it solve?
- If it fixes an open issue, please link to the issue here. -->
This will fix the error of `Skip modifying optimizer because of
unsupported DeepSpeed version`
Co-authored-by: ruiren <ruiren@microsoft.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}